Kami merayapi semua informasi halaman web di bagian sebelumnya. Sekarang kita harus menemukan konten yang kita butuhkan dalam kode html. Oleh karena itu, kita perlu memasukkan situs web sesuai dengan masalahnya dan mengurai informasi di halaman web.
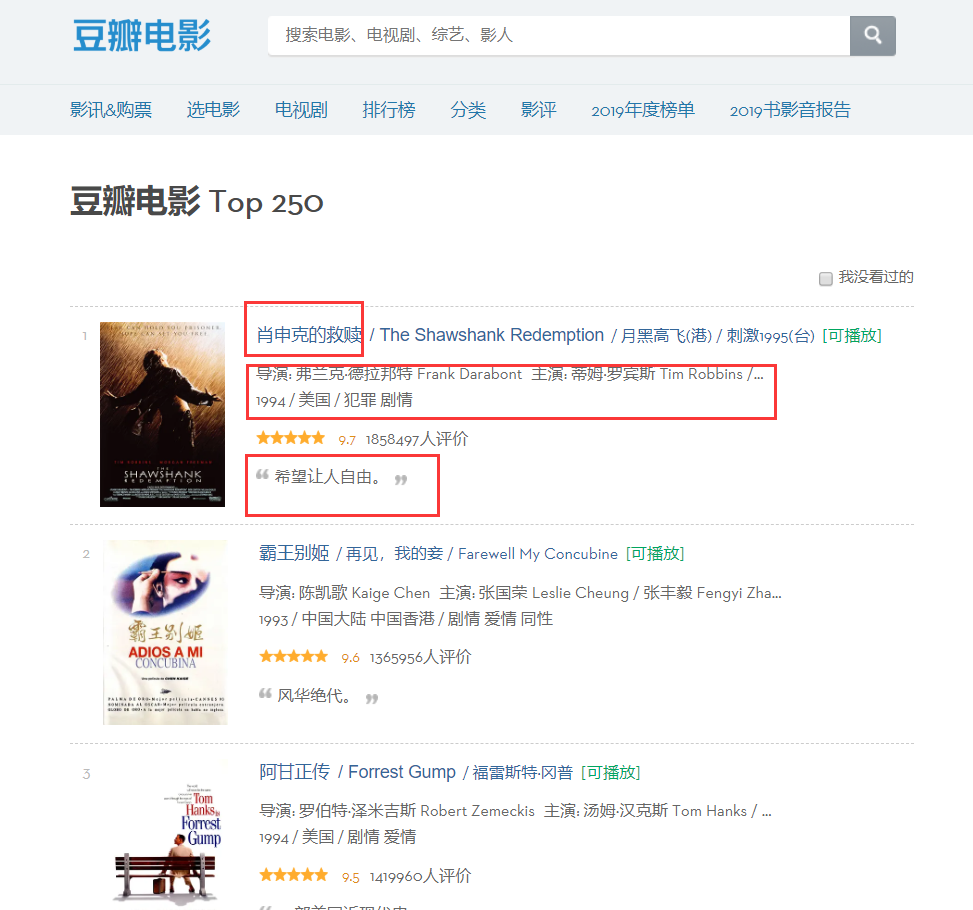
Dari halaman tersebut dapat ditemukan bahwa informasi yang perlu kita jelajahi ada di partisi yang berbeda, jadi mari kita periksa elemen halaman, klik kanan halaman tersebut untuk memeriksa kode sumber halaman web atau F12.

Sebelum menganalisis halaman web, pertama-tama kami menentukan metode penyimpanan setelah penguraian. Di sini kami menggunakan daftar untuk menyimpan semua informasi, dan kemudian setiap item dalam daftar berhubungan dengan kamus, dan setiap kamus berhubungan dengan beberapa jenis informasi.
movie=[]#Pertama tentukan daftar untuk menyimpan semua informasi
Melalui analisa, kita dapat menentukan bahwa posisi judul adalah 'span' pertama di 'a' pertama di bawah 'div' bernama 'hd', sehingga kita dapat mengunci nama setiap film melalui kode berikut, lalu ke dalam kamus.
moviename=each.find('div',class_='hd').a.span.text.strip()movie['title']=moviename#Sebuah item dalam kamusDengan cara yang sama, kode sumber nama sutradara dapat ditemukan berdasarkan positioning, namun kode sumber ini mengandung banyak informasi, sehingga kita perlu memfilternya melalui ekspresi reguler.
