QuillGPT
1.0.0

QuillGPT adalah implementasi blok decoder GPT berdasarkan arsitektur dari makalah Attention is All You Need oleh Vaswani et. al. diimplementasikan di PyTorch. Selain itu, repositori ini berisi dua model terlatih—Shakespearean GPT dan Harpoon GPT—bersama dengan bobot terlatihnya. Untuk kemudahan eksperimen dan penerapan, Streamlit Playground disediakan untuk eksplorasi interaktif model ini dan layanan mikro FastAPI diimplementasikan dengan containerisasi Docker untuk penerapan yang skalabel. Anda juga akan menemukan skrip Python untuk melatih model GPT baru dan melakukan inferensi pada model tersebut, serta buku catatan yang menampilkan model terlatih. Untuk memfasilitasi pengkodean dan penguraian teks, tokenizer sederhana diterapkan. Jelajahi QuillGPT untuk memanfaatkan alat ini dan menyempurnakan proyek pemrosesan bahasa alami Anda!
Ada dua model dan bobot terlatih yang disertakan dalam repositori ini.
| Fitur | GPT Shakespeare | Harpun GPT |
|---|---|---|
| Parameter | 10,7 M | 226 M |
| beban | beban | beban |
| Konfigurasi Model | Konfigurasi | Konfigurasi |
| Data Pelatihan | Teks dari drama Shakespeare (input.txt) | Teks acak dari buku (corpus.txt) |
| Jenis Penyematan | Penyematan karakter | Penyematan karakter |
| Buku Catatan Pelatihan | Buku catatan | Buku catatan |
| Perangkat keras | NVIDIA T4 | NVIDIA A100 |
| Kerugian Pelatihan & Validasi | 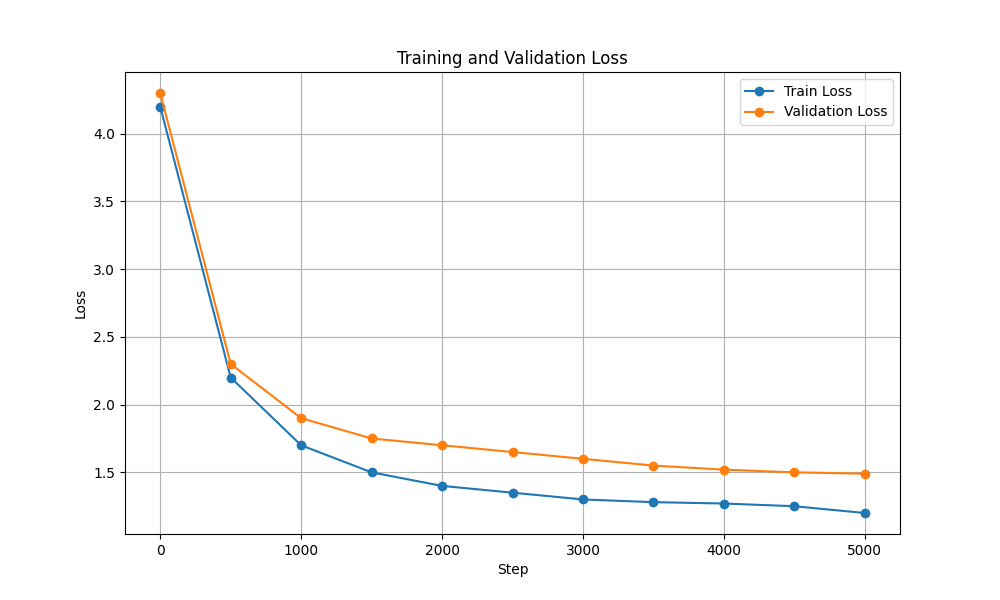 | 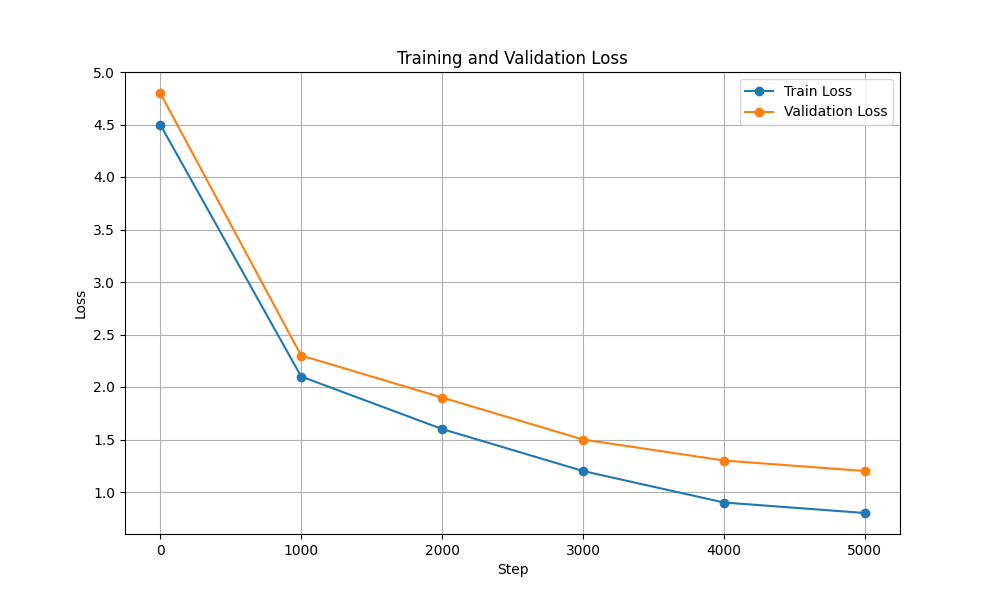 |
Untuk menjalankan skrip pelatihan dan inferensi, ikuti langkah-langkah berikut:
git clone https://github.com/NotShrirang/GPT-From-Scratch.git
cd GPT-From-Scratchpip install -r requirements.txtPastikan Anda mengunduh bobot Harpoon GPT dari sini sebelum melanjutkan!
Itu dihosting di Layanan Cloud Streamlit. Anda dapat mengunjunginya melalui tautan di sini.
