TrafficLLMのリポジトリ。これは、現実世界のシナリオにおけるすべてのオープンソース LLM の堅牢なトラフィック表現を学習し、さまざまなトラフィック分析タスク全体の一般化を強化するためのユニバーサル LLM アダプテーション フレームワークです。

注: このコードは ChatGLM2 および Llama2 に基づいています。著者の方々に感謝します。
[2024.10.28] GLM4を使用してChatGLM2よりもチューニングと推論の速度が速いTrafficLLMを構築するための適応コードを更新しました。詳細については、Adapt2GLM4 を参照してください。
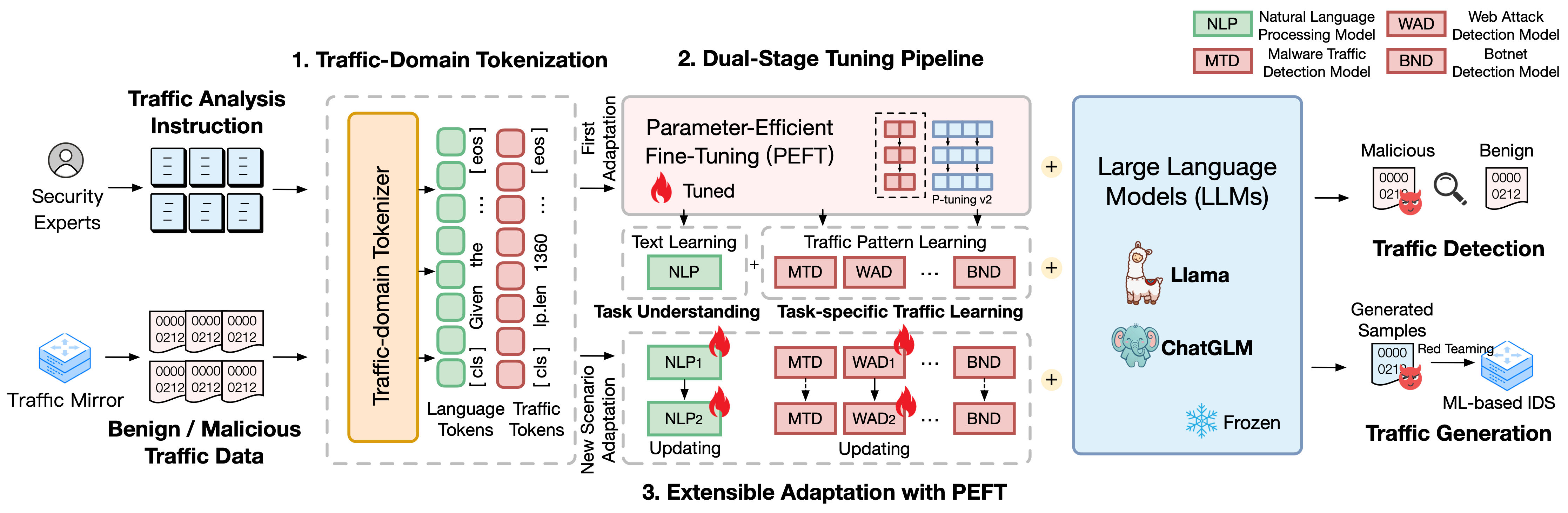
TrafficLLM は、自然言語とトラフィック データを使用した洗練された微調整フレームワークに基づいて構築されており、ネットワーク トラフィック分析における大規模な言語モデルの有用性を高める次の手法を提案しています。
トラフィックドメインのトークン化。自然言語と異種トラフィック データの間のモダリティ ギャップを克服するために、TrafficLLM は、LLM 適応のためのトラフィック検出および生成タスクの多様な入力を処理するトラフィック ドメイン トークン化を導入します。このメカニズムは、大規模なトラフィック ドメイン コーパスに特化したトークン化モデルをトレーニングすることにより、LLM のネイティブ トークナイザーを効果的に拡張します。
デュアルステージ調整パイプライン。 TrafficLLM は、デュアルステージ調整パイプラインを採用して、さまざまなトラフィック ドメイン タスクにわたって LLM の堅牢な表現学習を実現します。パイプラインは、LLM が指示を理解し、さまざまな段階でタスク関連のトラフィック パターンを学習できるようにトレーニングします。これは、TrafficLLM のタスク理解と、さまざまなトラフィック検出および生成タスクのためのトラフィック推論能力に基づいています。
パラメータ効果微調整 (EA-PEFT) による拡張可能な適応。新しいトラフィック環境に一般化するために LLM を適応させるために、TrafficLLM は、低いオーバーヘッドでモデル パラメーターを更新するパラメーター効果的な微調整 (EA-PEFT) を使用した拡張可能な適応を提案します。この手法では、モデルの機能を異なる PEFT モデルに分割するため、トラフィック パターンの変化によって発生する動的シナリオのコストを最小限に抑えることができます。
TrafficLLM のトレーニング データセットをリリースしました。これには、0.4M を超えるトラフィック データと、さまざまなトラフィック分析タスクにわたる LLM 適応のための 9K の人による指示が含まれています。
Instruction Datasets : 命令データセットは、LLM がトラフィック検出または生成タスクのドメイン知識を学習し、さまざまなシナリオでどのタスクを実行する必要があるかを理解するのに役立ちます。
Traffic Datasets : トラフィック データセットには、公開交通データセットから抽出したトラフィック調整データが含まれており、LLM がさまざまなダウンストリーム タスクのトラフィック パターンを学習するのに役立ちます。
TrafficLLM で人間の指示として自然言語コーパスを構築するために、専門家と AI アシスタントによって監督された 9,209 のタスク固有の指示を収集しました。統計は次のように表示されます。
| 主流のタスク | 下流タスク | 略称。 | #サンプル |
|---|---|---|---|
| トラフィックの検出 | マルウェアトラフィックの検出 | MTD | 1.0K |
| ボットネットの検出 | BND | 1.1K | |
| 悪意のある DoH の検出 | MDD | 0.6K | |
| Web攻撃の検出 | 札束 | 0.6K | |
| APT攻撃の検出 | AAD | 0.6K | |
| 暗号化された VPN の検出 | EVD | 1.2K | |
| Tor の動作検出 | 未定 | 0.6K | |
| 暗号化されたアプリの分類 | EAC | 0.6K | |
| ウェブサイトのフィンガープリンティング | WF | 0.6K | |
| コンセプトドリフト | CD | 0.6K | |
| トラフィックの生成 | マルウェアトラフィックの生成 | MTG | 0.6K |
| ボットネットトラフィックの生成 | BTG | 0.1K | |
| 暗号化されたVPNの生成 | EVG | 0.4K | |
| 暗号化されたアプリの生成 | EAG | 0.6K |
さまざまなネットワーク シナリオでの TrafficLLM のパフォーマンスを評価するために、一般に利用可能なトラフィック データセットから 0.400 万を超える調整データを抽出し、悪意のあるトラフィックおよび無害なトラフィックを検出または生成する TrafficLLM の能力を測定しました。統計は次のように表示されます。
| データセット | タスク | 略称。 | #サンプル |
|---|---|---|---|
