Tim Emu3 dari Zhiyuan Research Institute telah merilis model multi-modal revolusioner Emu3, yang menumbangkan arsitektur model multi-modal tradisional, berlatih hanya berdasarkan prediksi token berikutnya, dan mencapai kinerja SOTA dalam tugas pembangkitan dan persepsi. Tim Emu3 dengan cerdik memberi token pada gambar, teks, dan video ke dalam ruang terpisah dan melatih model Transformer tunggal pada rangkaian multi-modal campuran, mencapai penyatuan tugas multi-modal tanpa bergantung pada arsitektur difusi atau kombinasi, yang menyediakan banyak bidang modal. terobosan baru.
Tim Emu3 dari Zhiyuan Research Institute telah merilis model multi-modal baru Emu3. Model ini dilatih hanya berdasarkan prediksi token berikutnya, menumbangkan model difusi tradisional dan arsitektur model kombinasi, dan mencapai hasil dalam tugas pembangkitan dan persepsi -kinerja seni.
Prediksi token berikutnya telah lama dianggap sebagai jalur yang menjanjikan menuju kecerdasan umum buatan (AGI), tetapi kinerjanya buruk pada tugas multi-modal. Saat ini bidang multimodal masih didominasi oleh model difusi (seperti Difusi Stabil) dan model kombinasi (seperti kombinasi CLIP dan LLM). Tim Emu3 memberi token pada gambar, teks, dan video ke dalam ruang terpisah dan melatih model Transformer tunggal dari awal pada rangkaian multi-modal campuran, sehingga menyatukan tugas-tugas multi-modal tanpa bergantung pada arsitektur difusi atau kombinasional.
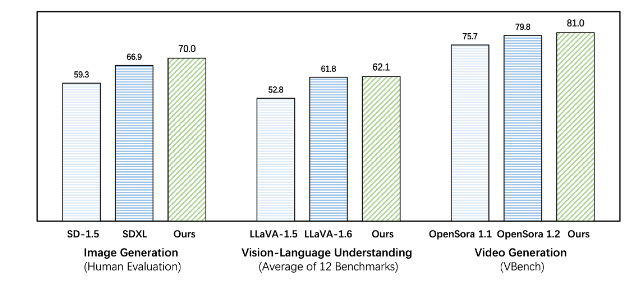
Emu3 mengungguli model tugas spesifik yang ada pada tugas pembangkitan dan persepsi, bahkan melampaui model andalan seperti SDXL dan LLaVA-1.6. Emu3 juga mampu menghasilkan video dengan ketelitian tinggi dengan memprediksi token berikutnya dalam urutan video. Berbeda dengan Sora, yang menggunakan model difusi video untuk menghasilkan video dari noise, Emu3 menghasilkan video secara kausal dengan memprediksi token berikutnya dalam urutan video. Model tersebut dapat mensimulasikan aspek tertentu dari lingkungan dunia nyata, manusia, dan hewan serta memprediksi apa yang akan terjadi selanjutnya berdasarkan konteks video.
Emu3 menyederhanakan desain model multi-modal yang kompleks dan memfokuskan fokus pada token, membuka potensi penskalaan yang besar selama pelatihan dan inferensi. Hasil penelitian menunjukkan bahwa prediksi token berikutnya adalah cara efektif untuk membangun kecerdasan multimodal umum di luar bahasa. Untuk mendukung penelitian lebih lanjut di bidang ini, tim Emu3 memiliki teknologi dan model utama yang bersumber terbuka, termasuk tokenizer visual yang kuat yang dapat mengubah video dan gambar menjadi token terpisah, yang belum pernah tersedia untuk umum sebelumnya.
Keberhasilan Emu3 menunjukkan arah pengembangan model multimodal di masa depan dan membawa harapan baru bagi realisasi AGI.
Alamat proyek: https://github.com/baaivision/Emu3
Editor Downcodes merangkum: Kemunculan model Emu3 menandai tonggak baru dalam bidang multimodal. Arsitekturnya yang sederhana dan kinerjanya yang kuat memberikan ide dan arahan baru untuk penelitian AGI di masa depan. Strategi open source juga mendorong pengembangan bersama antara akademisi dan industri. Patut dinantikan lebih banyak terobosan di masa depan!