Model bahasa multi-modal terbaru BLIP-3-Video yang dirilis oleh tim peneliti Salesforce AI memberikan solusi untuk memproses data video yang terus bertambah secara efisien. Model ini bertujuan untuk meningkatkan efisiensi dan efek pemahaman video, dan banyak digunakan di berbagai bidang seperti mengemudi otonom dan hiburan, serta menghadirkan inovasi ke semua lapisan masyarakat. Editor Downcodes akan menjelaskan secara detail teknologi inti dan kinerja luar biasa dari BLIP-3-Video.
Baru-baru ini, tim peneliti Salesforce AI meluncurkan model bahasa multi-modal baru-BLIP-3-Video. Dengan pesatnya peningkatan konten video, cara memproses data video secara efisien telah menjadi masalah yang mendesak untuk dipecahkan. Kemunculan model ini bertujuan untuk meningkatkan efisiensi dan efektivitas pemahaman video serta cocok untuk berbagai industri mulai dari berkendara otonom hingga hiburan.
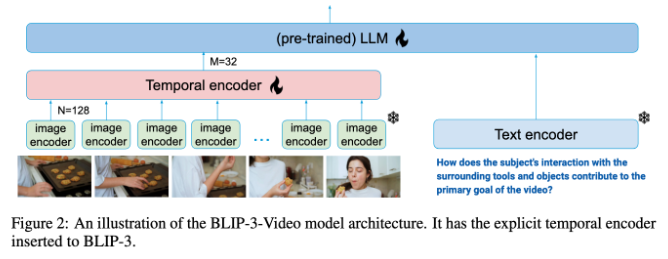
Model pemahaman video tradisional sering kali memproses video bingkai demi bingkai dan menghasilkan sejumlah besar informasi visual. Proses ini tidak hanya menghabiskan banyak sumber daya komputasi, tetapi juga sangat membatasi kemampuan memproses video berdurasi panjang. Seiring dengan bertambahnya jumlah data video, pendekatan ini menjadi semakin tidak efisien, sehingga penting untuk menemukan solusi yang menangkap informasi penting dari video sekaligus mengurangi beban komputasi.
Dalam hal ini, kinerja BLIP-3-Video cukup baik. Model ini berhasil mengurangi jumlah informasi visual yang diperlukan dalam video menjadi 16 hingga 32 penanda visual dengan memperkenalkan "temporal encoder". Desain inovatif ini sangat meningkatkan efisiensi komputasi, memungkinkan model menyelesaikan tugas video kompleks dengan biaya lebih rendah. Encoder temporal ini menggunakan mekanisme pengumpulan perhatian spatiotemporal yang dapat dipelajari yang mengekstrak informasi paling penting dari setiap frame dan mengintegrasikannya ke dalam serangkaian penanda visual yang ringkas.
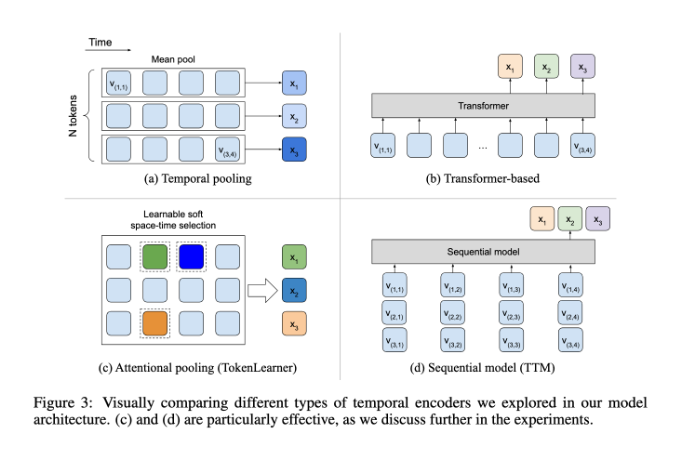
BLIP-3-Video juga berkinerja sangat baik. Dengan membandingkan dengan model berskala besar lainnya, penelitian ini menemukan bahwa keakuratan model ini dalam tugas menjawab pertanyaan video sebanding dengan model teratas. Misalnya model Tarsier-34B membutuhkan 4608 marker untuk memproses 8 frame video, sedangkan BLIP-3-Video hanya membutuhkan 32 marker untuk mencapai skor benchmark MSVD-QA sebesar 77,7%. Hal ini menunjukkan bahwa BLIP-3-Video secara signifikan mengurangi konsumsi sumber daya sekaligus mempertahankan kinerja tinggi.
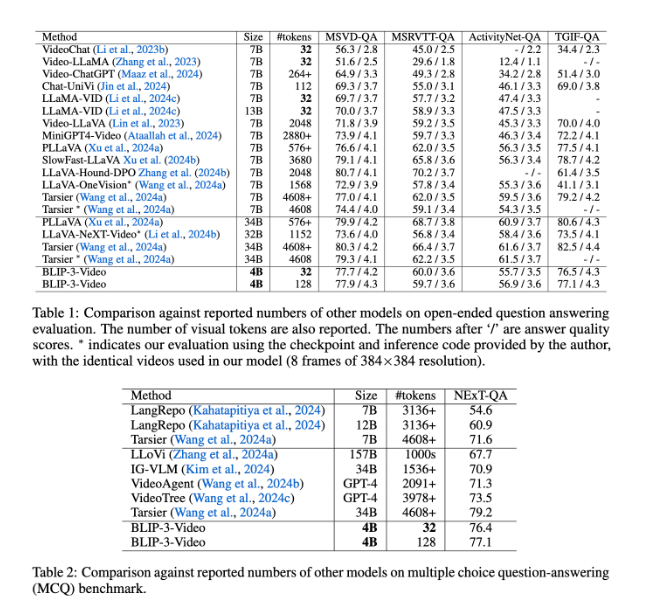
Selain itu, kinerja BLIP-3-Video dalam tugas tanya jawab pilihan ganda tidak bisa dianggap remeh. Pada kumpulan data NExT-QA, model mencapai skor tinggi sebesar 77,1%, dan pada kumpulan data TGIF-QA, model tersebut juga mencapai akurasi sebesar 77,1%. Data ini menunjukkan efisiensi BLIP-3-Video dalam menangani permasalahan video yang kompleks.

BLIP-3-Video membuka kemungkinan baru dalam pemrosesan video dengan encoder waktu yang inovatif. Peluncuran model ini tidak hanya meningkatkan efisiensi pemahaman video, namun juga memberikan lebih banyak kemungkinan untuk aplikasi video masa depan.
Pintu masuk proyek: https://www.salesforceairesearch.com/opensource/xGen-MM-Vid/index.html
BLIP-3-Video memberikan arah baru bagi pengembangan teknologi video masa depan dengan kemampuan pemrosesan video yang efisien. Kinerjanya yang luar biasa dalam video tanya jawab dan tugas tanya jawab pilihan ganda menunjukkan potensi besarnya dalam penghematan sumber daya dan peningkatan kinerja. Kami menantikan BLIP-3-Video berperan di lebih banyak bidang dan mempromosikan kemajuan teknologi video.