Tim peneliti dari Institut Inovasi Komputasi Universitas Zhejiang telah membuat terobosan dalam memecahkan masalah kurangnya kemampuan model bahasa besar untuk memproses data tabular dan meluncurkan model baru TableGPT2. Dengan encoder tabel uniknya, TableGPT2 dapat memproses berbagai data tabel secara efisien, membawa perubahan revolusioner pada aplikasi berbasis data seperti intelijen bisnis (BI). Redaksi Downcodes akan menjelaskan secara detail inovasi dan arah pengembangan TableGPT2 ke depan.
Munculnya model bahasa besar (LLM) telah membawa perubahan revolusioner pada aplikasi kecerdasan buatan. Namun, model tersebut memiliki kekurangan yang jelas dalam memproses data tabular. Untuk mengatasi masalah ini, tim peneliti dari Institut Inovasi Komputasi Universitas Zhejiang telah meluncurkan model baru yang disebut TableGPT2, yang dapat mengintegrasikan dan memproses data tabular secara langsung dan efisien, membuka jalan baru bagi intelijen bisnis (BI) dan data berbasis data lainnya. kemungkinan-kemungkinan baru.
Inovasi inti TableGPT2 terletak pada encoder tabel uniknya, yang dirancang khusus untuk menangkap informasi struktural dan informasi konten sel tabel, sehingga meningkatkan kemampuan model untuk menangani kueri fuzzy, nama kolom yang hilang, dan tabel tidak beraturan yang umum terjadi di dunia nyata. -aplikasi dunia. TableGPT2 didasarkan pada arsitektur Qwen2.5 dan telah menjalani pra-pelatihan dan penyesuaian skala besar, yang melibatkan lebih dari 593.800 tabel dan 2,36 juta tupel keluaran tabel kueri berkualitas tinggi, yang merupakan skala terkait tabel yang belum pernah terjadi sebelumnya. data pada penelitian sebelumnya.
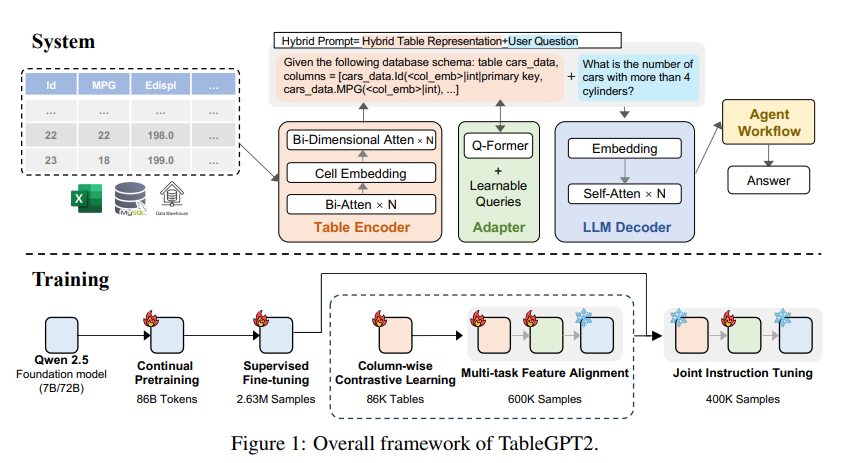
Untuk meningkatkan kemampuan pengkodean dan penalaran TableGPT2, para peneliti melakukan pra-pelatihan berkelanjutan (CPT), di mana 80% data diberi anotasi kode dengan cermat untuk memastikan bahwa data tersebut memiliki kemampuan pengkodean yang kuat. Selain itu, mereka juga mengumpulkan sejumlah besar data inferensi dan buku teks yang berisi pengetahuan khusus domain untuk meningkatkan kemampuan inferensi model. Data CPT akhir berisi 86 miliar token yang difilter secara ketat, yang menyediakan kemampuan pengkodean dan penalaran yang diperlukan bagi TableGPT2 untuk menangani tugas BI yang kompleks dan tugas terkait lainnya.
Untuk mengatasi keterbatasan TableGPT2 dalam beradaptasi dengan tugas dan skenario BI tertentu, para peneliti melakukan penyempurnaan terawasi (SFT) terhadapnya. Mereka membangun kumpulan data yang mencakup berbagai skenario penting dan dunia nyata, termasuk berbagai putaran percakapan, penalaran kompleks, penggunaan alat, dan kueri yang sangat berorientasi bisnis. Kumpulan data ini menggabungkan anotasi manual dengan proses anotasi otomatis yang digerakkan oleh pakar untuk memastikan kualitas dan relevansi data. Proses SFT, menggunakan total 2,36 juta sampel, menyempurnakan model lebih lanjut untuk memenuhi kebutuhan spesifik BI dan lingkungan lain yang melibatkan tabel.
