L'équipe de recherche du Computing Innovation Institute de l'Université du Zhejiang a réalisé une percée en résolvant le problème de la capacité insuffisante des grands modèles de langage à traiter des données tabulaires et a lancé un nouveau modèle TableGPT2. Grâce à son encodeur de table unique, TableGPT2 peut traiter efficacement diverses données de table, apportant des changements révolutionnaires aux applications basées sur les données telles que la business intelligence (BI). L'éditeur de Downcodes expliquera en détail l'innovation et l'orientation future du développement de TableGPT2.
L’essor des grands modèles linguistiques (LLM) a apporté des changements révolutionnaires aux applications d’intelligence artificielle. Cependant, ils présentent des lacunes évidentes dans le traitement des données tabulaires. Pour résoudre ce problème, une équipe de recherche du Computing Innovation Institute de l'Université du Zhejiang a lancé un nouveau modèle appelé TableGPT2, capable d'intégrer et de traiter des données tabulaires directement et efficacement, ouvrant ainsi de nouvelles voies pour la business intelligence (BI) et d'autres méthodes basées sur les données. applications.
L'innovation principale de TableGPT2 réside dans son encodeur de table unique, spécialement conçu pour capturer les informations structurelles et les informations sur le contenu des cellules de la table, améliorant ainsi la capacité du modèle à gérer les requêtes floues, les noms de colonnes manquants et les tables irrégulières qui sont courantes dans la réalité. -applications mondiales. TableGPT2 est basé sur l'architecture Qwen2.5 et a fait l'objet d'un pré-entraînement et d'un réglage précis à grande échelle, impliquant plus de 593 800 tables et 2,36 millions de tuples de sortie de table de requête de haute qualité, ce qui représente une échelle sans précédent de données liées aux tables. données dans des recherches antérieures.
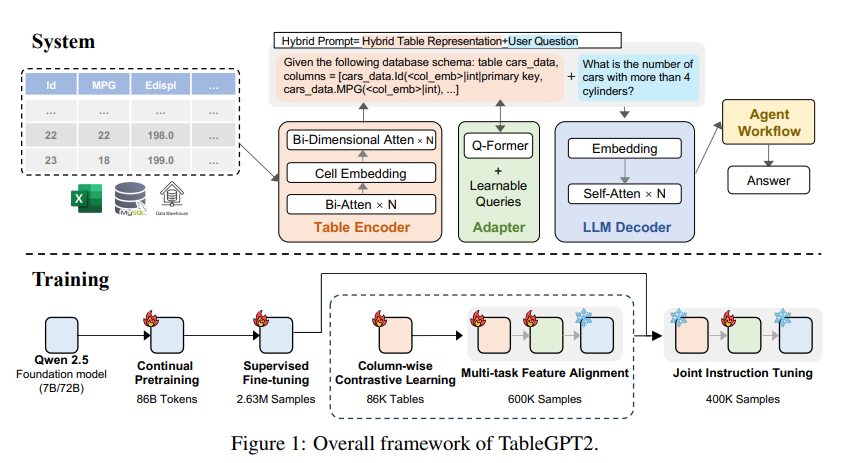
Afin d'améliorer les capacités de codage et de raisonnement de TableGPT2, les chercheurs ont mené une pré-formation continue (CPT), dans laquelle 80 % des données sont soigneusement annotées en code pour garantir qu'elles disposent de solides capacités de codage. En outre, ils ont également collecté une grande quantité de données d'inférence et de manuels contenant des connaissances spécifiques à un domaine pour améliorer les capacités d'inférence du modèle. Les données CPT finales contiennent 86 milliards de jetons strictement filtrés, ce qui fournit les capacités d'encodage et de raisonnement nécessaires à TableGPT2 pour gérer des tâches BI complexes et d'autres tâches connexes.
Pour remédier aux limites de TableGPT2 en matière d'adaptation à des tâches et des scénarios BI spécifiques, les chercheurs ont effectué un réglage fin supervisé (SFT). Ils ont construit un ensemble de données couvrant une variété de scénarios critiques et réels, notamment plusieurs séries de conversations, des raisonnements complexes, l'utilisation d'outils et des requêtes hautement orientées métier. L'ensemble de données combine une annotation manuelle avec un processus d'annotation automatisé piloté par des experts pour garantir la qualité et la pertinence des données. Le processus SFT, utilisant un total de 2,36 millions d'échantillons, a affiné davantage le modèle pour répondre aux besoins spécifiques de la BI et d'autres environnements impliquant des tables.
