
[Rekomendasi terkait: Tutorial video JavaScript, front-end web]
Apa pun bahasa pemrograman yang Anda gunakan, string adalah tipe data yang penting. Ikuti saya untuk mempelajari lebih lanjut tentang string JavaScript !
String adalah string yang terdiri dari karakter. Jika Anda pernah mempelajari C dan Java , Anda harus tahu bahwa karakter itu sendiri juga bisa menjadi tipe independen. Namun, JavaScript tidak memiliki tipe karakter tunggal, hanya string dengan panjang 1 .
String JavaScript menggunakan pengkodean UTF-16 tetap, apa pun pengkodean yang kami gunakan saat menulis program, itu tidak akan terpengaruh.
string: tanda kutip tunggal, tanda kutip ganda, dan tanda kutip balik.
let single = 'abcdefg';//Kutipan tunggal let double = "asdfghj";//Kutipan ganda let backti = `zxcvbnm`;//Kutipan balik
tanda kutip tunggal dan ganda mempunyai status yang sama, kami tidak membedakannya.
Backtickspemformatan string
memungkinkan kita memformat string secara elegan menggunakan ${...} alih-alih menggunakan penambahan string.
let str = `Saya ${Math.round(18.5)} tahun.`;console.log(str) ;

string multi-baris
juga memungkinkan string merentang garis, yang sangat berguna saat kita menulis string multi-baris.
let ques = `Apakah penulisnya tampan? A.Sangat tampan; B.Sangat tampan; C. Sangat tampan;`;console.log(ques);
Hasil eksekusi kode:
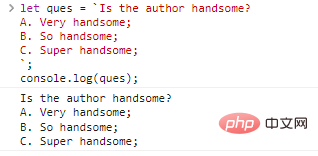
Bukankah sepertinya tidak ada yang salah dengan hal itu? Namun hal ini tidak dapat dicapai dengan menggunakan tanda kutip tunggal dan ganda. Jika Anda ingin mendapatkan hasil yang sama, Anda dapat menulis seperti ini:
let ques = 'Apakah penulisnya tampan?nA. Sangat tampan;nB. Sangat tampan;'; console.log(ques);
Kode di atas berisi karakter khusus n , yang merupakan karakter khusus paling umum dalam proses pemrograman kita.
n juga dikenal sebagai "karakter baris baru", mendukung tanda kutip tunggal dan ganda untuk menghasilkan string multi-baris. Ketika mesin mengeluarkan sebuah string, jika bertemu n , mesin akan terus mengeluarkan output pada baris lain, sehingga menghasilkan string multi-baris.
Meskipun n tampak seperti dua karakter, namun hanya menempati satu posisi karakter. Hal ini karena adalah karakter escape dalam string, dan karakter yang dimodifikasi oleh karakter escape tersebut menjadi karakter khusus.
Daftar karakter khusus
| Deskripsi | karakter khusus |
|---|---|
n | , digunakan untuk memulai baris baru teks keluaran. |
r | carriage return memindahkan kursor ke awal baris. Dalam sistem Windows , rn digunakan untuk mewakili jeda baris, yang berarti kursor harus menuju ke awal baris terlebih dahulu, lalu kemudian ke baris berikutnya sebelum dapat berubah ke baris baru. Sistem lain dapat menggunakan n secara langsung. |
' " | Tanda kutip tunggal dan ganda, terutama karena tanda kutip tunggal dan ganda adalah karakter khusus. Jika kita ingin menggunakan tanda kutip tunggal dan ganda dalam sebuah string, kita harus menghindarinya. |
\ | Garis miring terbalik, juga karena |
b f v | backspace, feed halaman, label vertikal - tidak lagi digunakan |
xXX | adalah karakter Unicode heksadesimal yang dikodekan sebagai XX , misalnya : x7A z Unicode z 7A |
u{X...X} 1-6 | UTF-32 |
uXXXX | u00A9 Unicode XXXX |
pengkodean adalah simbol Unicode dari X...X . |
Misalnya:
console.log('I'ma student.');// 'console.log(""I love U. "");/ / "console.log("\n adalah karakter baris baru.");// nconsole.log('u00A9')// ©console.log('u{1F60D} ');// Kode hasil eksekusi:
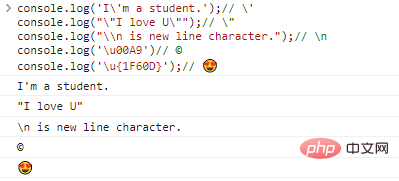
Dengan adanya karakter escape , secara teoritis kita dapat mengeluarkan karakter apa pun, selama kita menemukan pengkodean yang sesuai.