TableGPT2 juga secara inovatif memperkenalkan encoder tabel semantik yang mengambil seluruh tabel sebagai masukan dan menghasilkan sekumpulan vektor penyematan yang ringkas untuk setiap kolom. Arsitektur ini disesuaikan untuk properti unik data tabular, yang secara efektif menangkap hubungan antara baris dan kolom melalui mekanisme perhatian dua arah dan proses ekstraksi fitur hierarki. Selain itu, metode pembelajaran kontrastif kolumnar diadopsi untuk mendorong model mempelajari representasi semantik tabular yang bermakna dan sadar struktur.
Untuk mengintegrasikan TableGPT2 secara lancar dengan alat analisis data tingkat perusahaan, para peneliti juga merancang kerangka kerja runtime alur kerja agen. Kerangka kerja ini terdiri dari tiga komponen inti: rekayasa petunjuk runtime, sandbox kode aman, dan modul evaluasi agen, yang bersama-sama meningkatkan kemampuan dan keandalan agen. Alur kerja mendukung tugas analisis data yang kompleks melalui langkah-langkah modular (normalisasi input, eksekusi agen, dan pemanggilan alat) yang bekerja sama untuk mengelola dan memantau kinerja agen. Dengan mengintegrasikan Retrieval Augmented Generation (RAG) untuk pengambilan kontekstual yang efisien dan sandboxing kode untuk eksekusi yang aman, kerangka kerja ini memastikan bahwa TableGPT2 memberikan wawasan yang akurat dan peka konteks dalam permasalahan dunia nyata.
Para peneliti melakukan evaluasi ekstensif terhadap TableGPT2 pada berbagai tolok ukur tabel dan tujuan umum yang banyak digunakan. Hasilnya menunjukkan bahwa TableGPT2 unggul dalam pemahaman, pemrosesan, dan penalaran tabel, dengan peningkatan kinerja rata-rata sebesar 35,20% untuk model parameter 7 miliar, 720. Performa rata-rata model 100 juta parameter meningkat sebesar 49,32%, dengan tetap mempertahankan performa umum yang kuat. Untuk evaluasi yang adil, mereka hanya membandingkan TableGPT2 dengan model open-source dan netral benchmark seperti Qwen dan DeepSeek, memastikan performa model yang seimbang dan serbaguna pada berbagai tugas tanpa melakukan pengujian benchmark apa pun secara berlebihan. Mereka juga memperkenalkan dan merilis sebagian tolok ukur baru, RealTabBench, yang menekankan tabel tidak konvensional, bidang anonim, dan kueri kompleks agar lebih konsisten dengan skenario kehidupan nyata.
Meskipun TableGPT2 mencapai kinerja tercanggih dalam eksperimen, tantangan masih ada dalam penerapan LLM ke lingkungan BI dunia nyata. Para peneliti mencatat bahwa arah penelitian di masa depan meliputi:
Pengkodean khusus domain: Memungkinkan LLM dengan cepat mengadaptasi bahasa khusus domain (DSL) atau kodesemu khusus perusahaan untuk lebih memenuhi kebutuhan spesifik infrastruktur data perusahaan.
Desain Multi-Agen: Jelajahi cara mengintegrasikan beberapa LLM secara efektif ke dalam sistem terpadu untuk menangani kompleksitas aplikasi dunia nyata.
Pemrosesan tabel serbaguna: Meningkatkan kemampuan model untuk menangani tabel tidak beraturan, seperti sel gabungan dan struktur tidak konsisten yang umum di Excel dan Pages, untuk menangani berbagai bentuk data tabular di dunia nyata dengan lebih baik.
Peluncuran TableGPT2 menandai kemajuan signifikan LLM dalam pemrosesan data tabular, menghadirkan kemungkinan baru bagi intelijen bisnis dan aplikasi berbasis data lainnya. Saya yakin seiring dengan semakin mendalamnya penelitian, TableGPT2 akan memainkan peran yang semakin penting dalam bidang analisis data di masa depan.
Alamat makalah: https://arxiv.org/pdf/2411.02059v1
Kemunculan TableGPT2 telah membawa fajar baru dalam bidang intelijen bisnis. Kemampuan pemrosesan data tabelnya yang efisien dan skalabilitas yang kuat menunjukkan bahwa analisis data akan menjadi lebih cerdas dan nyaman di masa depan. Kami berharap TableGPT2 dapat digunakan lebih luas di masa depan dan memberikan nilai lebih bagi semua lapisan masyarakat.