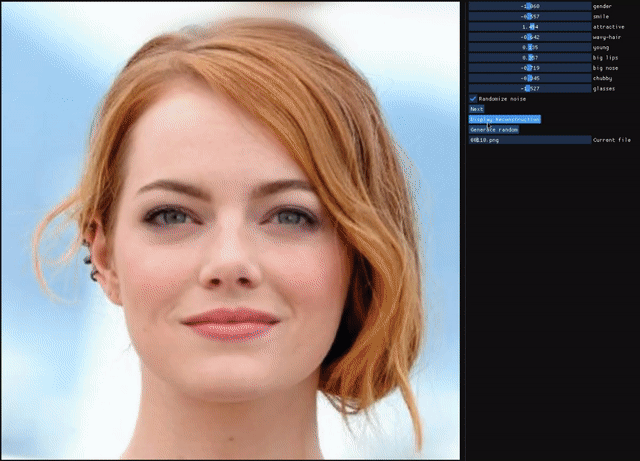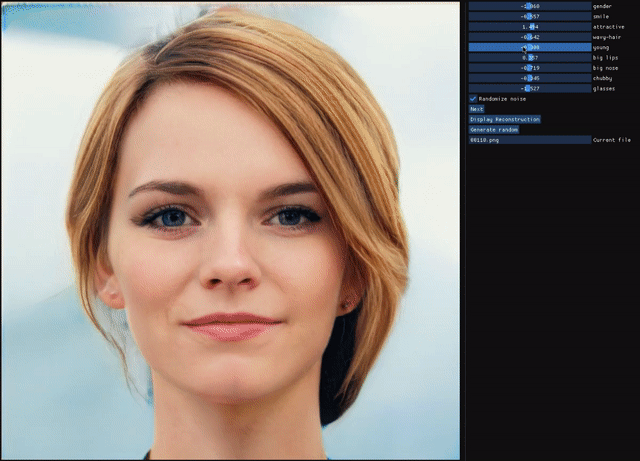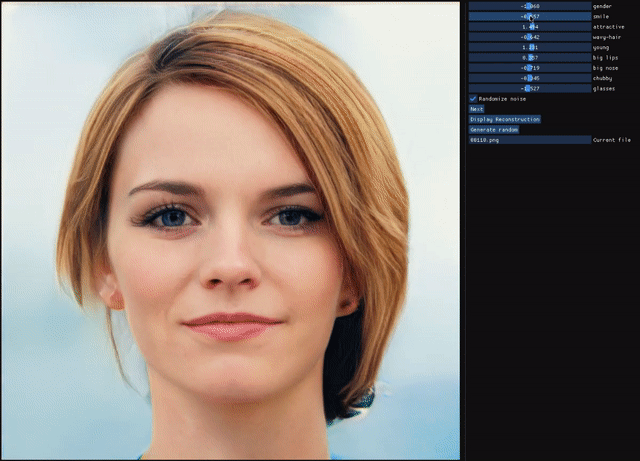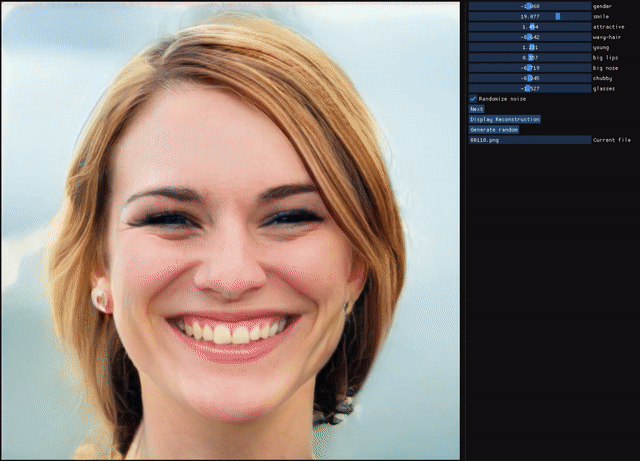
ALAE
1.0.0
Stanislav Pidhorskyi • Donald A. Adjeroh • Gianfranco Doretto
 |  |
Folder Google Drive dengan model dan hasil kualitatif
Autoencoder Laten Permusuhan
Stanislav Pidhorskyi, Donald Adjeroh, Gianfranco DorettoAbstrak: Jaringan autoencoder adalah pendekatan tanpa pengawasan yang bertujuan untuk menggabungkan properti generatif dan representasional dengan mempelajari peta generator-encoder secara bersamaan. Meskipun dipelajari secara ekstensif, permasalahan apakah mereka memiliki kekuatan generatif yang sama dengan GAN, atau mempelajari representasi yang terurai, belum sepenuhnya diatasi. Kami memperkenalkan autoencoder yang mengatasi masalah ini bersama-sama, yang kami sebut Adversarial Latent Autoencoder (ALAE). Ini adalah arsitektur umum yang dapat memanfaatkan perbaikan terkini pada prosedur pelatihan GAN. Kami merancang dua autoencoder: satu berdasarkan encoder MLP, dan satu lagi berdasarkan generator StyleGAN, yang kami sebut StyleALAE. Kami memverifikasi properti penguraian kedua arsitektur. Kami menunjukkan bahwa StyleALAE tidak hanya dapat menghasilkan gambar wajah 1024x1024 dengan kualitas yang sebanding dengan StyleGAN, tetapi pada resolusi yang sama juga dapat menghasilkan rekonstruksi dan manipulasi wajah berdasarkan gambar nyata. Hal ini menjadikan ALAE autoencoder pertama yang mampu membandingkan, dan melampaui kemampuan jenis arsitektur khusus generator.
