horovod
v0.28.1: Build fixes (ROCm, GCC 12)
Horovod adalah kerangka pelatihan pembelajaran mendalam terdistribusi untuk TensorFlow, Keras, PyTorch, dan Apache MXNet. Tujuan Horovod adalah membuat pembelajaran mendalam terdistribusi menjadi cepat dan mudah digunakan.
Horovod diselenggarakan oleh LF AI & Data Foundation (LF AI & Data). Jika Anda adalah perusahaan yang sangat berkomitmen untuk menggunakan teknologi sumber terbuka dalam kecerdasan buatan, mesin, dan pembelajaran mendalam, serta ingin mendukung komunitas proyek sumber terbuka di domain ini, pertimbangkan untuk bergabung dengan LF AI & Data Foundation. Untuk rincian tentang siapa saja yang terlibat dan bagaimana Horovod berperan, baca pengumuman Linux Foundation.
Isi
Motivasi utama proyek ini adalah untuk mempermudah penggunaan skrip pelatihan GPU tunggal dan berhasil menskalakannya untuk melatih banyak GPU secara paralel. Ini memiliki dua aspek:
Secara internal di Uber, kami menemukan model MPI jauh lebih mudah dan memerlukan perubahan kode yang jauh lebih sedikit dibandingkan solusi sebelumnya seperti TensorFlow Terdistribusi dengan server parameter. Setelah skrip pelatihan ditulis untuk skala besar dengan Horovod, skrip pelatihan dapat berjalan pada satu GPU, beberapa GPU, atau bahkan beberapa host tanpa perubahan kode lebih lanjut. Lihat bagian Penggunaan untuk lebih jelasnya.
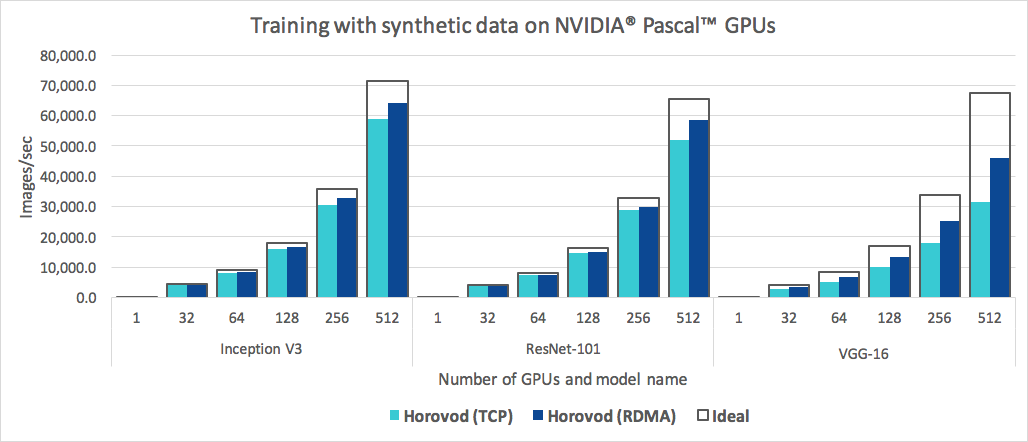
Selain mudah digunakan, Horovod juga cepat. Di bawah ini adalah bagan yang mewakili benchmark yang dilakukan pada 128 server dengan 4 GPU Pascal yang masing-masing dihubungkan oleh jaringan berkemampuan RoCE 25 Gbit/s:
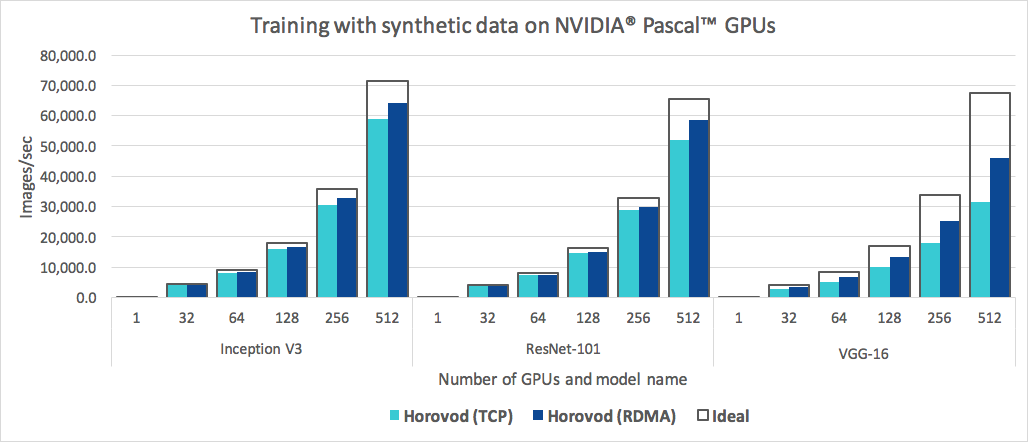
Horovod mencapai efisiensi penskalaan 90% untuk Inception V3 dan ResNet-101, dan efisiensi penskalaan 68% untuk VGG-16. Lihat Tolok Ukur untuk mengetahui cara mereproduksi angka-angka ini.