TableGPT2 introduit également de manière innovante un encodeur de table sémantique qui prend la table entière en entrée et génère un ensemble compact de vecteurs d'intégration pour chaque colonne. Cette architecture est personnalisée pour les propriétés uniques des données tabulaires, capturant efficacement les relations entre les lignes et les colonnes grâce à un mécanisme d'attention bidirectionnel et un processus d'extraction de caractéristiques hiérarchique. De plus, une méthode d'apprentissage contrastif en colonnes est adoptée pour encourager le modèle à apprendre des représentations sémantiques tabulaires significatives et sensibles à la structure.
Afin d'intégrer de manière transparente TableGPT2 aux outils d'analyse de données au niveau de l'entreprise, les chercheurs ont également conçu un cadre d'exécution de flux de travail d'agent. Le cadre se compose de trois composants principaux : l'ingénierie des astuces d'exécution, le bac à sable de code sécurisé et le module d'évaluation de l'agent, qui, ensemble, améliorent les capacités et la fiabilité de l'agent. Les workflows prennent en charge des tâches complexes d'analyse de données via des étapes modulaires (normalisation des entrées, exécution de l'agent et appel d'outils) qui fonctionnent ensemble pour gérer et surveiller les performances de l'agent. En intégrant Retrieval Augmented Generation (RAG) pour une récupération contextuelle efficace et un sandboxing de code pour une exécution sûre, le framework garantit que TableGPT2 fournit des informations précises et contextuelles sur les problèmes du monde réel.
Les chercheurs ont mené une évaluation approfondie de TableGPT2 sur une variété de benchmarks tabulaires et à usage général largement utilisés. Les résultats montrent que TableGPT2 excelle dans la compréhension, le traitement et le raisonnement des tableaux, avec une amélioration moyenne des performances de 35,20 % pour un modèle de 7 milliards de paramètres, 720. Les performances moyennes du modèle à 100 millions de paramètres ont augmenté de 49,32 %, tout en maintenant de solides performances générales. Pour une évaluation équitable, ils ont uniquement comparé TableGPT2 à des modèles open source neutres tels que Qwen et DeepSeek, garantissant des performances équilibrées et polyvalentes du modèle sur une variété de tâches sans surajuster aucun test de référence. Ils ont également introduit et publié partiellement un nouveau benchmark, RealTabBench, qui met l'accent sur les tables non conventionnelles, les champs anonymes et les requêtes complexes pour être plus cohérents avec les scénarios réels.
Bien que TableGPT2 atteigne des performances de pointe dans les expériences, des défis subsistent lors du déploiement de LLM dans des environnements BI réels. Les chercheurs ont noté que les futures orientations de recherche comprennent :
Codage spécifique au domaine : permet à LLM d'adapter rapidement les langages spécifiques à un domaine (DSL) ou le pseudocode spécifiques à l'entreprise pour mieux répondre aux besoins spécifiques de l'infrastructure de données de l'entreprise.
Conception multi-agent : découvrez comment intégrer efficacement plusieurs LLM dans un système unifié pour gérer la complexité des applications du monde réel.
Traitement polyvalent des tableaux : améliorez la capacité du modèle à gérer les tableaux irréguliers, tels que les cellules fusionnées et les structures incohérentes courantes dans Excel et Pages, afin de mieux gérer diverses formes de données tabulaires dans le monde réel.
Le lancement de TableGPT2 marque les progrès significatifs de LLM dans le traitement des données tabulaires, apportant de nouvelles possibilités pour la business intelligence et d'autres applications basées sur les données. Je pense qu'à mesure que la recherche continue de s'approfondir, TableGPT2 jouera à l'avenir un rôle de plus en plus important dans le domaine de l'analyse des données.
Adresse papier : https://arxiv.org/pdf/2411.02059v1
L'émergence de TableGPT2 a apporté une nouvelle aube dans le domaine de la business intelligence. Ses capacités efficaces de traitement des données de table et sa forte évolutivité indiquent que l'analyse des données sera plus intelligente et plus pratique à l'avenir. Nous espérons que TableGPT2 sera plus largement utilisé à l'avenir et apportera plus de valeur à tous les horizons.