multimedia gpt
1.0.0
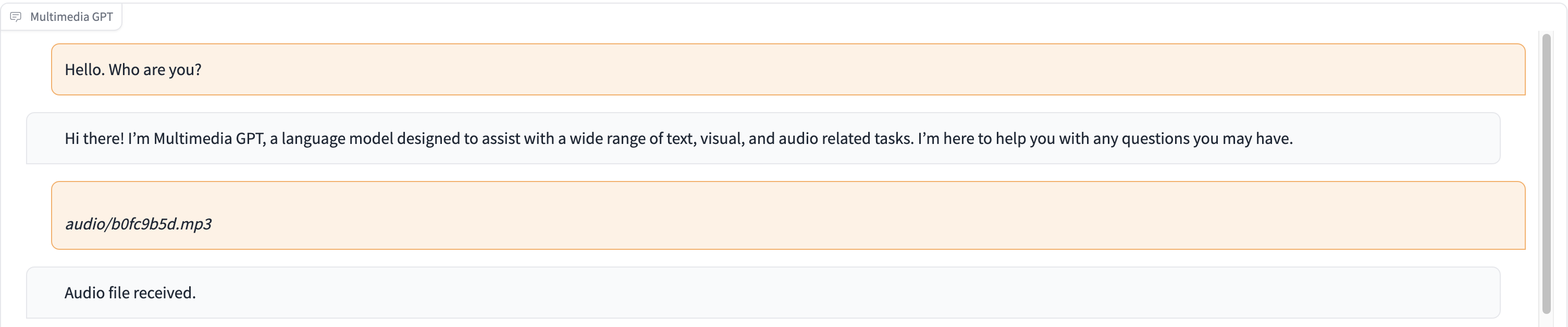
GPT Multimedia menghubungkan GPT OpenAI Anda dengan visi dan audio. Anda sekarang dapat mengirim gambar, rekaman audio, dan dokumen pdf menggunakan kunci API OpenAI Anda, dan mendapatkan respons dalam format teks dan gambar. Kami sedang menambahkan dukungan untuk video. Semua dimungkinkan oleh manajer cepat yang terinspirasi dan dibangun di atas Microsoft Visual ChatGPT.
Selain semua model landasan visi yang disebutkan dalam Microsoft Visual ChatGPT, Multimedia GPT mendukung OpenAI Whisper dan OpenAI DALLE! Ini berarti Anda tidak lagi memerlukan GPU Anda sendiri untuk pengenalan suara dan pembuatan gambar (walaupun Anda masih bisa!)
Model obrolan dasar dapat dikonfigurasi sebagai OpenAI LLM apa pun , termasuk ChatGPT dan GPT-4. Kami default ke text-davinci-003 .
Anda dipersilakan untuk membagi proyek ini dan menambahkan model yang sesuai untuk kasus penggunaan Anda sendiri. Cara sederhana untuk melakukannya adalah melalui llama_index. Anda harus membuat kelas baru untuk model Anda di model.py , dan menambahkan metode runner run_<model_name> di multimedia_gpt.py . Lihat run_pdf sebagai contoh.
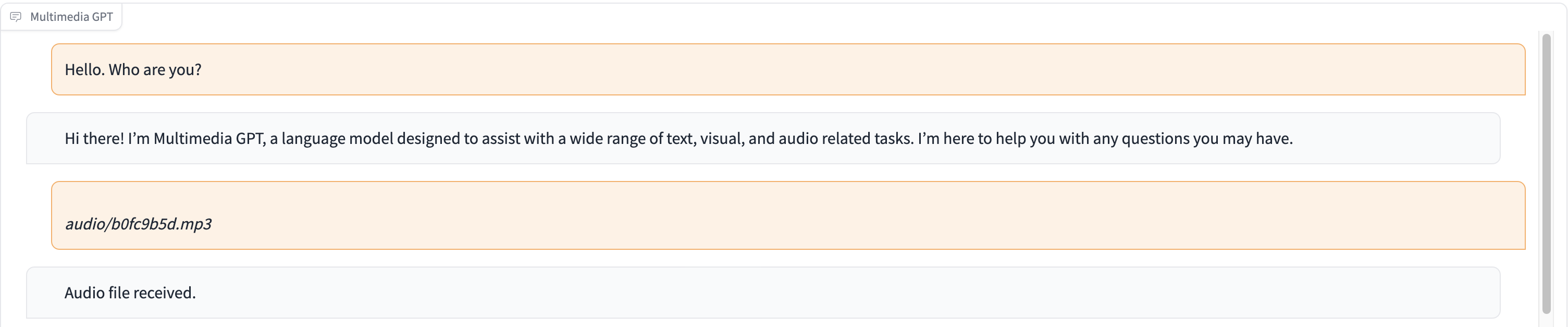
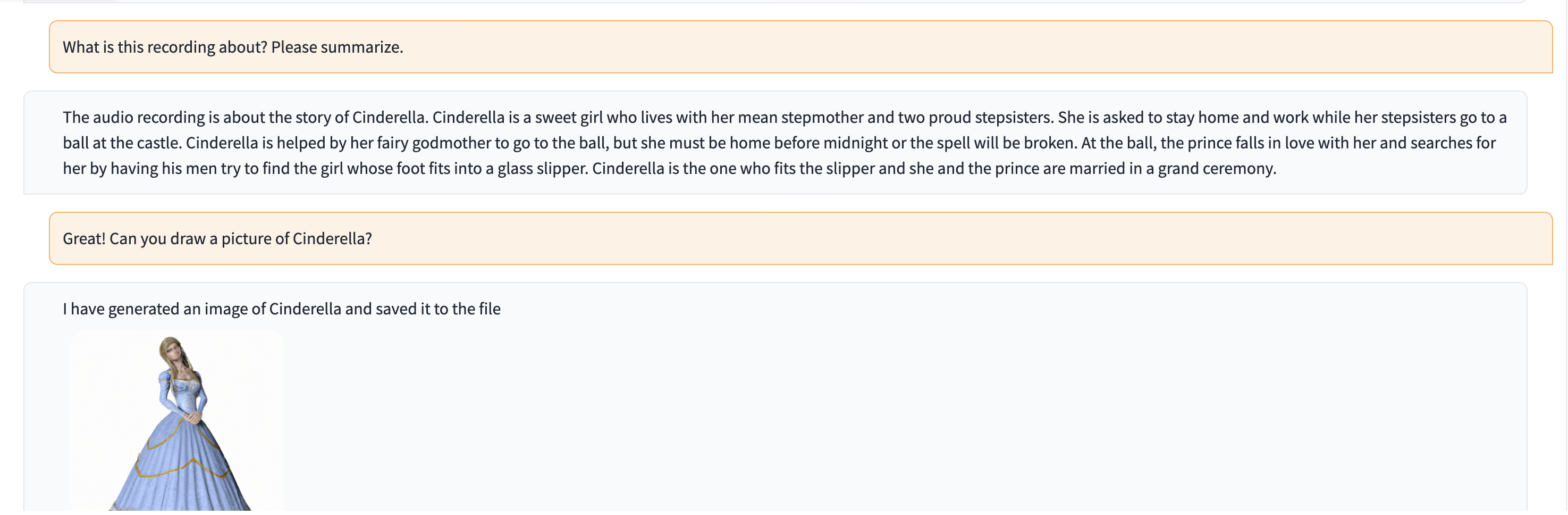
Dalam demo ini, ChatGPT diisi dengan rekaman seseorang yang menceritakan kisah Cinderella.
# Clone this repository
git clone https://github.com/fengyuli2002/multimedia-gpt