@InProceedings{pidhorskyi2020adversarial,
author = {Pidhorskyi, Stanislav and Adjeroh, Donald A and Doretto, Gianfranco},
booktitle = {Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR)},
title = {Adversarial Latent Autoencoders},
year = {2020},
note = {[to appear]},
}
Untuk menjalankan demo, Anda harus memiliki GPU berkemampuan CUDA, PyTorch >= v1.3.1 dan driver cuda/cuDNN diinstal. Instal paket yang diperlukan:
pip install -r requirements.txt
Unduh model terlatih:
python training_artifacts/download_all.py
Jalankan demonya:
python interactive_demo.py
Anda dapat menentukan konfigurasi yaml yang akan digunakan. Konfigurasi ada di sini: https://github.com/podgorskiy/ALAE/tree/master/configs. Secara default, ini menggunakan satu untuk kumpulan data FFHQ. Anda dapat mengubah konfigurasi menggunakan parameter -c . Untuk berjalan di celeb-hq dalam resolusi 256x256, jalankan:
python interactive_demo.py -c celeba-hq256
Namun, untuk konfigurasi selain FFHQ, Anda perlu mendapatkan vektor arah utama baru untuk atributnya.
Kode dalam repositori diatur sedemikian rupa sehingga semua skrip harus dijalankan dari root repositori. Jika Anda menggunakan IDE (misalnya PyCharm atau Visual Studio Code), cukup atur Direktori Kerja agar menunjuk ke root repositori.
Jika Anda ingin menjalankan dari baris perintah, Anda juga perlu mengatur variabel PYTHONPATH agar menunjuk ke root repositori.