| USTC TFC 2016 | マルウェアトラフィックの検出 | MTD | 50.7K |
| ISCX ボットネット 2014 | ボットネットの検出 | BND | 25.0K |
| ドHBw 2020 | 悪意のある DoH の検出 | MDD | 47.8K |
| CSIC2010 | Web攻撃の検出 | 札束 | 34.5K |
| DAPT 2020 | APT攻撃の検出 | AAD | 10.0K |
| ISCX VPN 2016 | 暗号化された VPN の検出 | EVD | 64.8K |
| ISCX Tor 2016 | Tor の動作検出 | 未定 | 40.0K |
| CSTNET 2023 | 暗号化されたアプリの分類 | EAC | 97.6K |
| CW-100 2018 | ウェブサイトのフィンガープリンティング | WF | 7.4K |
| APP-53 2023 | コンセプトドリフト | CD | 109.8K |
1. 環境の準備 2. TrafficLLM のトレーニング 2.1.事前トレーニング済みチェックポイントの準備 2.2.データセットの前処理 2.3.トレーニング トラフィック ドメイン トークナイザー (オプション) 2.4.ニューラル言語命令のチューニング 2.5.タスク固有のトラフィック調整 2.6. PEFT による拡張可能な適応 (EA-PEFT) 3. TrafficLLM の評価 3.1.チェックポイントとデータの準備 3.2.実行評価目次:
1. 環境準備 [トップに戻る]
次のコマンドを実行して、リポジトリのクローンを作成し、必要な環境をインストールしてください。
conda create -n Trafficllm python=3.9 conda activate Trafficllm# TrafficLLMgit クローンを複製します https://github.com/ZGC-LLM-Safety/TrafficLLM.gitcd TrafficLLM# 必要なライブラリをインストールしますpip install -rrequirements.txt# trainingpip install rouge_chinese nltk jieba datasets の場合
TrafficLLM は 3 つのコア技術を採用しています: 命令とトラフィック データを処理するトラフィック ドメイン トークン化、テキスト セマンティクスを理解してさまざまなタスクにわたるトラフィック パターンを学習するデュアルステージ調整パイプライン、更新するEA-PEFT新しいシナリオ適応のためのモデルパラメータ。
TrafficLLM は、既存のオープンソース LLM に基づいてトレーニングされます。指示に従ってチェックポイントを準備してください。
ChatGLM2 : 基本モデル ChatGLM を準備します。これは、軽量な展開要件を備えたオープンソースの LLM です。ここから重量をダウンロードしてください。通常、6B パラメーターを備えた v2 モデルを使用します。
Other LLMs : 他の LLM をトラフィック分析タスクに適応させるには、リポジトリ内のトレーニング データを再利用し、公式の指示に従ってトレーニング スクリプトを変更できます。たとえば、新しいデータセットを構成に登録するには、Llama2 が必要です。
生の交通データセットから LLM 学習に適したトレーニング データを抽出するために、さまざまなタスクに合わせて交通データセットを前処理するための専用の抽出器を設計します。前処理コードには、構成する次のパラメーターが含まれています。
input : 生のトラフィック データセット パス (ラベル付きのサブディレクトリを含むメイン ディレクトリ パス。ラベル付きの各サブディレクトリには、前処理される生の .pcap ファイルが含まれます)。
dataset_name : 生のトラフィック データセット名 (名前が TrafficLLM のコードに登録されているかどうかを判断するのに役立ちます)。
traffic_task : 検出タスクまたは生成タスク。
granularity : パケットレベルまたはフローレベルの粒度。
output_path : 出力トレーニング データセットのパス。
output_name : 出力トレーニング データセット名。
これは、パケットレベルのトラフィック検出タスクのために生のトラフィック データセットを前処理するためのインスタンスです。
cd プリプロセス python preprocess_dataset.py --input /Your/Raw/Dataset/Path --dataset_name /Your/Raw/Dataset/Name --traffic_task detect --granularity packet --output_path /Your/Output/Dataset/Path --output_name /Your /Output/Dataset/Name