Hindari penggunaan ' dan "
untuk tanda kutip tunggal dan ganda dalam string. Kita dapat dengan cerdik menggunakan tanda kutip ganda di dalam tanda kutip tunggal, menggunakan tanda kutip tunggal di dalam tanda kutip ganda, atau langsung menggunakan tanda kutip tunggal dan ganda di dalam tanda kutip terbalik. Hindari penggunaan karakter escape, misalnya:
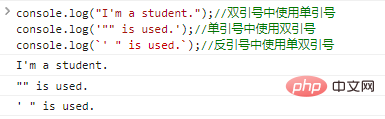
console.log("Saya seorang pelajar.");
//Gunakan tanda kutip tunggal di dalam tanda kutip ganda console.log('"" digunakan.');
//Gunakan tanda kutip ganda dalam tanda kutip tunggal console.log(`' " digunakan.`);
//Hasil eksekusi kode menggunakan tanda kutip tunggal dan ganda pada backticks adalah sebagai berikut:
Melalui properti .length dari string, kita bisa mendapatkan panjang string:
console.log("HelloWorldn".length);//11 n di sini hanya menempati satu karakter.
Pada bab "Metode Tipe Dasar", kita membahas mengapa tipe dasar dalam
JavaScriptmemiliki properti dan metode.
string adalah string karakter. Kita dapat mengakses satu karakter melalui [字符下标] . Subskrip karakter dimulai dari 0 :
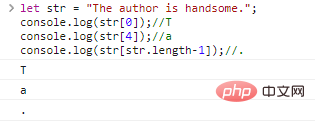
let str = "Penulisnya tampan.";console.log(str[0]);//Tconsole.log(str[4])
;
//aconsole.log(str[str.length-1]);//.
Kita juga dapat menggunakan fungsi charAt(post) untuk mendapatkan karakter:
let str = "Penulisnya tampan.";console.log(str.charAt(0)); //Tconsole.log(str.charAt(4)); //aconsole.log(str.charAt(str.length-1));//.Efek
eksekusi keduanya sama persis, yang membedakan hanya saat mengakses karakter di luar batas:
let str = "01234"; console.log(str[ 9]);//undefinisiconsole.log(str.charAt(9));//"" (string kosong)
Kita juga dapat menggunakan for ..of untuk menelusuri string:
for(let c of '01234'){
console.log(c);} Sebuah string dalam JavaScript tidak dapat diubah setelah didefinisikan. Misalnya:
let str = "Const";str[0] = 'c' ;console.log(str)
; hasil:
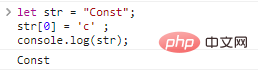
Jika Anda ingin mendapatkan string yang berbeda, Anda hanya dapat membuat yang baru:
let str = "Const";str = str.replace('C','c');console.log
(str);
telah mengubah karakter String, sebenarnya string asli tidak diubah, yang kita dapatkan adalah string baru yang dikembalikan dengan metode replace .
mengonversi kapitalisasi string, atau mengonversi kapitalisasi karakter tunggal dalam string.
Metode untuk kedua string ini relatif sederhana, seperti yang ditunjukkan dalam contoh:
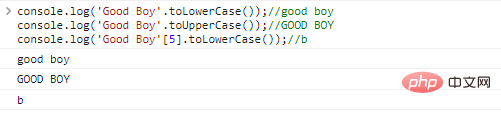
console.log('Good Boy'.toLowerCase());//good
boyconsole.log('Anak Baik'.toUpperCase());//BAIK
BOYconsole.log('Good Boy'[5].toLowerCase());//b hasil eksekusi kode:
Fungsi .indexOf(substr,idx) dimulai dari posisi idx string, mencari posisi substring substr , dan mengembalikan subskrip karakter pertama dari string. substring jika berhasil, atau -1 jika gagal.
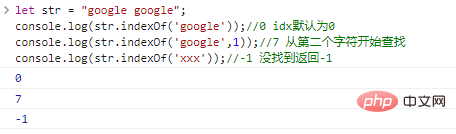
biarkan str = "google google";console.log(str.indexOf('google'));
//0 idx defaultnya adalah 0console.log(str.indexOf('google',1));
//7 Pencarian console.log(str.indexOf('xxx')); dimulai dari karakter kedua.