Meskipun menginstal MPI dan NCCL sendiri mungkin tampak merepotkan, hal ini hanya perlu dilakukan satu kali oleh tim yang menangani infrastruktur, sementara semua orang di perusahaan yang membuat model dapat menikmati kemudahan pelatihan dalam skala besar.
Untuk menginstal Horovod di Linux atau macOS:
Jika Anda telah menginstal TensorFlow dari PyPI, pastikan g++-5 atau yang lebih baru telah diinstal. Dimulai dengan TensorFlow 2.10, diperlukan compiler yang sesuai dengan C++17 seperti g++8 atau lebih tinggi.
Jika Anda telah menginstal PyTorch dari PyPI, pastikan g++-5 atau lebih tinggi telah diinstal.
Jika Anda telah menginstal salah satu paket dari Conda, pastikan paket Conda gxx_linux-64 telah diinstal.
Instal paket pip horovod .
Untuk berjalan di CPU:
$ pip install horovodUntuk berjalan pada GPU dengan NCCL:
$ HOROVOD_GPU_OPERATIONS=NCCL pip install horovodUntuk detail lebih lanjut tentang menginstal Horovod dengan dukungan GPU, baca Horovod di GPU.
Untuk daftar lengkap opsi instalasi Horovod, baca Panduan Instalasi.
Jika Anda ingin menggunakan MPI, baca Horovod dengan MPI.
Jika Anda ingin menggunakan Conda, baca Membangun lingkungan Conda dengan dukungan GPU untuk Horovod.
Jika Anda ingin menggunakan Docker, baca Horovod di Docker.
Untuk mengkompilasi Horovod dari sumber, ikuti petunjuk di Panduan Kontributor.
Prinsip inti Horovod didasarkan pada konsep MPI seperti size , rank , local rank , allreduce , allgather , Broadcast , dan alltoall . Lihat halaman ini untuk lebih jelasnya.
Lihat halaman berikut untuk mengetahui contoh dan praktik terbaik Horovod:
Untuk menggunakan Horovod, buat tambahan berikut pada program Anda:
hvd.init() untuk menginisialisasi Horovod.Sematkan setiap GPU ke satu proses untuk menghindari pertikaian sumber daya.
Dengan pengaturan khas satu GPU per proses, setel ini ke local rank . Proses pertama di server akan mendapat alokasi GPU pertama, proses kedua akan mendapat alokasi GPU kedua, dan seterusnya.
Skalakan kecepatan pemelajaran berdasarkan jumlah pekerja.
