bitnet.cpp は、1 ビット LLM (BitNet b1.58 など) の公式推論フレームワークです。これは、CPU 上で 1.58 ビット モデルの高速かつロスレス推論をサポートする、最適化されたカーネル スイートを提供します (NPU と GPU のサポートは今後予定されています)。
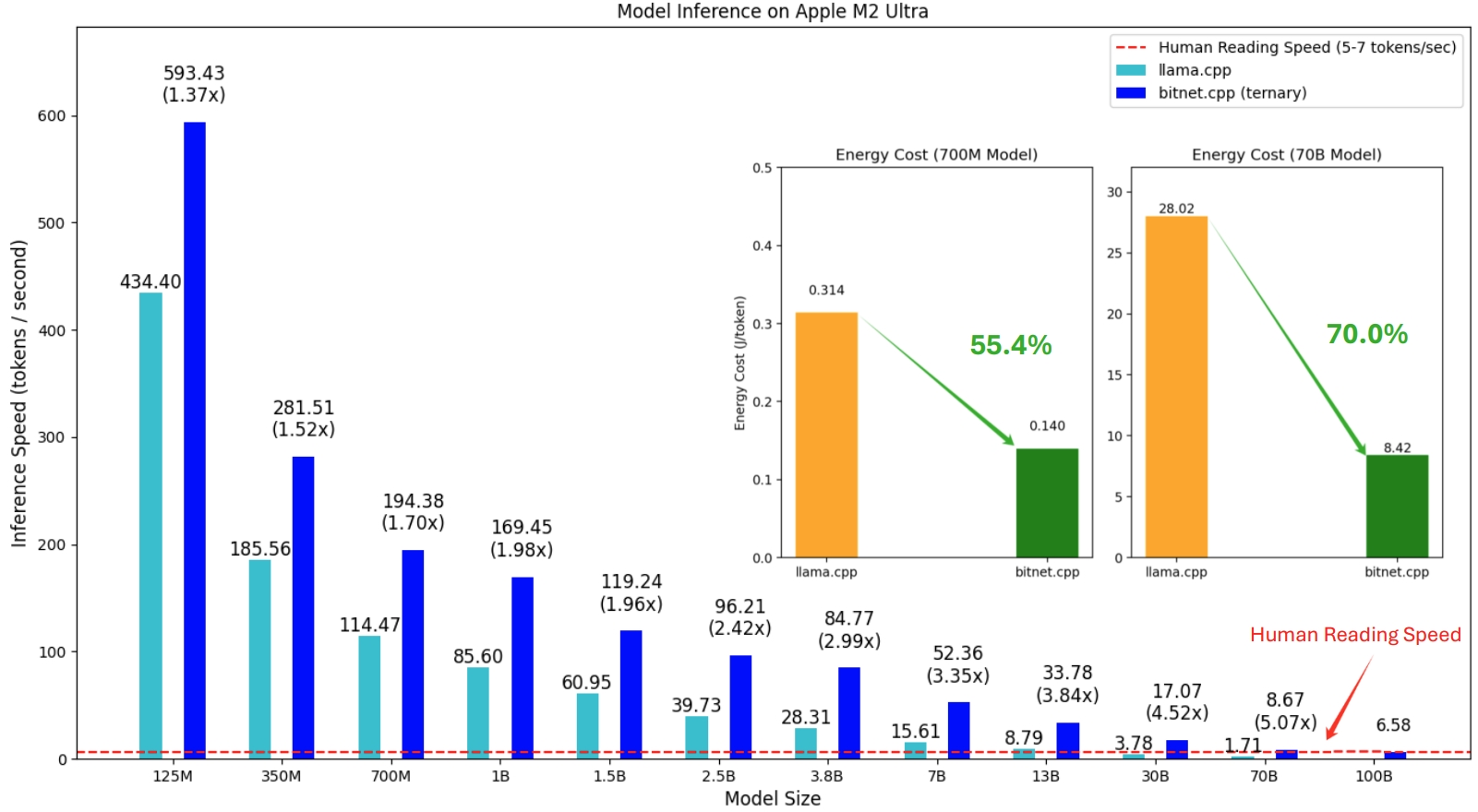
bitnet.cpp の最初のリリースは、CPU での推論をサポートすることです。 bitnet.cpp は、ARM CPU 上で1.37 倍から5.07 倍の高速化を達成し、より大きなモデルではより大きなパフォーマンスの向上が得られます。さらに、エネルギー消費量が55.4% ~ 70.0%削減され、全体の効率がさらに向上します。 x86 CPU では、 2.37 倍から6.17 倍の速度向上が見られ、エネルギーは71.9% ~ 82.2%削減されます。さらに、bitnet.cpp は単一の CPU 上で 100B BitNet b1.58 モデルを実行でき、人間の読み取りに匹敵する速度 (1 秒あたり 5 ~ 7 トークン) を達成し、ローカル デバイス上で LLM を実行する可能性を大幅に高めます。詳細についてはテクニカルレポートを参照してください。


テストされたモデルは、bitnet.cpp の推論パフォーマンスを実証するために研究コンテキストで使用されるダミー セットアップです。
Apple M2 上で BitNet b1.58 3B モデルを実行する bitnet.cpp のデモ:
2024/10/21 1 ビット AI インフラ: パート 1.1、CPU での高速かつロスレス BitNet b1.58 推論
2024 年 10 月 17 日 bitnet.cpp 1.0 がリリースされました。
2024/03/21 1 ビット LLM の時代__Training_Tips_Code_FAQ
2024/02/27 1 ビット LLM の時代: すべての大規模言語モデルは 1.58 ビット
2023/10/17 BitNet: 大規模言語モデル用の 1 ビット トランスフォーマーのスケーリング
このプロジェクトは、llama.cpp フレームワークに基づいています。オープンソース コミュニティへの貢献に感謝します。また、bitnet.cpp のカーネルは、T-MAC で先駆的に開発されたルックアップ テーブル手法に基づいて構築されています。 3 値モデルを超える一般的な低ビット LLM の推論には、T-MAC の使用をお勧めします。
❗️ bitnet.cpp の推論機能を実証するために、Hugging Face で利用可能な既存の 1 ビット LLM を使用します。これらのモデルは Microsoft によってトレーニングもリリースもされていません。 bitnet.cpp のリリースが、モデル サイズとトレーニング トークンの点で大規模な設定における 1 ビット LLM の開発を刺激することを願っています。
| モデル | パラメータ | CPU | カーネル | ||
|---|---|---|---|---|---|
| I2_S | TL1 | TL2 | |||
| bitnet_b1_58-large | 0.7B | x86 | ✔ | ✘ | ✔ |
| アーム | ✔ | ✔ | ✘ | ||
| bitnet_b1_58-3B | 3.3B | x86 | ✘ | ✘ | ✔ |
| アーム | ✘ | ✔ | ✘ | ||
| Llama3-8B-1.58-100B-トークン | 8.0B | x86 | ✔ | ✘ | ✔ |
| アーム | ✔ | ✔ | ✘ | ||
Python>=3.9
cmake>=3.22
カラン>=18
C++ を使用したデスクトップ開発
Windows 用 C++-CMake ツール
Windows 用の Git
Windows 用 C++-Clang コンパイラ
LLVM ツールセット (clang) の MS-Build サポート
Windows ユーザーの場合は、Visual Studio 2022 をインストールします。インストーラーで、少なくとも次のオプションをオンに切り替えます (これにより、CMake などの必要な追加ツールも自動的にインストールされます)。
Debian/Ubuntu ユーザーの場合は、自動インストール スクリプトを使用してダウンロードできます。
bash -c "$(wget -O - https://apt.llvm.org/llvm.sh)"