//-1 tidak ditemukan mengembalikan -1 hasil eksekusi kode:
Jika kita ingin menanyakan posisi semua substring dalam string, kita dapat menggunakan perulangan:
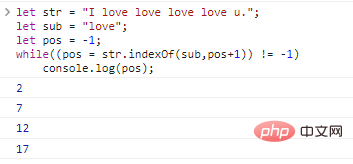
let str = "I love love love love u.";let sub = "love";let pos = -1; while((pos = str.indexOf (sub,pos+1)) != -1)
console.log(pos); Hasil eksekusi kodenya adalah sebagai berikut:
.lastIndexOf(substr,idx) mencari substring mundur, pertama-tama temukan string terakhir yang cocok:
let str = "google google";console.log(str.lastIndexOf('google'));//7 idx defaultnya adalah 0 karena metode indexOf() dan lastIndexOf() akan mengembalikan -1 ketika kueri tidak berhasil, dan ~-1 === 0 . Artinya, penggunaan ~ hanya berlaku jika hasil kuerinya bukan -1 , sehingga kita dapat:
let str = "google google";if(~indexOf('google',str)){
...} Biasanya, kami tidak menyarankan penggunaan sintaksis yang karakteristik sintaksisnya tidak dapat tercermin dengan jelas, karena hal ini akan berdampak pada keterbacaan. Untungnya kode di atas hanya muncul pada kode versi lama. Disebutkan di sini agar semua orang tidak bingung saat membaca kode lama.
Tambahan:
~adalah operator negasi bitwise. Misalnya: bentuk biner dari bilangan desimal2adalah0010, dan bentuk biner dari~2adalah1101(pelengkap), yaitu-3.Cara pemahaman yang sederhana,
~nsetara dengan-(n+1), misalnya:~2 === -(2+1) === -3
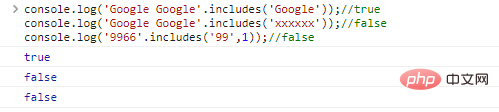
.includes(substr,idx) digunakan untuk menentukan apakah substr ada dalam string. idx adalah posisi awal kueri
console.log('Google Google'.includes('Google'));//trueconsole.log( 'Google Google'. include('xxxxxx'));//falseconsole.log('9966'.includes('99',1));// hasil eksekusi kode salah:
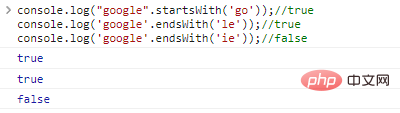
.startsWith('substr') dan .endsWith('substr') masing-masing menentukan apakah string dimulai atau diakhiri dengan substr
console.log("google".startsWith('go'));//trueconsole.log('google' .endsWith('le'));//trueconsole.log('google'.endsWith('ie'));// hasil eksekusi kode salah:
.substr() , .substring() , .slice() semuanya digunakan untuk mendapatkan substring dari string, tetapi penggunaannya berbeda.
.substr(start,len)
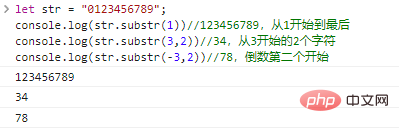
mengembalikan string yang terdiri dari karakter len yang dimulai dari start . Jika len dihilangkan, maka akan dicegat hingga akhir string asli. start dapat berupa angka negatif yang menunjukkan karakter start dari belakang ke depan.
let str = "0123456789";console.log(str.substr(1))//123456789, mulai dari 1 hingga akhir console.log(str.substr(3,2))//34, 2 dimulai dari 3 Karakter console.log(str.substr(-3,2))//78,
hasil eksekusi kode awal kedua dari belakang:
.slice(start,end)
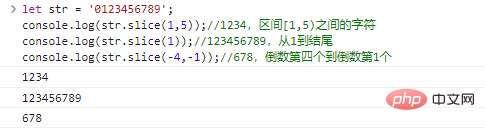
mengembalikan string yang dimulai dari start dan berakhir di end (eksklusif). start dan end dapat berupa angka negatif, yang menunjukkan karakter start/end kedua dari belakang.
