Baca ini dalam bahasa Inggris
GLM-4-Voice adalah model ucapan ujung ke ujung yang diluncurkan oleh Zhipu AI. GLM-4-Voice dapat secara langsung memahami dan menghasilkan suara berbahasa Mandarin dan Inggris, melakukan percakapan suara secara real-time, dan dapat mengubah emosi, intonasi, kecepatan, dialek, dan atribut suara lainnya sesuai dengan instruksi pengguna.

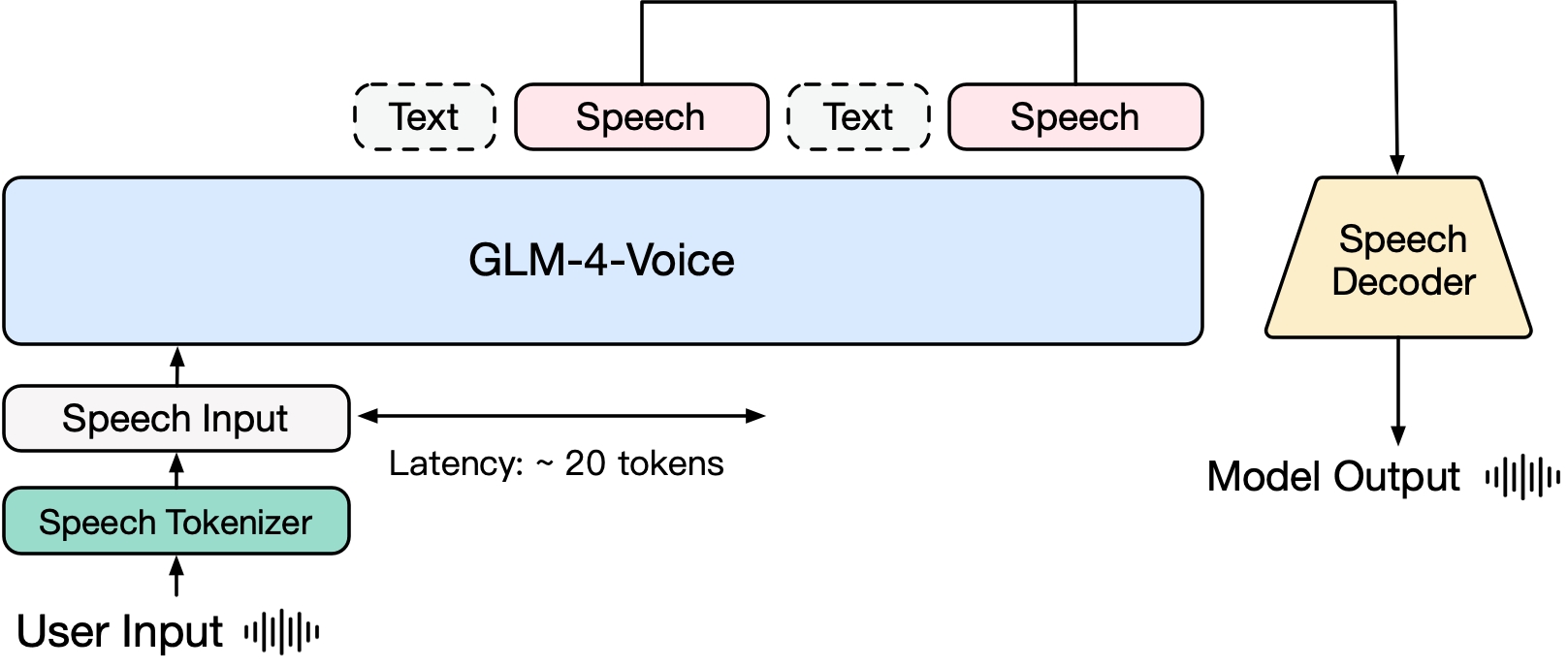
GLM-4-Voice terdiri dari tiga bagian:
GLM-4-Voice-Tokenizer: Dengan menambahkan Kuantisasi Vektor ke bagian Encoder Whisper dan pelatihan yang diawasi pada data ASR, input suara berkelanjutan diubah menjadi token diskrit. Rata-rata, audio hanya perlu diwakili oleh 12,5 token terpisah per detik.
GLM-4-Voice-Decoder: Dekoder ucapan yang mendukung penalaran streaming dan dilatih berdasarkan struktur model Pencocokan Aliran CosyVoice untuk mengubah token ucapan terpisah menjadi keluaran ucapan berkelanjutan. Setidaknya diperlukan 10 token suara untuk mulai menghasilkan, sehingga mengurangi penundaan percakapan ujung ke ujung.
GLM-4-Voice-9B: Berdasarkan GLM-4-9B, pra-pelatihan dan penyelarasan modalitas suara dilakukan untuk memahami dan menghasilkan token suara yang didiskritisasi.