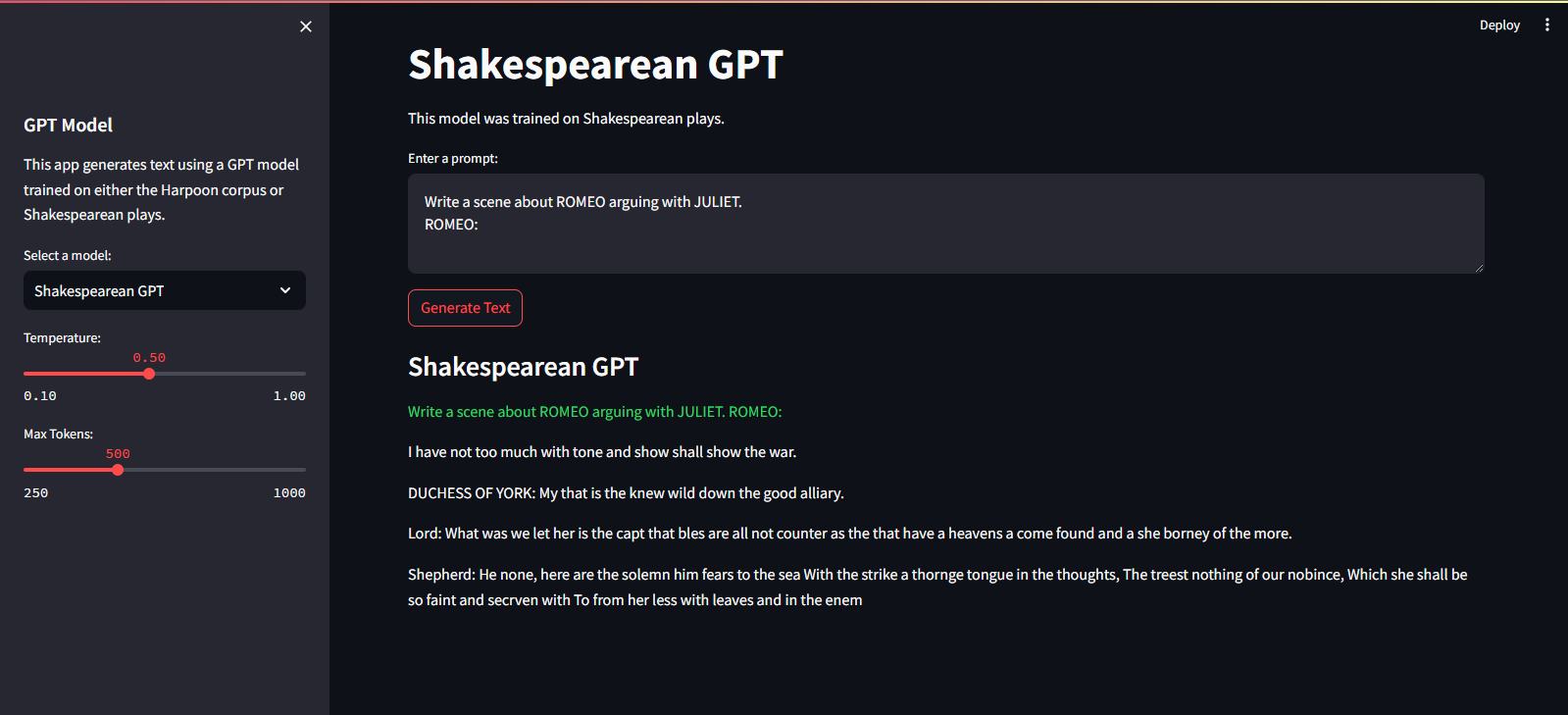
streamlit run app.pypython main.py./run.sh start-dev./run.sh stop-devUntuk melatih model GPT, ikuti langkah-langkah berikut:
Siapkan datanya. Masukkan seluruh data teks ke dalam satu file .txt dan simpan.
Tulis konfigurasi untuk transformator dan simpan file.
Misalnya: json { "data_path": "data/corpus.txt", "vocab_size": 135, "batch_size": 32, "block_size": 256, "max_iters": 3000, "eval_interval": 300, "learning_rate": 3e-5, "eval_iters": 50, "n_embd": 1024, "n_head": 12, "n_layer": 18, "dropout": 0.3, }
Latih model menggunakan scripts/train_gpt.py
python scripts/train_gpt.py
--config_path config/config.json
--data_path data/corpus.txt
--output_dir trained_models (Anda dapat mengubah config_path , data_path dan output_dir sesuai kebutuhan Anda.)
output_dir yang ditentukan dalam perintah.Setelah pelatihan, Anda dapat menggunakan model GPT terlatih untuk pembuatan teks. Berikut ini contoh penggunaan model terlatih untuk inferensi:
