bitnet.cpp adalah kerangka inferensi resmi untuk LLM 1-bit (misalnya, BitNet b1.58). Ia menawarkan serangkaian kernel yang dioptimalkan, yang mendukung inferensi model 1,58-bit yang cepat dan lossless pada CPU (dengan dukungan NPU dan GPU berikutnya).
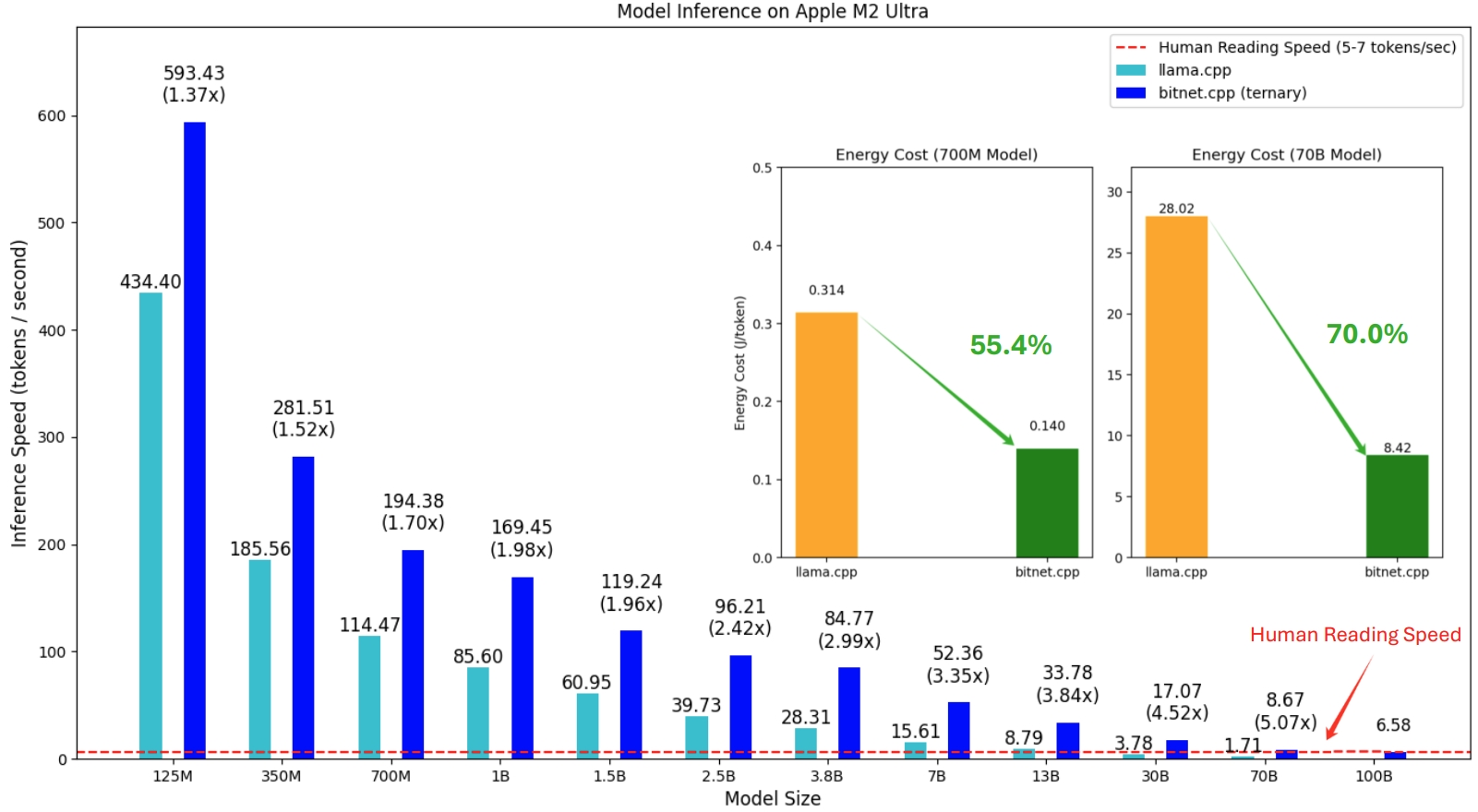
Rilis pertama bitnet.cpp adalah untuk mendukung inferensi pada CPU. bitnet.cpp mencapai peningkatan kecepatan 1,37x hingga 5,07x pada CPU ARM, dengan model yang lebih besar mengalami peningkatan kinerja yang lebih besar. Selain itu, hal ini mengurangi konsumsi energi sebesar 55,4% hingga 70,0% , sehingga semakin meningkatkan efisiensi secara keseluruhan. Pada CPU x86, peningkatan kecepatan berkisar antara 2,37x hingga 6,17x dengan pengurangan energi antara 71,9% hingga 82,2% . Selain itu, bitnet.cpp dapat menjalankan model 100B BitNet b1.58 pada satu CPU, mencapai kecepatan yang sebanding dengan pembacaan manusia (5-7 token per detik), secara signifikan meningkatkan potensi untuk menjalankan LLM pada perangkat lokal. Silakan merujuk ke laporan teknis untuk lebih jelasnya.


