Editor Downcodes akan menjelaskan kepada Anda hasil penelitian terbaru dari Universitas Princeton dan Universitas Yale! Penelitian ini mengeksplorasi secara mendalam kemampuan penalaran "Chain of Thought (CoT)" dari model bahasa besar (LLM), mengungkapkan bahwa penalaran CoT bukanlah penerapan aturan logis yang sederhana, tetapi perpaduan kompleks dari beberapa faktor seperti memori, probabilitas, dan alasan kebisingan. Para peneliti memilih tugas shift cipher cracking dan melakukan analisis mendalam terhadap tiga LLM: GPT-4, Claude3 dan Llama3.1. Akhirnya, mereka menemukan tiga faktor kunci yang mempengaruhi efek inferensi CoT, dan mengusulkan mekanisme inferensi LLM. wawasan baru.
Para peneliti dari Universitas Princeton dan Universitas Yale baru-baru ini merilis laporan tentang kemampuan penalaran "Rantai Pemikiran (CoT)" dari model bahasa besar (LLM), yang mengungkap rahasia penalaran CoT: ini bukan penalaran simbolis murni berdasarkan aturan logis, tetapi Ini menggabungkan beberapa faktor seperti memori, probabilitas dan penalaran kebisingan.
Para peneliti menggunakan cracking shift cipher sebagai tugas pengujian dan menganalisis kinerja tiga LLM: GPT-4, Claude3 dan Llama3.1. Shift cipher adalah pengkodean sederhana di mana setiap huruf diganti dengan huruf yang digeser ke depan sejumlah tempat dalam alfabet. Misalnya, memajukan alfabet 3 tempat, dan CAT menjadi PLRT Asing.
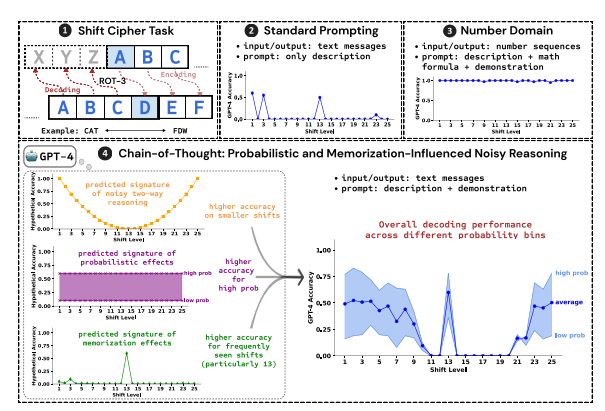
Hasil penelitian menunjukkan bahwa tiga faktor utama yang mempengaruhi efek penalaran CoT adalah:
Probabilistik: LLM lebih memilih untuk menghasilkan keluaran dengan probabilitas yang lebih tinggi, meskipun langkah inferensi menghasilkan jawaban dengan probabilitas yang lebih rendah. Misalnya, jika langkah inferensi menunjuk ke STAZ, namun STAY adalah kata yang lebih umum, LLM mungkin "mengoreksi diri sendiri" dan menghasilkan STAY.
Memori: LLM mengingat sejumlah besar data teks selama pra-pelatihan, yang mempengaruhi keakuratan inferensi CoT-nya. Misalnya, rot-13 adalah shift cipher yang paling umum, dan keakuratan LLM pada rot-13 jauh lebih tinggi dibandingkan jenis shift cipher lainnya.
Inferensi kebisingan: Proses inferensi LLM tidak sepenuhnya akurat, tetapi terdapat tingkat kebisingan tertentu. Ketika jumlah pergeseran cipher pergeseran meningkat, langkah-langkah perantara yang diperlukan untuk decoding juga meningkat, dan dampak inferensi kebisingan menjadi lebih jelas, menyebabkan keakuratan LLM menurun.
Para peneliti juga menemukan bahwa penalaran CoT LLM bergantung pada pengkondisian diri, yaitu LLM perlu secara eksplisit menghasilkan teks sebagai konteks untuk langkah penalaran selanjutnya. Jika LLM diinstruksikan untuk "berpikir diam-diam" tanpa mengeluarkan teks apa pun, kemampuan penalarannya berkurang secara signifikan. Selain itu, efektivitas langkah-langkah demonstrasi memiliki dampak yang kecil terhadap penalaran CoT. Bahkan jika ada kesalahan dalam langkah-langkah demonstrasi, efek penalaran CoT dari LLM masih dapat tetap stabil.
Studi ini menunjukkan bahwa penalaran CoT LLM bukanlah penalaran simbolis yang sempurna, namun menggabungkan beberapa faktor seperti penalaran memori, probabilitas dan kebisingan. LLM menunjukkan karakteristik master memori dan master probabilitas selama proses penalaran CoT. Penelitian ini membantu kita mendapatkan pemahaman yang lebih mendalam tentang kemampuan penalaran LLM dan memberikan wawasan berharga untuk mengembangkan sistem AI yang lebih kuat di masa depan.
Alamat makalah: https://arxiv.org/pdf/2407.01687
Laporan penelitian ini memberikan referensi berharga bagi kita untuk memahami mekanisme penalaran "rantai berpikir" dari model bahasa besar, dan juga memberikan arah baru untuk desain dan optimalisasi sistem AI di masa depan. Editor Downcodes akan terus memperhatikan perkembangan terkini di bidang kecerdasan buatan dan memberikan Anda konten yang lebih menarik!