let str = '0123456789';console.log(str.slice(1,5));//1234, karakter di antara interval [1,5) console.log(str.slice(1));//123456789 , dari 1 hingga akhir console.log(str.slice(-4,-1));//678,
hasil eksekusi kode keempat hingga terakhir:
.substring(start,end)
hampir sama dengan .slice() . Perbedaannya ada di dua tempat:
end > start diperbolehkan;0;
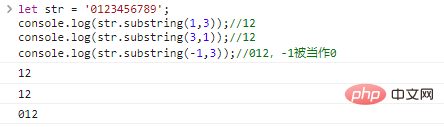
biarkan str = '0123456789'; konsol.log(str .substring(1,3));//12console.log(str.substring(3,1));//12console.log(str.substring(-1, 3));//012, -1 dianggap sebagai
hasil eksekusi kode Make 0:
Bandingkan perbedaan antara ketiganya:
| parameter | deskripsi | metode.slice |
|---|---|---|
.slice(start,end) | [start,end) | bisa negatif.substring |
.substring(start,end) | [start,end) | Nilai negatifnya 0 |
.substr(start,len) | dimulai dari start len | banyak |
metode substring negatif
.slice()len, jadi tentu saja sulit untuk memilihnya.
Kami telah menyebutkan perbandingan string di artikel sebelumnya. String diurutkan berdasarkan urutan kamus. Di belakang setiap karakter terdapat kode, dan kode ASCII adalah referensi penting.
Misalnya:
console.log('a'>'Z');// Perbandingan antara karakter sebenarnya pada dasarnya adalah perbandingan antara pengkodean yang mewakili karakter. JavaScript menggunakan UTF-16 untuk mengkodekan string. Setiap karakter adalah kode 16 bit. Jika Anda ingin mengetahui sifat perbandingannya, Anda perlu menggunakan .codePointAt(idx) untuk mendapatkan pengkodean karakter:
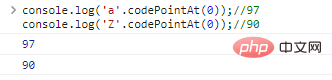
console.log('a '.codePointAt( 0));//97console.log('Z'.codePointAt(0));//90 hasil eksekusi kode:
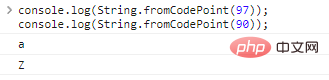
Gunakan String.fromCodePoint(code) untuk mengubah pengkodean menjadi karakter:
String.fromCodePoint
(97));console.log(String.fromCodePoint(90));
Proses ini dapat dicapai dengan menggunakan karakter escape u , sebagai berikut:
console.log('u005a');//Z, 005a adalah notasi heksadesimal dari 90 console.log('u0061');//a, 0061 Ini adalah notasi heksadesimal dari 97. Mari kita jelajahi karakter yang dikodekan dalam rentang [65,220] :
let str = '';for(let i = 65; i<=220; i++){
str+=String.fromCodePoint(i);}console.log(str); Hasil bagian eksekusi kode adalah sebagai berikut:

Gambar di atas tidak menunjukkan semua hasil, jadi coba saja.
didasarkan pada standar internasional ECMA-402 . JavaScript telah menerapkan metode khusus ( .localeCompare() ) untuk membandingkan berbagai string, menggunakan str1.localeCompare(str2) :
str1 < str2 , kembalikan angka negatifstr1 > str2 , kembalikan bilangan positif;str1 == str2 , kembalikan 0;misalnya:
console.log("abc".localeCompare('def'));//-1 Mengapa tidak menggunakan operator perbandingan secara langsung?
Hal ini karena karakter bahasa Inggris mempunyai beberapa cara penulisan khusus. Misalnya, á merupakan varian dari a :
console.log('á' < 'z');// Meskipun false juga merupakan a , namun lebih besar dari z ! !
Saat ini, Anda perlu menggunakan metode .localeCompare() :
console.log('á'.localeCompare('z'));//-1 str.trim() menghapus karakter spasi sebelum dan sesudah string, str.trimStart() , str.trimEnd() menghapus spasi di awal dan akhir;
let str = " 999 "; console.log(str.trim()); //999
str.repeat(n) berulang string n kali;
let str = ' 6';console.log(str.repeat(3));//666
str.replace(substr,newstr) menggantikan substring pertama, str.replaceAll() digunakan untuk mengganti semua substring;
biarkan str = '9 +9';console.log(str.replace('9','6'));//6+9console.log(str.replaceAll('9','6')) ;//6+6masih Ada banyak metode lain dan kita dapat mengunjungi manualnya untuk pengetahuan lebih lanjut.