python scripts/inference_gpt.py
--config_path config/shakespearean_config.json
--weights_path weights/GPT_model_char.pt
--max_length 500
--prompt " Once upon a time " 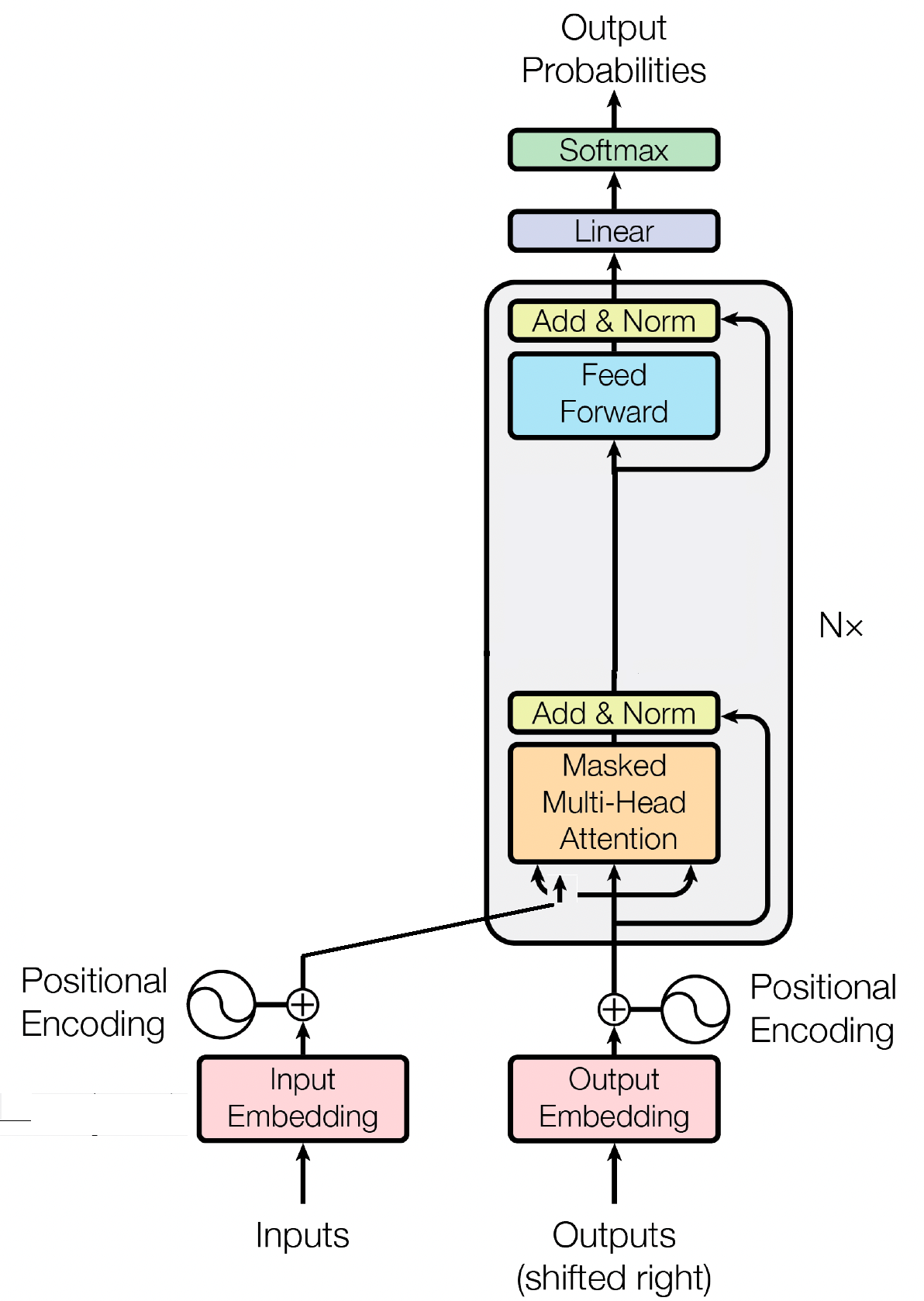
Blok decoder adalah komponen penting dari model GPT (Generative Pre-trained Transformer), di sinilah GPT benar-benar menghasilkan teks. Ini memanfaatkan mekanisme perhatian diri untuk memproses urutan masukan dan menghasilkan keluaran yang koheren. Setiap blok decoder terdiri dari beberapa lapisan, termasuk lapisan perhatian mandiri, jaringan saraf feed-forward, dan normalisasi lapisan. Lapisan perhatian diri memungkinkan model untuk mempertimbangkan pentingnya kata-kata yang berbeda secara berurutan, menangkap konteks dan ketergantungan terlepas dari posisinya. Hal ini memungkinkan model GPT menghasilkan teks yang relevan secara kontekstual.
