Darwin
1.0.0
Organisasi: Universitas New South Wales(UNSW) AI4Science & GreenDynamics AI
Darwin adalah proyek sumber terbuka yang didedikasikan untuk melakukan pra-pelatihan dan menyempurnakan model LLaMA pada literatur dan kumpulan data ilmiah. Dirancang khusus untuk domain ilmiah dengan penekanan pada ilmu material, kimia, dan fisika, Darwin mengintegrasikan pengetahuan ilmiah terstruktur dan tidak terstruktur untuk meningkatkan kemanjuran model bahasa dalam penelitian ilmiah.
Pemberitahuan Penggunaan dan Lisensi : Darwin dilisensikan dan dimaksudkan untuk penggunaan penelitian saja. Kumpulan data ini dilisensikan di bawah CC BY NC 4.0, memungkinkan penggunaan non-komersial. Model yang dilatih menggunakan kumpulan data ini tidak boleh digunakan di luar tujuan penelitian. Perbedaan bobot juga berada di bawah lisensi CC BY NC 4.0
[20.11.2024]
Pencapaian Utama
Wawasan Performa Model
Strategi dan Wawasan Data
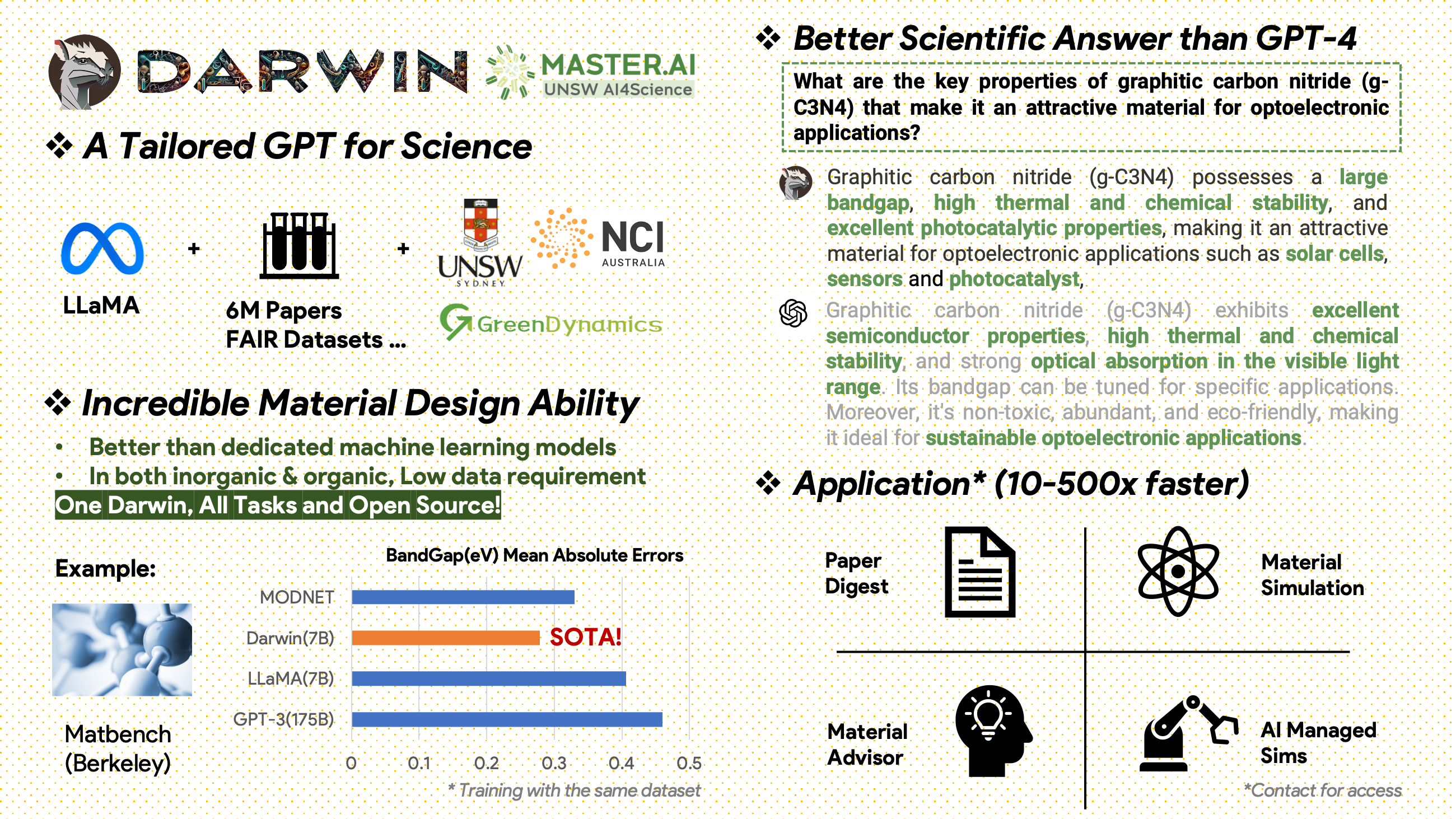
[2024.02.15] SOTA di MatBench oleh Material Projects: DARWIN adalah model SOTA dalam tugas prediksi celah pita eksperimental dan tugas klasifikasi logam, lebih baik daripada GPT3.5 yang disempurnakan dan model ML khusus. https://matbench.materialsproject.org/Leaderboards%20Per-Task/matbench_v0.1_matbench_expt_gap/
☆ [2023.09.15]Versi Google Colab tersedia: Coba DARWIN kami dengan Google Colab: inference.ipynb
Darwin, berdasarkan model LLaMA 7B, dilatih pada lebih dari 100.000 titik data mengikuti instruksi yang dihasilkan oleh Darwin Scientific instruction Generator (SIG) dari berbagai kumpulan data ilmiah FAIR dan korpus literatur. Dengan berfokus pada kebenaran faktual dari respons model, Darwin mewakili langkah signifikan dalam memanfaatkan Model Bahasa Besar (LLM) untuk penemuan ilmiah. Evaluasi awal pada manusia menunjukkan bahwa Darwin 7B mengungguli GPT-4 dalam tanya jawab ilmiah dan menyempurnakan GPT-3 dalam memecahkan masalah kimia (seperti gptChem).