TrafficLLM は、トラフィック ドメイン トークナイザーを導入して、ニューラル言語とトラフィック データを処理します。独自のデータセットを使用してカスタム トークナイザーをトレーニングする場合は、コード内のmodel_nameとdata_path変更してください。
model_name : ネイティブ トークナイザーを含む基本モデルのパス。
data_path : 前処理プロセスから抽出されたトレーニング データセット。
コードを使用するにはコマンドに従ってください。
cd トークン化 python Traffic_tokenizer.py
データの準備:ニューラル言語命令のチューニング データは、トラフィック分析タスクを理解するために収集された命令データセットです。
チューニングの開始:前述の手順の後、trafficllm_stage1.sh を使用して最初の段階のチューニングを開始できます。以下のような例があります:
PRE_SEQ_LEN=128
LR=2e-2
NUM_GPUS=1エクスポートCUDA_VISIBLE_DEVICES=1
torchrun --standalone --nnodes=1 --nproc-per-node=$NUM_GPUS main.py
--do_train
--train_file ../datasets/instructions/instructions.json
--validation_file ../datasets/instructions/instructions.json
--preprocessing_num_workers 10
--prompt_column 命令
--response_column 出力
--overwrite_cache
--cache_dir ../キャッシュ
--モデル名またはパス ../models/chatglm2/chatglm2-6b
--output_dir ../models/chatglm2/peft/instruction
--overwrite_output_dir
--max_source_length 1024
--max_target_length 32
--per_device_train_batch_size 1
--per_device_eval_batch_size 1
--gradient_accumulation_steps 16
--predict_with_generate
--max_steps 20000
--logging_steps 10
--save_steps 4000
--learning_rate $LR
--pre_seq_len $PRE_SEQ_LEN データの準備:タスク固有のトラフィック調整データセットは、さまざまなダウンストリーム タスクの前処理ステップから抽出されたトレーニング データセットです。
チューニングの開始:前述の手順の後、trafficllm_stage2.sh を使用して第 2 段階のチューニングを開始できます。以下のような例があります:
PRE_SEQ_LEN=128
LR=2e-2
NUM_GPUS=1エクスポートCUDA_VISIBLE_DEVICES=1
torchrun --standalone --nnodes=1 --nproc-per-node=$NUM_GPUS main.py
--do_train
--train_file ../datasets/ustc-tfc-2016/ustc-tfc-2016_detection_packet_train.json
--validation_file ../datasets/ustc-tfc-2016/ustc-tfc-2016_detection_packet_train.json
--preprocessing_num_workers 10
--prompt_column 命令
--response_column 出力
--overwrite_cache
--cache_dir ../キャッシュ
--モデル名またはパス ../models/chatglm2/chatglm2-6b
--output_dir ../models/chatglm2/peft/ustc-tfc-2016-detection-packet
--overwrite_output_dir
--max_source_length 1024
--max_target_length 32
--per_device_train_batch_size 1
--per_device_eval_batch_size 1
--gradient_accumulation_steps 16
--predict_with_generate
--max_steps 20000
--logging_steps 10
--save_steps 4000
--learning_rate $LR
--pre_seq_len $PRE_SEQ_LEN TrafficLLM は EA-PEFT を使用して、拡張可能な適応を使用してパラメータ有効微調整 (PEFT) モデルを編成します。これにより、TrafficLLM が簡単に適応できるようになります。新しい環境。 TrafficLLM アダプターにより、古いモデルを更新したり、新しいタスクを登録したりする柔軟な操作が可能になります。