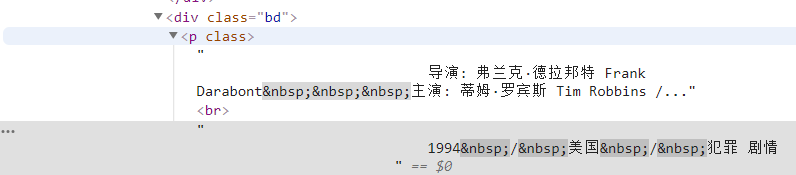
info=setiap.temukan('div',kelas_='bd').p.teks.strip()Pertama, kami menemukan semua konten di bawah tag ini, lalu menyaring informasi yang tidak relevan melalui ekspresi reguler.
info=info.replace('n',)#Filter pengangkutan kembali info=info.replace(,)#Filter spasi info=info.replace(xa0,)#Filter karakter spasi putih yang tidak terputus direktur=re.findall( r '[Sutradara:].+[Dibintangi:]',info)[0]direktur=direktur[3:len(direktur)-6]Kemudian definisikan sebagai item dalam kamus.
movie['director']=director#Item dalam kamus
Kita dapat menemukan bahwa jenis film juga ada dalam tag 'p' ini, dan kita juga memperoleh informasi ini secara langsung melalui ekspresi reguler.
plot=re.findall(r'[0-9]*[/].+[/].+',info)[0]plot=plot[1:]plot=plot[plot.index('/') +1:]plot=plot[plot.index('/')+1:]movie['plot']=plot#Tambahkan sebagai item dalam kamusTerakhir, kunci informasi rating.
star=each.find('div',class_='star')star=star.find('span',class_='rating_num').text.strip()Kemudian lanjutkan menyimpannya dalam bentuk kamus.
film['bintang']=bintang
Terakhir, tambahkan kamus ini ke daftar dan ulangi hasilnya.
movie.append(movie)#Tambahkan kamus ke daftar untukiinmovies:#Melintasi output print(i)
importreimportrequestsfrombs4importBeautifulSoupforiinrange(1):headers={#Simulasikan browser untuk mengakses'agen-pengguna':'Mozilla/5.0(WindowsNT6.1;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/52.0.2743.82Safari/537. 36','Host':'movie.douban.com'}res='https://movie.douban.com/top250?start='+str(25*i)#25 kali r=requests.get(res ,headers=headers,timeout=10)#Setel batas waktu sup=BeautifulSoup(r.text,html.parser)#Setel metode parsing, metode lain juga dapat digunakan. div_list=soup.find_all('div',class_='item')movies=[]foreachindiv_list:movie={}moviename=each.find('div',class_='hd').a.span.text.strip ()film['judul']=movienamerank=each.find('div',class_='pic').em.text .strip()movie['rank']=rankinfo=each.find('div',class_='bd').p.text.strip()info=info.replace('n',)info=info .replace(,)info=info.replace(xa0,)director=re.findall(r'[Direktur:].+[Dibintangi:]',info)[0]director=director [3:len(sutradara)-6]film['director']=directorrelease_date=re.findall(r'[0-9]{4}',info)[0]film['release_date']=release_dateplot=re .findall(r'[0-9]*[/].+[/].+',info)[0]plot=plot[1:]plot=plot[plot.index(' /')+1:]plot=plot[plot.index('/')+1:]film['plot']=plotstar=each.find('div',class_='star')star=star. find('span',class_='rating_num').text.strip()movie['star']=starmovies.append(movie)foriinmovies:print(i)Menghibur:

Dalam contoh ini, kita terutama mempelajari cara menemukan informasi terkait dalam kode sumber halaman web. BeautifulSoup dapat membantu kita menemukannya dengan cepat, dan kemudian menggabungkannya dengan ekspresi reguler untuk menyelesaikan pencocokan informasi akan menyimpan data ini ke database.