Kami secara aktif mengembangkan Darwin untuk eksperimen domain ilmiah yang lebih maju, dan kami juga mengintegrasikan Darwin dengan LangChain untuk menyelesaikan tugas-tugas ilmiah yang lebih kompleks (seperti asisten peneliti swasta untuk komputer pribadi).
Perlu diketahui, Darwin masih dalam pengembangan, dan banyak keterbatasan yang perlu diatasi. Yang paling penting, kita belum menyempurnakan Darwin untuk mencapai keamanan maksimum. Kami mendorong pengguna untuk melaporkan perilaku apa pun yang mengkhawatirkan untuk membantu meningkatkan pertimbangan keselamatan dan etika model.
Tautan DEMO
Instal terlebih dahulu persyaratannya:
pip install -r requirements.txtUnduh pos pemeriksaan Bobot Darwin-7B dari onedrive. Setelah mengunduh modelnya, Anda dapat mencoba demo kami:
python inference.py < your path to darwin-7b >Harap diperhatikan, inferensi memerlukan setidaknya 10 GB memori GPU untuk Darwin 7B.
Untuk lebih menyempurnakan Darwin-7b kami dengan kumpulan data yang berbeda, di bawah ini adalah perintah yang berfungsi pada mesin dengan 4 GPU A100 80G.
torchrun --nproc_per_node=8 --master_port=1212 train.py
--model_name_or_path < your path to darwin-7b >
--data_path < your path to dataset >
--bf16 True
--output_dir < your output dir >
--num_train_epochs 3
--per_device_train_batch_size 1
--per_device_eval_batch_size 1
--gradient_accumulation_steps 1
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 500
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 1
--fsdp " full_shard auto_wrap "
--fsdp_transformer_layer_cls_to_wrap ' LlamaDecoderLayer '
--tf32 FalseData kami berasal dari dua sumber utama:
Korpus literatur mentah berisi 6,0 juta makalah tentang ilmu material, kimia, dan fisika diterbitkan setelah tahun 2000. Penerbitnya termasuk ACS, RSC, Springer Nature, Wiley, dan Elsevier. Kami berterima kasih atas dukungan mereka.
Kumpulan Data FAIR - Kami telah mengumpulkan data dari 16 Kumpulan Data FAIR.
Kami mengembangkan Darwin-SIG untuk menghasilkan instruksi ilmiah. Ia dapat menghafal teks panjang dari teks literatur lengkap (rata-rata ~5000 kata) dan menghasilkan data tanya jawab (Q&A) berdasarkan kata kunci literatur ilmiah (dari web of science API)
Catatan: Anda juga dapat menggunakan GPT3.5 atau GPT-4 untuk pembuatannya, namun opsi ini mungkin mahal.
Perlu diketahui bahwa kami tidak dapat membagikan kumpulan data pelatihan karena perjanjian dengan penerbit.
Proyek ini merupakan upaya kolaboratif dari pihak-pihak berikut:
UNSW & GreenDynamics: Tong Xie, Shaozhou Wang
UNSW: Imran Razzak, Cody Huang
Pusat USYD & DARE: Clara Grazian
Dinamika Hijau: Yuwei Wan, Yixuan Liu
Bram Hoex dan Wenjie Zhang dari UNSW Engineering menasihati semuanya.
Jika Anda menggunakan data atau kode dari repositori ini dalam karya Anda, mohon kutip dengan tepat.
Model Bahasa Besar Dasar DAWRIN & Penyempurnaan Instruksi Semi-Mandiri
@misc{xie2023darwin,
title={DARWIN Series: Domain Specific Large Language Models for Natural Science},
author={Tong Xie and Yuwei Wan and Wei Huang and Zhenyu Yin and Yixuan Liu and Shaozhou Wang and Qingyuan Linghu and Chunyu Kit and Clara Grazian and Wenjie Zhang and Imran Razzak and Bram Hoex},
year={2023},
eprint={2308.13565},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
GPT-3 & LLaMA yang disempurnakan untuk Penemuan Material (Pelatihan Tugas Tunggal)
@article{xie2023large,
title={Large Language Models as Master Key: Unlocking the Secrets of Materials Science},
author={Xie, Tong and Wan, Yuwei and Zhou, Yufei and Huang, Wei and Liu, Yixuan and Linghu, Qingyuan and Wang, Shaozhou and Kit, Chunyu and Grazian, Clara and Zhang, Wenjie and others},
journal={Available at SSRN 4534137},
year={2023}
}
Proyek ini mengacu pada proyek sumber terbuka berikut:
Terima kasih khusus kepada NCI Australia atas dukungan HPC mereka.
Kami terus memperluas Tim pengembangan Darwin. Bergabunglah bersama kami dalam perjalanan menarik dalam memajukan penelitian ilmiah dengan AI!
Untuk posisi PhD atau PostDoc, silakan menghubungi [email protected] atau [email protected] untuk rinciannya.
Untuk posisi lain, silakan kunjungi www.greendynamics.com.au