model_name : ベースモデルのパス。
tuning_data : 新しい環境データセット。
adaptation_task : 更新または登録 (古いモデルを更新するか、新しいタスクを登録します)。
task_name : 更新または挿入されるダウンストリーム タスク名。
マルウェア トラフィック検出 (MTD) タスクを使用して TrafficLLM を更新する例があります。
cd EA-PEFT python ea-peft.py --model_name /Your/Base/Model/Path --tuning_data /Your/New/Dataset/Path --adaptation_task update --task_name MTD
チェックポイント:独自のモデルまたはリリースされたチェックポイントを使用して、TrafficLLM の評価を試みることができます。
データ:前処理ステップでは、テスト データセットを分割し、評価用にさまざまなデータセットのラベル ファイルを構築します。前処理コードを参照してください。
さまざまなダウンストリーム タスクに対する TrafficLLM の有効性を測定するには、評価コードを実行してください。
model_name : ベースモデルのパス。
traffic_task : 検出タスクまたは生成タスク。
test_file : 前処理ステップ中に抽出されたテスト データセット。
label_file : 前処理ステップ中に抽出されたラベル ファイル。
ptuning_path : タスク固有の評価用の PEFT モデル パス。
MTD タスクで評価を実行する例があります。
Python 評価.py --model_name /Your/Base/Model/Path --traffic_task detect --test_file datasets/ustc-tfc-2016/ustc-tfc-2016_detection_packet_test.json --label_file datasets/ustc-tfc-2016/ustc- tfc-2016_label.json --ptuning_path models/chatglm2/peft/ustc-tfc-2016-detection-packet/checkpoints-20000/
TrafficLLM をローカル デバイスに展開できます。まず、トレーニング ステップで収集した PEFT モデルを登録するためのモデル パスを config.json に設定します。 TrafficLLM に 6 つのタスクを登録する例があります:
{ "model_path": "models/chatglm2/chatglm2-6b/", "peft_path": "models/chatglm2/peft/", "peft_set": { "NLP": "命令/チェックポイント-8000/", "MTD": "ustc-tfc-2016-検出パケット/チェックポイント-10000/"、"BND": "iscx-botnet-2014-検出パケット/チェックポイント-5000/"、"WAD": "csic-2010-検出パケット/チェックポイント-6000/"、"AAD": "dapt-2020-detection-packet/checkpoint-20000/"、"EVD": "iscx-vpn-2016-detection-packet/checkpoint-4000/"、"TBD": "iscx-tor-2016-detection-packet /チェックポイント-10000/"
}, "tasks": { "マルウェア トラフィック検出": "MTD"、"ボットネット検出": "BND"、"Web 攻撃検出": "WAD"、"APT 攻撃検出": "AAD"、"暗号化 VPN 検出" ": "EVD"、"Tor 動作検出": "TBD"
}
次に、
inference.py と Trafficllm_server.py のprepromt関数に preprompt を追加する必要があります。プリプロンプトは、タスク固有のトラフィック調整中にトレーニング データで使用されるプレフィックス テキストです。
ターミナル モードで TrafficLLM とチャットするには、次のコマンドを実行できます:
python inference.py --config=config.json --prompt="Your 指示テキスト +: + Traffic Data"
Web
次のコマンドを使用して、TrafficLLM の Web サイト デモを起動します。
streamlit run Trafficllm_server.py
このデモは、TrafficLLM の Web サーバーを実行します。 http://Your-Server-IP:Portにアクセスして、チャットボックスでチャットします。
私たちのフレームワークとコードの基盤として機能する関連作業 ChatGLM2 および Llama2 に多大な感謝を申し上げます。 TrafficLLM の構築設計は、ET-BERT と GraphGPT からインスピレーションを得ています。彼らの素晴らしい作品に感謝します。