Ukuran batch efektif dalam pelatihan terdistribusi sinkron diskalakan berdasarkan jumlah pekerja. Peningkatan kecepatan pemelajaran mengkompensasi peningkatan ukuran batch.
Bungkus pengoptimal dalam hvd.DistributedOptimizer .
Pengoptimal terdistribusi mendelegasikan penghitungan gradien ke pengoptimal asli, meratakan gradien menggunakan allreduce atau allgather , lalu menerapkan gradien rata-rata tersebut.
Siarkan status variabel awal dari peringkat 0 ke semua proses lainnya.
Hal ini diperlukan untuk memastikan inisialisasi yang konsisten dari semua pekerja ketika pelatihan dimulai dengan bobot acak atau dipulihkan dari pos pemeriksaan.
Contoh penggunaan TensorFlow v1 (lihat direktori contoh untuk contoh pelatihan lengkap):
import tensorflow as tf
import horovod . tensorflow as hvd
# Initialize Horovod
hvd . init ()
# Pin GPU to be used to process local rank (one GPU per process)
config = tf . ConfigProto ()
config . gpu_options . visible_device_list = str ( hvd . local_rank ())
# Build model...
loss = ...
opt = tf . train . AdagradOptimizer ( 0.01 * hvd . size ())
# Add Horovod Distributed Optimizer
opt = hvd . DistributedOptimizer ( opt )
# Add hook to broadcast variables from rank 0 to all other processes during
# initialization.
hooks = [ hvd . BroadcastGlobalVariablesHook ( 0 )]
# Make training operation
train_op = opt . minimize ( loss )
# Save checkpoints only on worker 0 to prevent other workers from corrupting them.
checkpoint_dir = '/tmp/train_logs' if hvd . rank () == 0 else None
# The MonitoredTrainingSession takes care of session initialization,
# restoring from a checkpoint, saving to a checkpoint, and closing when done
# or an error occurs.
with tf . train . MonitoredTrainingSession ( checkpoint_dir = checkpoint_dir ,
config = config ,
hooks = hooks ) as mon_sess :
while not mon_sess . should_stop ():
# Perform synchronous training.
mon_sess . run ( train_op )Contoh perintah di bawah ini menunjukkan cara menjalankan pelatihan terdistribusi. Lihat Jalankan Horovod untuk detail lebih lanjut, termasuk penyesuaian RoCE/InfiniBand dan tip untuk mengatasi hang.
Untuk dijalankan pada mesin dengan 4 GPU:
$ horovodrun -np 4 -H localhost:4 python train.pyUntuk dijalankan pada 4 mesin dengan masing-masing 4 GPU:
$ horovodrun -np 16 -H server1:4,server2:4,server3:4,server4:4 python train.py Untuk menjalankan menggunakan Open MPI tanpa pembungkus horovodrun , lihat Menjalankan Horovod dengan Open MPI.
Untuk menjalankan di Docker, lihat Horovod di Docker.
Untuk berjalan di Kubernetes, lihat Helm Chart, Operator MPI Kubeflow, FfDL, dan Polyaxon.
Untuk berjalan di Spark, lihat Horovod di Spark.
Untuk menjalankan Ray, lihat Horovod di Ray.
Untuk menjalankan Singularitas, lihat Singularitas.
Untuk berjalan di cluster LSF HPC (misalnya Summit), lihat LSF.
Untuk menjalankan Benang Hadoop, lihat TonY.
Gloo adalah perpustakaan komunikasi kolektif sumber terbuka yang dikembangkan oleh Facebook.
Gloo disertakan dengan Horovod, dan memungkinkan pengguna menjalankan Horovod tanpa memerlukan instalasi MPI.
Untuk lingkungan yang mendukung MPI dan Gloo, Anda dapat memilih untuk menggunakan Gloo saat runtime dengan meneruskan argumen --gloo ke horovodrun :
$ horovodrun --gloo -np 2 python train.pyHorovod mendukung pencampuran dan pencocokan kolektif Horovod dengan perpustakaan MPI lainnya, seperti mpi4py, asalkan MPI dibangun dengan dukungan multi-threading.