Dalam hal pra-pelatihan, untuk mengatasi dua kesulitan yaitu IQ model dan ekspresi sintetik dalam mode bicara, kami memisahkan tugas Speech2Speech menjadi "membuat balasan teks berdasarkan audio pengguna" dan "mensintesis ucapan berdasarkan balasan teks dan ucapan pengguna" Dua tugas, dan dua tujuan pra-pelatihan dirancang untuk mensintesis data sisipan teks-ucapan berdasarkan data teks pra-pelatihan dan data audio tanpa pengawasan untuk beradaptasi dengan dua bentuk tugas ini. Berdasarkan model dasar GLM-4-9B, GLM-4-Voice-9B telah dilatih sebelumnya dengan jutaan jam audio dan ratusan miliar token data sisipan teks audio, serta memiliki pemahaman dan pemodelan audio yang kuat . kemampuan.
Dalam hal penyelarasan, untuk mendukung dialog suara berkualitas tinggi, kami merancang arsitektur pemikiran streaming: sesuai dengan suara pengguna, GLM-4-Voice dapat mengeluarkan konten secara bergantian dalam dua mode: teks dan suara dalam format streaming mode suara diwakili oleh Teks digunakan sebagai referensi untuk memastikan kualitas tinggi dari konten balasan, dan perubahan suara yang sesuai dilakukan sesuai dengan kebutuhan perintah suara pengguna. Ia masih memiliki kemampuan untuk memodelkan ujung ke ujung sambil mempertahankan IQ model bahasa paling tinggi, dan pada saat yang sama memiliki latensi rendah. Model tersebut hanya perlu mengeluarkan minimal 20 token untuk mensintesis ucapan.
Laporan teknis yang lebih rinci akan dirilis nanti.
| Model | Jenis | Unduh |
|---|---|---|
| GLM-4-Tokenizer Suara | Tokenizer Ucapan | ? |
| GLM-4-Suara-9B | Model Obrolan | ? |
| GLM-4-Dekoder Suara | Dekoder Ucapan | ? |
Kami menyediakan Web Demo yang bisa langsung dimulai. Pengguna dapat memasukkan suara atau teks, dan model akan memberikan respons suara dan teks.

Pertama unduh repositori
git clone --recurse-submodules https://github.com/THUDM/GLM-4-Voicecd GLM-4-Voice
Kemudian instal dependensinya. Anda juga dapat menggunakan gambar zhipuai/glm-4-voice:0.1 yang kami sediakan untuk melewati langkah ini.
instalasi pip -r persyaratan.txt
Karena model Decoder tidak mendukung inisialisasi melalui transformers , pos pemeriksaan perlu diunduh secara terpisah.
# unduh model git, pastikan Anda telah menginstal git-lfsgit lfs install git clone https://huggingface.co/THUDM/glm-4-voice-decoder
Mulai layanan model
python model_server.py --host localhost --model-path THUDM/glm-4-voice-9b --port 10000 --dtype bfloat16 --device cuda:0
Jika Anda perlu mem-boot dengan presisi Int4, jalankan
python model_server.py --host localhost --model-path THUDM/glm-4-voice-9b --port 10000 --dtype int4 --device cuda:0
Perintah ini secara otomatis akan mengunduh glm-4-voice-9b . Jika kondisi jaringan kurang baik, Anda juga dapat mengunduh secara manual dan menentukan jalur lokal melalui --model-path .
Mulai layanan web
python web_demo.py --tokenizer-path THUDM/glm-4-voice-tokenizer --model-path THUDM/glm-4-voice-9b --flow-path ./glm-4-voice-decoder
Anda dapat mengakses demo web di http://127.0.0.1:8888.
Perintah ini secara otomatis mengunduh glm-4-voice-tokenizer dan glm-4-voice-9b . Harap dicatat bahwa glm-4-voice-decoder perlu diunduh secara manual.
Jika kondisi jaringan kurang baik, Anda dapat mengunduh ketiga model ini secara manual dan kemudian menentukan jalur lokal melalui --tokenizer-path , --flow-path dan --model-path .
Pemutaran audio streaming Gradio tidak stabil. Kualitas audio akan lebih tinggi bila diklik di kotak dialog setelah pembuatan selesai.
Kami memberikan beberapa contoh percakapan GLM-4-Voice, antara lain mengendalikan emosi, mengubah kecepatan bicara, menghasilkan dialek, dll.
Bimbing saya untuk bersantai dengan suara lembut
Komentari pertandingan sepak bola dengan suara gembira
Ceritakan kisah hantu dengan suara sedih
Perkenalkan betapa dinginnya musim dingin dalam dialek Timur Laut
Ucapkan "Makan buah anggur tanpa mengeluarkan kulit anggur" dalam dialek Chongqing
Ucapkan twister lidah dalam dialek Beijing
berbicara lebih cepat
lebih cepat
Bagian dari kode untuk proyek ini berasal dari:
Suara Nyaman
transformator
GLM-4
Penggunaan bobot model GLM-4 harus mengikuti protokol model.
Kode repositori open source ini mengikuti protokol Apache 2.0.