Misalnya, kita telah mengkloning repositori ke direktori ~/ALAE , lalu lakukan:
$ cd ~/ALAE
$ export PYTHONPATH=$PYTHONPATH:$(pwd)
Sekarang Anda dapat menjalankan skrip sebagai berikut:
$ python style_mixing/stylemix.py
| Jalur | Keterangan |
|---|---|
| ALAE | Folder akar repositori |
| ├ konfigurasi | Folder dengan file konfigurasi yaml. |
| │ ├ kamar tidur.yaml | File konfigurasi untuk kumpulan data kamar tidur LSUN dengan resolusi 256x256. |
| │ ├ celeba.yaml | File konfigurasi untuk kumpulan data CelebA dengan resolusi 128x128. |
| │ ├ celeba-hq256.yaml | File konfigurasi untuk kumpulan data CelebA-HQ dengan resolusi 256x256. |
| │ ├ celeba_ablasi_nostyle.yaml | File konfigurasi untuk kumpulan data CelebA 128x128 untuk studi ablasi (tanpa gaya). |
| │ ├ celeba_ablation_separate.yaml | File konfigurasi untuk kumpulan data CelebA 128x128 untuk studi ablasi (encoder dan diskriminator terpisah). |
| │ ├ celeba_ablasi_z_reg.yaml | File konfigurasi untuk kumpulan data CelebA 128x128 untuk studi ablasi (regresi dalam ruang Z, bukan W). |
| │ ├ ffhq.yaml | File konfigurasi untuk dataset FFHQ pada resolusi 1024x1024. |
| │ ├ mnist.yaml | File konfigurasi untuk kumpulan data MNIST menggunakan arsitektur Style. |
| │ └ mnist_fc.yaml | File konfigurasi untuk kumpulan data MNIST hanya menggunakan lapisan yang terhubung sepenuhnya (Permutation Invariant MNIST). |
| ├ kumpulan data_persiapan | Folder dengan skrip untuk persiapan kumpulan data. |
| │ ├ persiapkan_celeba_hq_tfrec.py | Untuk menyiapkan TFRecords untuk kumpulan data CelebA-HQ dengan resolusi 256x256. |
| │ ├ persiapkan_celeba_tfrec.py | Untuk menyiapkan TFRecords untuk kumpulan data CelebA dengan resolusi 128x128. |
| │ ├ persiapkan_mnist_tfrec.py | Untuk menyiapkan TFRecords untuk kumpulan data MNIST. |
| │ ├ split_tfrecords_bedroom.py | Untuk memisahkan TFRecords resmi dari kertas StyleGAN untuk kumpulan data kamar tidur LSUN. |
| │ └ split_tfrecords_ffhq.py | Untuk memisahkan TFRecords resmi dari makalah StyleGAN untuk kumpulan data FFHQ. |
| ├ kumpulan data_sampel | Folder dengan input sampel untuk kumpulan data berbeda. Digunakan untuk angka dan masukan tes selama pelatihan. |
| ├ membuat_angka | Skenario pembuatan berbagai figur. |
| ├ metrik | Skrip untuk menghitung metrik. |
| ├ arah_utama | Skrip untuk menghitung vektor arah utama untuk berbagai atribut. Untuk demo interaktif . |
| ├ gaya_pencampuran | Contoh masukan dan skrip untuk menghasilkan figur percampuran gaya. |
| ├ pelatihan_artefak | Tempat default untuk menyimpan pos pemeriksaan/sampel keluaran/plot. |
| │ └ unduh_all.py | Skrip untuk mengunduh semua model yang telah dilatih sebelumnya. |
| ├ interaktif_demo.py | Skrip yang dapat dijalankan untuk demo interaktif. |
| ├ kereta_alae.py | Skrip yang dapat dijalankan untuk pelatihan. |
| ├ train_alae_separate.py | Skrip yang dapat dijalankan untuk pelatihan studi ablasi (encoder dan diskriminator terpisah). |
| ├ checkpointer.py | Modul untuk menyimpan/memulihkan bobot model, status pengoptimal, dan riwayat kerugian. |
| ├ custom_adam.py | Pengoptimal adam yang disesuaikan untuk pemerataan kecepatan pembelajaran dan beta nol detik. |
| ├ pemuat data.py | Modul dengan kelas kumpulan data, pemuat, iterator, dll. |
| ├ default.py | Definisi untuk variabel konfigurasi dengan nilai default. |
| ├ peluncur.py | Pembantu untuk menjalankan pelatihan multi-GPU dan multiproses. Menyiapkan konfigurasi dan logging. |
| ├ lod_driver.py | Kelas pembantu untuk mengelola jaringan yang berkembang/menstabilkan. |
| ├ lreq.py | Modul Linear , Conv2d , dan ConvTranspose2d khusus untuk pemerataan kecepatan pembelajaran. |
| ├ model.py | Modul dengan definisi model tingkat tinggi. |
| ├ model_separate.py | Sama seperti di atas, tetapi untuk studi ablasi. |
| ├ net.py | Definisi semua blok jaringan untuk berbagai arsitektur. |
| ├ registri.py | Registri blok jaringan untuk dipilih dari file konfigurasi. |
| ├ penjadwal.py | Penjadwal khusus dengan awal yang hangat dan menggabungkan beberapa pengoptimal. |
| ├ pelacak.py | Modul untuk merencanakan kerugian. |
| └ utils.py | Dekorator untuk panggilan async, dekorator untuk caching, registri untuk blok jaringan. |
Dalam basis kode ini yacs digunakan untuk menangani konfigurasi.