Penyematan masukan memainkan peran penting dalam model berbasis transformator seperti GPT dengan mengubah token masukan menjadi representasi numerik yang bermakna. Penyematan ini berfungsi sebagai masukan awal untuk model, menangkap informasi semantik tentang kata-kata dalam urutan. Prosesnya melibatkan pemetaan setiap token dalam urutan masukan ke ruang vektor berdimensi tinggi, di mana token serupa diposisikan berdekatan. Hal ini memungkinkan model untuk memahami hubungan antara kata-kata yang berbeda dan belajar secara efektif dari data masukan. Penyematan masukan kemudian dimasukkan ke lapisan model berikutnya untuk diproses lebih lanjut.
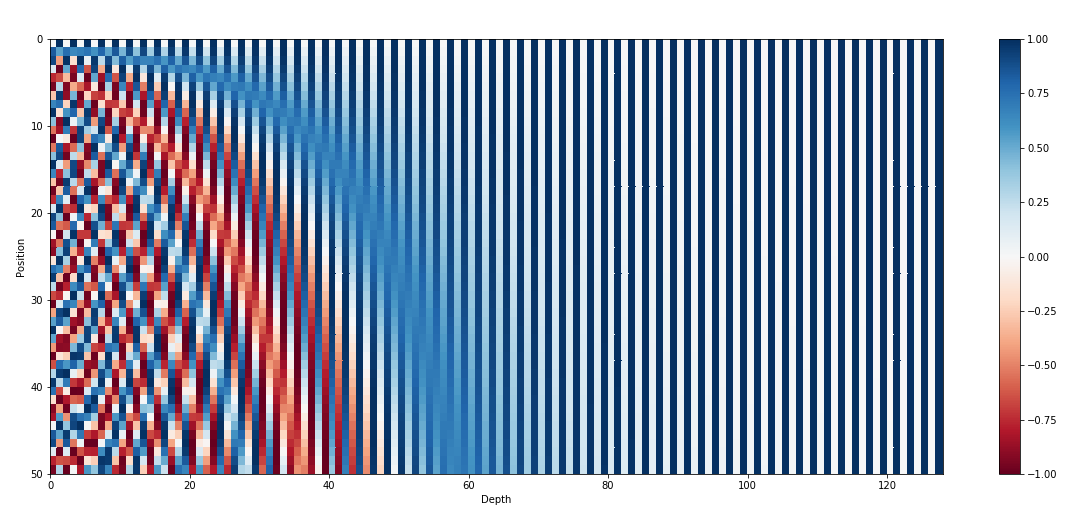
Selain penyematan masukan, penyematan posisi adalah komponen penting lainnya dari arsitektur transformator seperti GPT. Karena transformator kekurangan informasi inheren tentang urutan token dalam suatu urutan, penyematan posisi diperkenalkan untuk memberikan informasi posisi kepada model. Penyematan ini mengkodekan posisi setiap token dalam urutan, memungkinkan model membedakan token berdasarkan posisinya. Dengan menggabungkan penyematan posisi, transformator seperti GPT dapat secara efektif menangkap sifat sekuensial data dan menghasilkan keluaran koheren yang mempertahankan urutan kata yang benar dalam teks yang dihasilkan.

Perhatian diri, mekanisme mendasar dalam model berbasis transformator seperti GPT, beroperasi dengan menetapkan skor kepentingan pada kata-kata berbeda secara berurutan. Proses ini melibatkan tiga langkah utama: menghitung skor perhatian, menerapkan softmax untuk mendapatkan bobot perhatian, dan terakhir menggabungkan bobot ini dengan penyematan masukan untuk menghasilkan representasi berdasarkan informasi kontekstual. Pada intinya, perhatian diri memungkinkan model untuk lebih fokus pada kata-kata yang relevan dan tidak menekankan kata-kata yang kurang penting, sehingga memfasilitasi pembelajaran yang efektif tentang ketergantungan kontekstual dalam data masukan. Mekanisme ini sangat penting dalam menangkap ketergantungan jangka panjang dan nuansa kontekstual, memungkinkan model transformator menghasilkan rangkaian teks yang panjang.
MIT © Shrirang Mahajan
Jangan ragu untuk mengirimkan permintaan penarikan, membuat masalah, atau menyebarkan berita!
Dukung saya hanya dengan membintangi repositori ini!