cd multimedia-gpt
# Prepare a conda environment
conda create -n multimedia-gpt python=3.8
conda activate multimedia-gptt
pip install -r requirements.txt
# prepare your private OpenAI key (for Linux / MacOS)
echo " export OPENAI_API_KEY='yourkey' " >> ~ /.zshrc
# prepare your private OpenAI key (for Windows)
setx OPENAI_API_KEY “ < yourkey > ”
# Start Multimedia GPT!
# You can specify the GPU/CPU assignment by "--load", the parameter indicates which foundation models to use and
# where it will be loaded to. The model and device are separated by '_', different models are separated by ','.
# The available Visual Foundation Models can be found in models.py
# For example, if you want to load ImageCaptioning to cuda:0 and whisper to cpu
# (whisper runs remotely, so it doesn't matter where it is loaded to)
# You can use: "ImageCaptioning_cuda:0,Whisper_cpu"
# Don't have GPUs? No worry, you can run DALLE and Whisper on cloud using your API key!
python multimedia_gpt.py --load ImageCaptioning_cpu,DALLE_cpu,Whisper_cpu
# Additionally, you can configure the which OpenAI LLM to use by the "--llm" tag, such as
python multimedia_gpt.py --llm text-davinci-003
# The default is gpt-3.5-turbo (ChatGPT). Proyek ini adalah karya eksperimental dan tidak akan diterapkan ke lingkungan produksi. Tujuan kami adalah untuk mengeksplorasi kekuatan bisikan.