Anda dapat memeriksa dukungan multi-threading MPI dengan menanyakan fungsi hvd.mpi_threads_supported() .
import horovod . tensorflow as hvd
# Initialize Horovod
hvd . init ()
# Verify that MPI multi-threading is supported.
assert hvd . mpi_threads_supported ()
from mpi4py import MPI
assert hvd . size () == MPI . COMM_WORLD . Get_size ()Anda juga dapat menginisialisasi Horovod dengan sub-komunikator mpi4py, dalam hal ini setiap sub-komunikator akan menjalankan pelatihan Horovod secara independen.
from mpi4py import MPI
import horovod . tensorflow as hvd
# Split COMM_WORLD into subcommunicators
subcomm = MPI . COMM_WORLD . Split ( color = MPI . COMM_WORLD . rank % 2 ,
key = MPI . COMM_WORLD . rank )
# Initialize Horovod
hvd . init ( comm = subcomm )
print ( 'COMM_WORLD rank: %d, Horovod rank: %d' % ( MPI . COMM_WORLD . rank , hvd . rank ()))Pelajari cara mengoptimalkan model Anda untuk inferensi dan menghapus operasi Horovod dari grafik di sini.
Salah satu hal unik tentang Horovod adalah kemampuannya untuk menyisipkan komunikasi dan komputasi ditambah dengan kemampuan untuk mengelompokkan operasi kecil- kecilan , yang menghasilkan peningkatan kinerja. Kami menyebutnya fitur batching Tensor Fusion.
Lihat di sini untuk detail lengkap dan instruksi penyesuaian.
Horovod memiliki kemampuan untuk mencatat timeline aktivitasnya yang disebut Horovod Timeline.
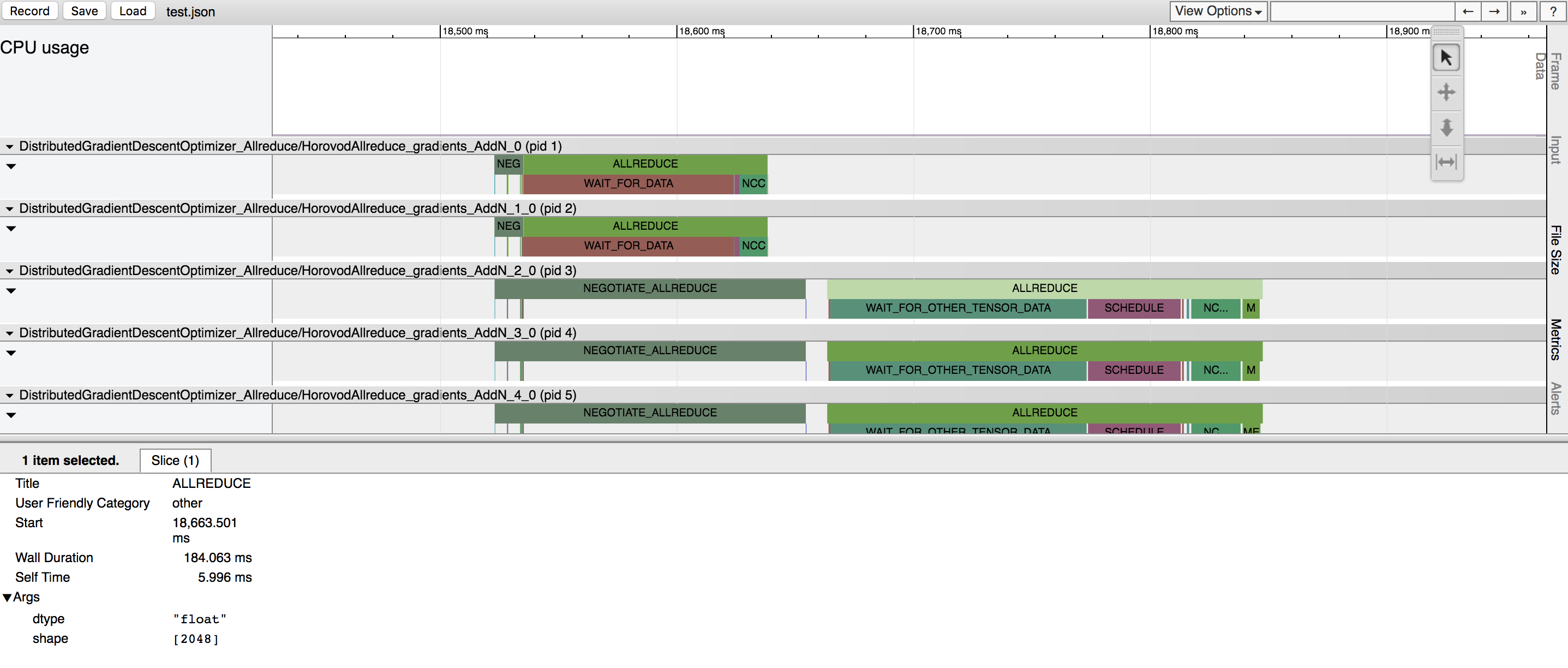
Gunakan garis waktu Horovod untuk menganalisis kinerja Horovod. Lihat di sini untuk rincian lengkap dan petunjuk penggunaan.
Memilih nilai yang tepat untuk memanfaatkan Tensor Fusion dan fitur Horovod lanjutan lainnya secara efisien dapat memerlukan banyak percobaan dan kesalahan. Kami menyediakan sistem untuk mengotomatiskan proses pengoptimalan kinerja yang disebut penyetelan otomatis , yang dapat Anda aktifkan dengan satu argumen baris perintah ke horovodrun .
