Keterangan Visual
v1.0
Alat subtitle Teks Visual, Teks Visual adalah alat subtitle canggih yang baru diluncurkan yang dapat meningkatkan tampilan lebih banyak subtitle untuk rapat kerja pengguna dan membuat komunikasi kantor lebih nyaman. Pengguna yang membutuhkan dapat datang dan bergabung dengan kami.
Google mendemonstrasikan sistem, Teks Visual, di ACM CHI (Konferensi Faktor Manusia dalam Sistem Komputasi), konferensi teratas tentang interaksi manusia-komputer, memperkenalkan solusi visual baru dalam pertemuan jarak jauh yang dapat menghasilkan atau mengambil gambar dalam konteks percakapan untuk meningkatkan kinerja pihak lain. Pengetahuan tentang konsep yang kompleks atau asing.
Sistem Teks Visual didasarkan pada model bahasa berskala besar yang telah disempurnakan dan dapat secara proaktif merekomendasikan elemen visual yang relevan dalam percakapan kosakata terbuka, dan telah diintegrasikan ke dalam proyek sumber terbuka ARChat.
Dalam survei pengguna, peneliti mengundang 26 peserta di laboratorium dan 10 peserta di luar laboratorium untuk mengevaluasi sistem. Lebih dari 80% pengguna pada dasarnya setuju bahwa Teks Video dapat memberikan teks video dalam berbagai skenario yang berguna, bermakna , dan meningkatkan pengalaman komunikasi.
Sebelum pengembangan, para peneliti terlebih dahulu mengundang 10 peserta internal, termasuk insinyur perangkat lunak, peneliti, desainer UX, seniman visual, mahasiswa, dan praktisi lain dengan latar belakang teknis dan non-teknis, untuk mendiskusikan kebutuhan dan persyaratan khusus untuk layanan peningkatan visual real-time. mengharapkan.
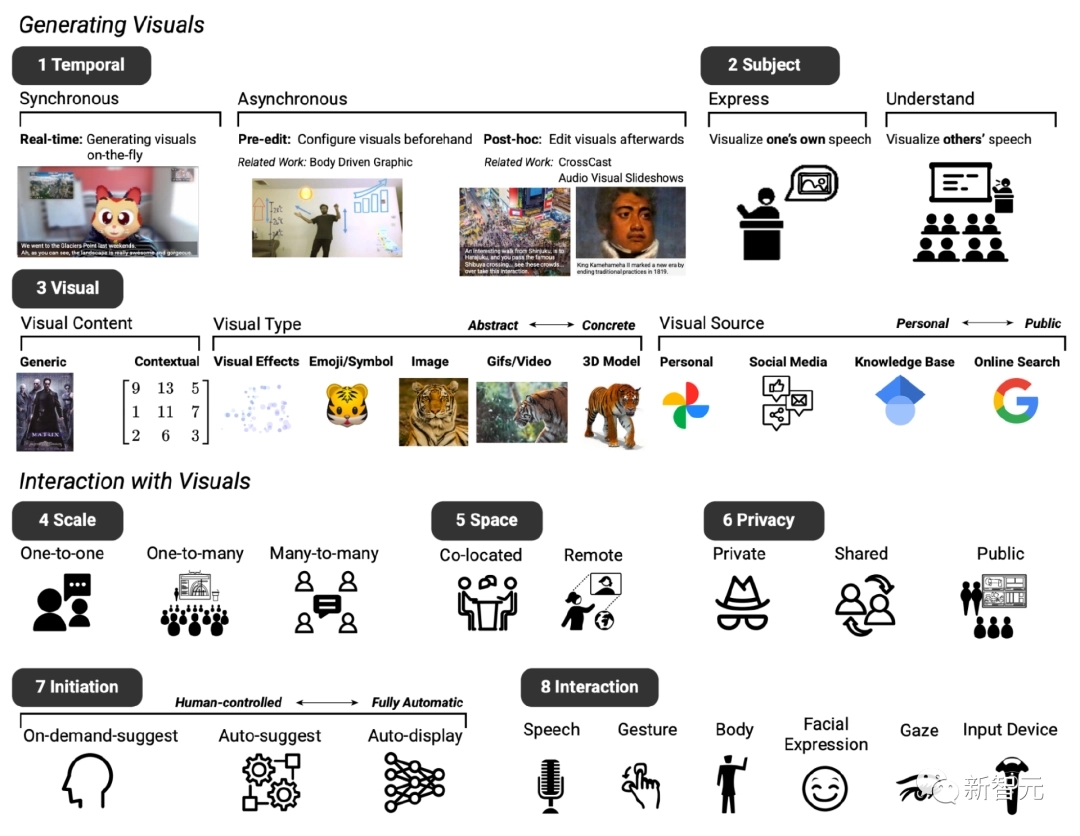
Setelah dua pertemuan, berdasarkan sistem teks-ke-gambar yang ada, desain dasar sistem prototipe yang diharapkan ditetapkan, terutama mencakup delapan dimensi (dilambangkan sebagai D1 hingga D8).
D1: Pengaturan waktu, sistem peningkatan visual dapat ditampilkan secara sinkron atau asinkron dengan dialog
D2: Topik, yang dapat digunakan untuk mengungkapkan dan memahami isi pembicaraan
D3: Visual, menggunakan berbagai konten visual, tipe visual, dan sumber visual
D4: Skala, peningkatan visual dapat bervariasi tergantung pada ukuran pertemuan
D5: Ruang, apakah konferensi video dilakukan di lokasi yang sama atau dalam pengaturan jarak jauh
D6: Privasi, faktor-faktor ini juga mempengaruhi apakah visual harus ditampilkan secara pribadi, dibagikan kepada peserta, atau tersedia untuk semua orang
D7: Keadaan awal, peserta juga mengidentifikasi berbagai cara yang mereka inginkan untuk berinteraksi dengan sistem ketika terlibat dalam percakapan, misalnya, berbagai tingkat “inisiatif” di mana pengguna dapat secara mandiri menentukan kapan sistem melakukan intervensi dalam obrolan D8: Interaksi, peserta membayangkan metode interaksi yang berbeda, seperti input menggunakan suara atau gerakan