Model yang diuji adalah pengaturan dummy yang digunakan dalam konteks penelitian untuk menunjukkan kinerja inferensi bitnet.cpp.
Demo bitnet.cpp yang menjalankan model BitNet b1.58 3B di Apple M2:
21/10/2024 Infra AI 1-bit: Bagian 1.1, Inferensi BitNet b1.58 yang Cepat dan Tanpa Rugi pada CPU
17/10/2024 bitnet.cpp 1.0 dirilis.
21/03/2024 Era-1-bit-LLM__Training_Tips_Code_FAQ
27/02/2024 Era LLM 1-bit: Semua Model Bahasa Besar dalam 1,58 Bit
17/10/2023 BitNet: Menskalakan Transformer 1-bit untuk Model Bahasa Besar
Proyek ini didasarkan pada kerangka llama.cpp. Kami ingin mengucapkan terima kasih kepada semua penulis atas kontribusi mereka kepada komunitas sumber terbuka. Selain itu, kernel bitnet.cpp dibangun di atas metodologi Tabel Pencarian yang dirintis di T-MAC. Untuk inferensi LLM bit rendah umum di luar model terner, kami merekomendasikan penggunaan T-MAC.
❗️ Kami menggunakan LLM 1-bit yang tersedia di Hugging Face untuk mendemonstrasikan kemampuan inferensi bitnet.cpp. Model ini tidak dilatih atau dirilis oleh Microsoft. Kami berharap rilis bitnet.cpp akan menginspirasi pengembangan LLM 1-bit dalam skala besar dalam hal ukuran model dan token pelatihan.
| Model | Parameter | CPU | Inti | ||
|---|---|---|---|---|---|
| I2_S | TL1 | TL2 | |||
| bitnet_b1_58-besar | 0,7B | x86 | ✔ | ✘ | ✔ |
| LENGAN | ✔ | ✔ | ✘ | ||
| bitnet_b1_58-3B | 3.3B | x86 | ✘ | ✘ | ✔ |
| LENGAN | ✘ | ✔ | ✘ | ||
| Token Llama3-8B-1.58-100B | 8.0B | x86 | ✔ | ✘ | ✔ |
| LENGAN | ✔ | ✔ | ✘ | ||
ular piton>=3.9
cmbuat>=3.22
dentang>=18
Pengembangan desktop dengan C++
C++-Alat CMake untuk Windows
Git untuk Windows
C++-Kompiler Dentang untuk Windows
Dukungan MS-Build untuk LLVM-Toolset (dentang)
Untuk pengguna Windows, instal Visual Studio 2022. Di penginstal, aktifkan setidaknya opsi berikut (ini juga secara otomatis menginstal alat tambahan yang diperlukan seperti CMake):
Untuk pengguna Debian/Ubuntu, Anda dapat mengunduh dengan skrip instalasi otomatis
bash -c "$(wget -O - https://apt.llvm.org/llvm.sh)"
conda (sangat merekomendasikan)
Penting
Jika Anda menggunakan Windows, harap diingat untuk selalu menggunakan Prompt Perintah Pengembang/PowerShell untuk VS2022 untuk perintah berikut
Kloning reponya
git clone --rekursif https://github.com/microsoft/BitNet.gitcd BitNet
Instal dependensinya
# (Disarankan) Buat conda environmentconda create -n bitnet-cpp python=3.9 conda mengaktifkan bitnet-cpp instalasi pip -r persyaratan.txt
Bangun proyeknya
# Unduh model dari Hugging Face, konversikan ke format gguf terkuantisasi, dan buat projectpython setup_env.py --hf-repo HF1BitLLM/Llama3-8B-1.58-100B-tokens -q i2_s# Atau Anda dapat mengunduh model secara manual dan dijalankan dengan pathhugging lokalface-cli unduh HF1BitLLM/Llama3-8B-1.58-100B-tokens --local-dir models/Llama3-8B-1.58-100B-tokens python setup_env.py -md models/Llama3-8B-1.58-100B-tokens -q i2_s
penggunaan: setup_env.py [-h] [--hf-repo {1bitLLM/bitnet_b1_58-large,1bitLLM/bitnet_b1_58-3B,HF1BitLLM/Llama3-8B-1.58-100B-tokens}] [--model-dir MODEL_DIR] [ --log-dir LOG_DIR] [--quant-type {i2_s,tl1}] [--quant-embd]
[--gunakan-pretuned]
Siapkan lingkungan untuk menjalankan inferensi
argumen opsional:
-h, --help tampilkan pesan bantuan ini dan keluar
--hf-repo {1bitLLM/bitnet_b1_58-large,1bitLLM/bitnet_b1_58-3B,HF1BitLLM/Llama3-8B-1.58-100B-tokens}, -hr {1bitLLM/bitnet_b1_58-large,1bitLLM/bitnet_b1_58-3B,HF1BitLLM/Llama3- 8B-1.58-100B-token}
Model yang digunakan untuk inferensi
