ナチュラルスピーチ2
v1.0
NaturalSpeech2 github。最近、Microsoft は新しい大型モデル NaturalSpeech2 を発売すると発表しました。これまでの大型モデルと比較して、NaturalSpeech2 の音声再構成は「より正確」で、「読み取りに固執」せず、ユーザーに優れたエクスペリエンスとサービスを提供します。 。
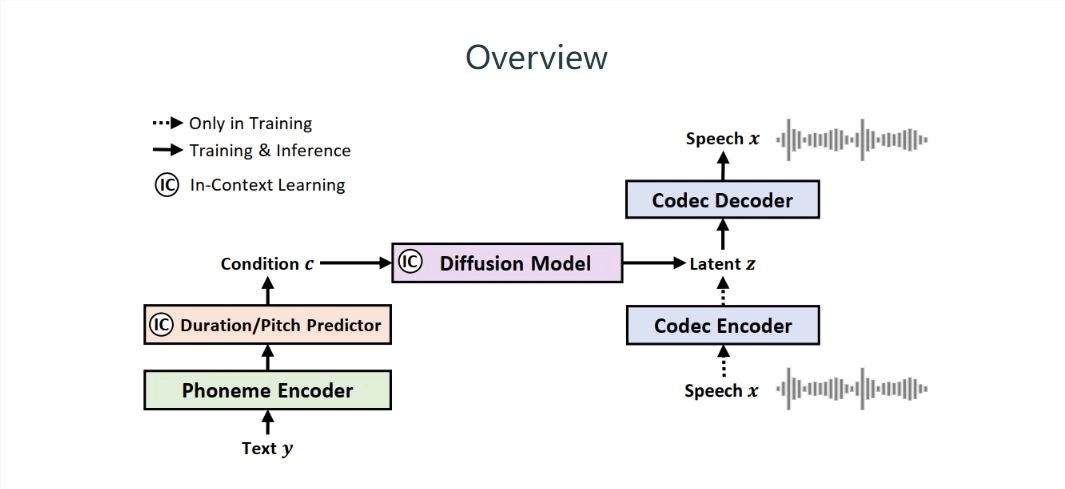
Microsoft は最近、NaturalSpeech2 と呼ばれる音声モデルを発表しました。このモデルは「潜在的拡散」設計を採用しており、ゼロサンプル音声合成レベルで優れた結果をもたらしています。高品質で多様な音声合成体験をユーザーに提供します。
Microsoft は、NaturalSpeech2 の一連のデモンストレーションを実施し、ゼロサンプルの状況でさまざまな話者のアイデンティティ、韻律、スタイル (歌など) を備えた音声を生成する機能を実証しました。
従来の音声合成 (TTS) システムとは異なり、Microsoft の NaturalSpeech2 は音声を表すために「離散マーカー」ではなく「連続ベクトル」を使用するため、より完全な音声セグメントを生成し、「棒読み」を生成しないことが報告されています。感情を欠く「(一言ずつ話す)」現象。
実験結果は、ゼロサンプル条件下で NaturalSpeech2 によって生成された音声が音声プロンプトおよび実際の音声の韻律とほぼ一致しており、LibriTTS および VCTK テスト セットでの自然さ (CMOS によって測定) が実際の音声と区別できないことを示しています。
このプロジェクトの論文は現在 GitHub で公開されています
1.マイクロソフトが正式発売した大型モデル
2. プレイヤーに多くの新しい豊かなインタラクションをもたらします。
3. 現在鋭意開発中ですので、ご期待ください。