Lihat di sini untuk rincian lengkap dan petunjuk penggunaan.
Horovod memungkinkan Anda menjalankan operasi kolektif yang berbeda secara bersamaan dalam kelompok proses berbeda yang mengambil bagian dalam satu pelatihan terdistribusi. Siapkan objek hvd.process_set untuk memanfaatkan kemampuan ini.
Lihat Rangkaian Proses untuk instruksi rinci.
Kirimi kami tautan ke panduan pengguna mana pun yang ingin Anda terbitkan di situs ini
Lihat Pemecahan Masalah dan kirimkan tiket jika Anda tidak dapat menemukan jawabannya.
Silakan kutip Horovod dalam publikasi Anda jika itu membantu penelitian Anda:
@artikel{sergeev2018horovod,
Penulis = {Alexander Sergeev dan Mike Del Balso},
Jurnal = {arXiv pracetak arXiv:1802.05799},
Judul = {Horovod: pembelajaran mendalam yang didistribusikan dengan cepat dan mudah di {TensorFlow}},
Tahun = {2018}
}
1. Sergeev, A., Del Balso, M. (2017) Temui Horovod: Kerangka Pembelajaran Mendalam Terdistribusi Sumber Terbuka Uber untuk TensorFlow . Diperoleh dari https://eng.uber.com/horovod/
2. Sergeev, A. (2017) Horovod - TensorFlow Terdistribusi Menjadi Mudah . Diperoleh dari https://www.slideshare.net/AlexanderSergeev4/horovod-distributed-tensorflow-made-easy
3. Sergeev, A., Del Balso, M. (2018) Horovod: pembelajaran mendalam yang didistribusikan dengan cepat dan mudah di TensorFlow . Diperoleh dari arXiv:1802.05799
Kode sumber Horovod didasarkan pada repositori Baidu tensorflow-allreduce yang ditulis oleh Andrew Gibiansky dan Joel Hestness. Karya asli mereka dijelaskan dalam artikel Membawa Teknik HPC ke Pembelajaran Mendalam.