--model-dir MODEL_DIR, -md MODEL_DIR
Direktori untuk menyimpan/memuat model
--log-dir LOG_DIR, -ld LOG_DIR
Direktori untuk menyimpan info logging
--tipe kuantitas {i2_s,tl1}, -q {i2_s,tl1}
Jenis kuantisasi
--quant-embd Mengkuantisasi embeddings ke f16
--use-pretuned, -p Gunakan parameter kernel yang telah disetel sebelumnya# Jalankan inferensi dengan modelpython run_inference.py -m models/Llama3-8B-1.58-100B-tokens/ggml-model-i2_s.gguf -p "Daniel kembali ke taman. Mary pergi ke dapur. Sandra berangkat ke dapur. Sandra pergi ke lorong. John pergi ke kamar tidur. Mary kembali ke taman. Dimana Mary?nJawab:" -n 6 -temp 0# Output:# Daniel kembali ke taman. Mary pergi ke dapur. Sandra berjalan ke dapur. Sandra pergi ke lorong. John pergi ke kamar tidur. Mary kembali ke taman. Dimana Maria?# Jawaban: Maria ada di taman.
penggunaan: run_inference.py [-h] [-m MODEL] [-n N_PREDICT] -p PROMPT [-t THREADS] [-c CTX_SIZE] [-temp TEMPERATURE]
Jalankan inferensi
argumen opsional:
-h, --help tampilkan pesan bantuan ini dan keluar
-m MODEL, --model MODEL
Jalur ke file model
-n N_PREDICT, --n-prediksi N_PREDICT
Jumlah token yang akan diprediksi saat membuat teks
-p PROMPT, --prompt PROMPT
Prompt untuk menghasilkan teks dari
-t BENANG, --benang BENANG
Jumlah thread yang akan digunakan
-c CTX_SIZE, --ctx-ukuran CTX_SIZE
Ukuran konteks prompt
-suhu suhu, --suhu suhu
Suhu, hyperparameter yang mengontrol keacakan teks yang dihasilkanKami menyediakan skrip untuk menjalankan tolok ukur inferensi yang menyediakan model.
usage: e2e_benchmark.py -m MODEL [-n N_TOKEN] [-p N_PROMPT] [-t THREADS] Setup the environment for running the inference required arguments: -m MODEL, --model MODEL Path to the model file. optional arguments: -h, --help Show this help message and exit. -n N_TOKEN, --n-token N_TOKEN Number of generated tokens. -p N_PROMPT, --n-prompt N_PROMPT Prompt to generate text from. -t THREADS, --threads THREADS Number of threads to use.
Berikut penjelasan singkat masing-masing argumen:
-m , --model : Jalur ke file model. Ini adalah argumen wajib yang harus diberikan saat menjalankan skrip.
-n , --n-token : Jumlah token yang dihasilkan selama inferensi. Ini adalah argumen opsional dengan nilai default 128.
-p , --n-prompt : Jumlah token prompt yang digunakan untuk menghasilkan teks. Ini adalah argumen opsional dengan nilai default 512.
-t , --threads : Jumlah thread yang digunakan untuk menjalankan inferensi. Ini adalah argumen opsional dengan nilai default 2.
-h , --help : Menampilkan pesan bantuan dan keluar. Gunakan argumen ini untuk menampilkan informasi penggunaan.
Misalnya:
python utils/e2e_benchmark.py -m /path/to/model -n 200 -p 256 -t 4
Perintah ini akan menjalankan tolok ukur inferensi menggunakan model yang terletak di /path/to/model , menghasilkan 200 token dari 256 token prompt, menggunakan 4 thread.
Untuk tata letak model yang tidak didukung oleh model publik mana pun, kami menyediakan skrip untuk menghasilkan model dummy dengan tata letak model tertentu, dan menjalankan benchmark pada mesin Anda:
python utils/generate-dummy-bitnet-model.py models/bitnet_b1_58-large --outfile models/dummy-bitnet-125m.tl1.gguf --outtype tl1 --model-size 125M# Jalankan benchmark dengan model yang dihasilkan, gunakan -m untuk menentukan jalur model, -p untuk menentukan prompt yang diproses, -n untuk menentukan jumlah token yang akan dihasilkanpython utils/e2e_benchmark.py -m models/dummy-bitnet-125m.tl1.gguf -p 512 -n 128