L'équipe Emu3 de l'Institut de recherche Zhiyuan a publié le modèle multimodal révolutionnaire Emu3, qui renverse l'architecture de modèle multimodale traditionnelle, s'entraîne uniquement sur la base de la prochaine prédiction de jeton et atteint les performances SOTA dans les tâches de génération et de perception. L'équipe Emu3 tokenise intelligemment les images, le texte et les vidéos dans des espaces discrets et forme un modèle Transformer unique sur des séquences multimodales mixtes, réalisant ainsi l'unification des tâches multimodales sans s'appuyer sur des architectures de diffusion ou de combinaison, ce qui fournit plusieurs Le champ modal apporte de nouvelles percées.
L'équipe Emu3 de l'Institut de recherche Zhiyuan a publié un nouveau modèle multimodal Emu3. Ce modèle est formé uniquement sur la base de la prochaine prédiction de jeton, renversant le modèle de diffusion traditionnel et l'architecture du modèle de combinaison et obtenant des résultats dans les tâches de génération et de perception. -des performances de pointe.
La prédiction du prochain jeton a longtemps été considérée comme une voie prometteuse vers l’intelligence artificielle générale (AGI), mais elle a donné de mauvais résultats sur les tâches multimodales. Actuellement, le domaine multimodal est encore dominé par les modèles de diffusion (tels que Stable Diffusion) et les modèles de combinaison (tels que la combinaison de CLIP et LLM). L'équipe Emu3 tokenise les images, le texte et les vidéos dans des espaces discrets et entraîne un seul modèle Transformer à partir de zéro sur des séquences multimodales mixtes, unifiant ainsi les tâches multimodales sans s'appuyer sur des architectures de diffusion ou combinatoires.
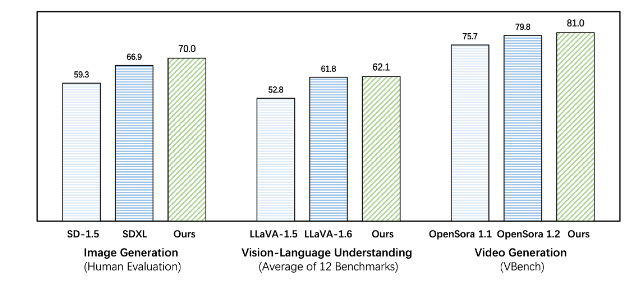
Emu3 surpasse les modèles spécifiques à des tâches existants sur les tâches de génération et de perception, dépassant même les modèles phares tels que SDXL et LLaVA-1.6. Emu3 est également capable de générer des vidéos haute fidélité en prédisant le prochain jeton d'une séquence vidéo. Contrairement à Sora, qui utilise un modèle de diffusion vidéo pour générer des vidéos à partir du bruit, Emu3 génère des vidéos de manière causale en prédisant le prochain jeton de la séquence vidéo. Le modèle peut simuler certains aspects des environnements, des personnes et des animaux du monde réel et prédire ce qui se passera ensuite compte tenu du contexte de la vidéo.
Emu3 simplifie la conception de modèles multimodaux complexes et se concentre sur les jetons, libérant ainsi un énorme potentiel de mise à l'échelle pendant la formation et l'inférence. Les résultats de la recherche montrent que la prédiction du prochain jeton est un moyen efficace de construire une intelligence multimodale générale au-delà du langage. Pour soutenir des recherches plus approfondies dans ce domaine, l'équipe Emu3 dispose de technologies et de modèles clés open source, notamment un puissant tokeniseur visuel capable de convertir des vidéos et des images en jetons discrets, qui n'était pas accessible au public auparavant.
Le succès d'Emu3 indique la direction du développement futur des modèles multimodaux et apporte un nouvel espoir pour la réalisation de l'AGI.
Adresse du projet : https://github.com/baaivision/Emu3
L'éditeur de downcodes résume : L'émergence du modèle Emu3 marque une nouvelle étape dans le domaine multimodal. Son architecture simple et ses performances puissantes fournissent de nouvelles idées et orientations pour les futures recherches en AGI. La stratégie open source favorise également le développement conjoint du monde universitaire et de l'industrie. Il vaut la peine d'attendre avec impatience d'autres percées à l'avenir !