Sebagian besar skrip yang dapat dijalankan menerima parameter -c yang dapat menentukan file konfigurasi yang akan digunakan. Misalnya, untuk membuat angka rekonstruksi, Anda dapat menjalankan:
python make_figures/make_recon_figure_paged.py
python make_figures/make_recon_figure_paged.py -c celeba
python make_figures/make_recon_figure_paged.py -c celeba-hq256
python make_figures/make_recon_figure_paged.py -c bedroom
Konfigurasi defaultnya adalah ffhq .
Pelatihan dilakukan menggunakan TFRecords. TFRecords dibaca menggunakan DareBlopy, yang memungkinkan penggunaannya dengan Pytorch.
Dalam file konfigurasi dan juga di semua skrip persiapan, diasumsikan bahwa semua kumpulan data ada di /data/datasets/ . Anda dapat mengubah jalur di file konfigurasi, atau membuat symlink ke tempat Anda menyimpan kumpulan data.
Cara resmi untuk menghasilkan CelebA-HQ bisa jadi menantang. Silakan merujuk ke halaman ini: https://github.com/suvojit-0x55aa/celebA-HQ-dataset-download Anda bisa mendapatkan kumpulan data yang sudah dibuat sebelumnya dari: https://drive.google.com/drive/folders/11Vz0fqHS2rXDb5pprgTjpD7S2BAJhi1P
Untuk mengunduh model terlatih, jalankan:
python training_artifacts/download_all.py
Catatan : Dulu ada masalah saat mengunduh model dari Google Drive karena batas unduhan. Sekarang, skrip telah diatur sedemikian rupa sehingga jika gagal mengunduh data dari Google Drive, ia akan mencoba mengunduhnya dari S3.
Jika Anda mengalami masalah, coba hapus semua file *.pth, perbarui paket dlutils ( pip install dlutils --upgrade ) lalu jalankan download_all.py lagi. Jika itu tidak menyelesaikan masalah, silakan buka masalah. Selain itu, Anda dapat mencoba mengunduh model secara manual dari sini: https://drive.google.com/drive/folders/1tsI1q1u8QRX5t7_lWCSjpniLGlNY-3VY?usp=sharing
Dalam file konfigurasi, OUTPUT_DIR menunjuk ke tempat bobot disimpan dan dibaca. Misalnya: OUTPUT_DIR: training_artifacts/celeba-hq256
Di OUTPUT_DIR ia menyimpan file last_checkpoint yang berisi jalur ke acar .pth aktual dengan bobot model. Jika Anda ingin menguji model dengan file bobot tertentu, Anda cukup memodifikasi file last_checkpoint .