16 65536 JavaScript UTF-16 untuk mengkodekan string, yaitu, dua byte ( 16 bit) digunakan untuk mewakili satu karakter karakter umum tentu saja tidak disertakan. Mudah dimengerti, tetapi tidak cukup untuk karakter langka (Cina), emoji , simbol matematika langka, dll.
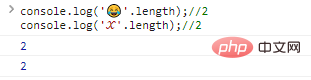
Dalam hal ini, Anda perlu memperluas dan menggunakan digit yang lebih panjang ( 32 bit) untuk mewakili karakter khusus, misalnya:
console.log(''.length);//2console.log('?'.length);//2 hasil Eksekusi kode:
Hasilnya adalah kita tidak dapat memprosesnya menggunakan metode konvensional. Apa yang terjadi jika kita mengeluarkan setiap byte satu per satu?
console.log(''[0]);console.log(''[1]) ;
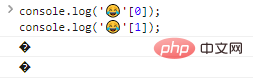
Seperti yang Anda lihat, byte keluaran individual tidak dikenali.
Untungnya, metode String.fromCodePoint() dan .codePointAt() dapat menangani situasi ini karena ditambahkan baru-baru ini. Di versi JavaScript yang lebih lama, Anda hanya dapat menggunakan metode String.fromCharCode() dan .charCodeAt() untuk mengonversi pengkodean dan karakter, tetapi metode tersebut tidak cocok untuk karakter khusus.
Kita dapat menangani karakter khusus dengan menilai rentang pengkodean suatu karakter untuk menentukan apakah karakter tersebut merupakan karakter khusus. Jika kode karakter berada di antara 0xd800~0xdbff , maka itu adalah bagian pertama dari karakter 32 bit, dan bagian kedua harus berada di antara 0xdc00~0xdfff .
Misalnya:
console.log(''.charCodeAt(0).toString(16));//d83
dconsole.log('?'.charCodeAt(1).toString(16));//de02 hasil eksekusi kode:

Dalam bahasa Inggris, terdapat banyak varian berdasarkan huruf, misalnya: huruf a dapat menjadi karakter dasar àáâäãåā . Tidak semua simbol varian ini disimpan dalam pengkodean UTF-16 karena terlalu banyak kombinasi variasi.
Untuk mendukung semua kombinasi varian, beberapa karakter Unicode juga digunakan untuk mewakili satu karakter varian Selama proses pemrograman, kita dapat menggunakan karakter dasar ditambah "simbol dekoratif" untuk mengekspresikan karakter khusus:
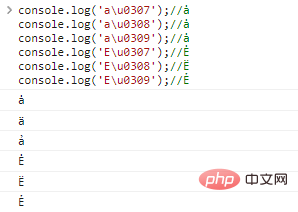
console.log('au0307 ' );//ȧ
console.log('au0308');//ȧ
console.log('au0309');//ȧ
console.log('Eu0307');//Ė
konsol.log('Eu0308');//E
console.log('Eu0309');//ẺCode hasil eksekusi:
Sebuah huruf dasar juga dapat memiliki banyak dekorasi, misalnya:
console.log('Eu0307u0323');//Ẹ̇
console.log('Eu0323u0307');// Hasil eksekusi kode:
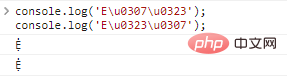
Ada masalah di sini. Dalam kasus beberapa dekorasi, dekorasi disusun secara berbeda, tetapi karakter yang ditampilkan sebenarnya sama.
Jika kita membandingkan kedua representasi ini secara langsung, kita mendapatkan hasil yang salah:
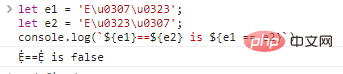
misalkan e1 = 'Eu0307u0323';
misalkan e2 = 'Eu0323u0307';
console.log(`${e1}==${e2} adalah ${e1 == e2}`) hasil eksekusi kode:
Untuk mengatasi situasi ini, ada algoritma normalisasi ** Unicode yang dapat mengubah string menjadi format ** universal, yang diterapkan oleh str.normalize() :
let e1 = 'Eu0307u0323';
misalkan e2 = 'Eu0323u0307';
console.log(`${e1}==${e2} adalah ${e1.normalize() == e2.normalize()}`)
Hasil eksekusi kode:

[Rekomendasi terkait: Tutorial video JavaScript, front-end web]
Di atas adalah konten terperinci dari metode dasar umum string JavaScript. Untuk informasi lebih lanjut, harap perhatikan artikel terkait lainnya di situs web PHP Cina!