Untuk menghasilkan figur pencampur gaya, jalankan:
python style_mixing/stylemix.py -c <config>
Di mana alih-alih <config> letakkan salah satu dari: ffhq , celeba , celeba-hq256 , bedroom
Untuk menghasilkan rekonstruksi dengan gambar berskala ganda:
python make_figures/make_recon_figure_multires.py -c <config>
Untuk menghasilkan rekonstruksi dari semua masukan sampel di beberapa halaman:
python make_figures/make_recon_figure_paged.py -c <config>
Ada juga:
python make_figures/old/make_recon_figure_celeba.py
python make_figures/old/make_recon_figure_bed.py
Untuk menghasilkan rekonstruksi dari set pengujian FFHQ:
python make_figures/make_recon_figure_ffhq_real.py
Untuk menghasilkan angka interpolasi:
python make_figures/make_recon_figure_interpolation.py -c <config>
Untuk menghasilkan angka traversal:
(Untuk kumpulan data selain FFHQ, Anda perlu mencari petunjuk utama terlebih dahulu)
python make_figures/make_traversarls.py -c <config>
Untuk menjalankan figur generasi:
make_generation_figure.py -c <config>
Selain menginstal paket yang diperlukan:
pip install -r requirements.txt
Anda perlu menginstal DareBlopy:
pip install dareblopy
Untuk menjalankan pelatihan:
python train_alae.py -c <config>
Ini akan menjalankan pelatihan multi-GPU pada semua GPU yang tersedia. Ia menggunakan DistributedDataParallel untuk paralelisme. Jika hanya tersedia satu GPU, maka akan berjalan pada satu GPU, tidak diperlukan perawatan khusus.
Jumlah GPU yang disarankan adalah 8. Reproduksibilitas pada jumlah GPU yang lebih kecil mungkin mengalami masalah. Anda mungkin perlu menyesuaikan ukuran batch di file konfigurasi tergantung pada ukuran memori GPU.
Selain menginstal paket yang diperlukan dan DareBlopy, Anda perlu menginstal TensorFlow dan dnnlib dari StyleGAN.
Tensorflow harus versi 1.10 :
pip install tensorflow-gpu==1.10
Ini membutuhkan CUDA versi 9.0.
Mungkin, cara terbaik adalah menggunakan Anaconda untuk menangani ini, tapi saya lebih suka menginstal CUDA 9.0 dari repositori pop-os (berfungsi di Ubuntu):
sudo echo "deb http://apt.pop-os.org/proprietary bionic main" | sudo tee -a /etc/apt/sources.list.d/pop-proprietary.list
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-key 204DD8AEC33A7AFF
sudo apt update
sudo apt install system76-cuda-9.0
sudo apt install system76-cudnn-9.0
Kemudian atur saja variabel LD_LIBRARY_PATH :
export LD_LIBRARY_PATH=/usr/lib/cuda-9.0/lib64
Dnnlib adalah paket yang digunakan di StyleGAN. Anda dapat menginstalnya dengan:
pip install https://github.com/podgorskiy/dnnlib/releases/download/0.0.1/dnnlib-0.0.1-py3-none-any.whl
Semua kode untuk menjalankan metrik sangat didasarkan pada kode dari repositori StyleGAN. Ini juga menggunakan model terlatih yang sama:
https://github.com/NVlabs/stylegan#licenses
inception_v3_features.pkl dan inception_v3_softmax.pkl berasal dari jaringan Inception-v3 yang telah dilatih sebelumnya oleh Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, dan Zbigniew Wojna. Jaringan ini awalnya dibagikan di bawah lisensi Apache 2.0 pada repositori Model TensorFlow.
vgg16.pkl dan vgg16_zhang_perceptual.pkl berasal dari jaringan VGG-16 yang telah dilatih sebelumnya oleh Karen Simonyan dan Andrew Zisserman. Jaringan ini awalnya dibagikan di bawah lisensi Creative Commons BY 4.0 di halaman proyek Jaringan Konvolusional Sangat Dalam untuk Pengenalan Visual Skala Besar.
vgg16_zhang_perceptual.pkl selanjutnya diturunkan dari beban LPIPS yang telah dilatih sebelumnya oleh Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, dan Oliver Wang. Bobot awalnya dibagikan di bawah Lisensi "Sederhana" Klausul 2 BSD pada repositori PerceptualSimilarity.
Terakhir, untuk menjalankan metrik:
python metrics/fid.py -c <config> # FID score on generations
python metrics/fid_rec.py -c <config> # FID score on reconstructions
python metrics/ppl.py -c <config> # PPL score on generations
python metrics/lpips.py -c <config> # LPIPS score of reconstructions