conda (強くお勧めします)
重要
Windows を使用している場合は、次のコマンドには常に VS2022 の開発者コマンド プロンプト/PowerShell を使用することを忘れないでください。
リポジトリのクローンを作成する
git clone --recursive https://github.com/microsoft/BitNet.gitcd BitNet
依存関係をインストールする
# (推奨) 新しい conda 環境を作成するconda create -n bitnet-cpp python=3.9 conda は bitnet-cpp をアクティブ化します pip install -r 要件.txt
プロジェクトをビルドする
# Hugging Face からモデルをダウンロードし、量子化 gguf 形式に変換し、プロジェクトをビルドしますpython setup_env.py --hf-repo HF1BitLLM/Llama3-8B-1.58-100B-tokens -q i2_s# または、モデルを手動でダウンロードして、ローカル pathhuggingface-cli で実行します。 ダウンロード HF1BitLLM/Llama3-8B-1.58-100B-tokens --local-dir models/Llama3-8B-1.58-100B-tokens python setup_env.py -md models/Llama3-8B-1.58-100B-tokens -q i2_s
使用法: setup_env.py [-h] [--hf-repo {1bitLLM/bitnet_b1_58-large,1bitLLM/bitnet_b1_58-3B,HF1BitLLM/Llama3-8B-1.58-100B-tokens}] [--model-dir MODEL_DIR] [ --log-dir LOG_DIR] [--quant-type {i2_s,tl1}] [--quant-embd]
[--使用-事前調整済み]
推論を実行するための環境をセットアップする
オプションの引数:
-h、--help このヘルプ メッセージを表示して終了します
--hf-repo {1bitLLM/bitnet_b1_58-large,1bitLLM/bitnet_b1_58-3B,HF1BitLLM/Llama3-8B-1.58-100B-トークン}, -hr {1bitLLM/bitnet_b1_58-large,1bitLLM/bitnet_b1_58-3B,HF1BitLLM/Llama3- 8B-1.58-100B-トークン}
推論に使用されるモデル
--model-dir MODEL_DIR、-md MODEL_DIR
モデルを保存/ロードするディレクトリ
--log-dir LOG_DIR、-ld LOG_DIR
ロギング情報を保存するディレクトリ
--quant-type {i2_s,tl1}、-q {i2_s,tl1}
量子化タイプ
--quant-embd エンベディングを f16 に量子化します。
--use-pretuned, -p 事前調整されたカーネル パラメーターを使用します。# 量子化されたモデルで推論を実行するpython run_inference.py -m models/Llama3-8B-1.58-100B-tokens/ggml-model-i2_s.gguf -p "ダニエルは庭に戻りました。メアリーはキッチンに行きました。サンドラサンドラは廊下に行き、ジョンは寝室に行きました。メアリーは庭に戻りました。n 答え:" -n 6 -temp 0# 出力:# ダニエルは庭に戻りました。メアリーはキッチンへ行きました。サンドラはキッチンへ向かいました。サンドラは廊下へ行きました。ジョンは寝室へ行きました。メアリーは庭に戻りました。メアリーはどこですか?# 答え: メアリーは庭にいます。
使用法: run_inference.py [-h] [-m MODEL] [-n N_PREDICT] -p PROMPT [-t THREADS] [-c CTX_SIZE] [-temp TEMPERATURE]
推論を実行する
オプションの引数:
-h、--help このヘルプ メッセージを表示して終了します
-m モデル、--モデル モデル
モデルファイルへのパス
-n N_PREDICT、--n-predict N_PREDICT
テキスト生成時に予測するトークンの数
-p プロンプト、--prompt プロンプト
テキストを生成するよう求めるプロンプト
-t スレッド、--threads スレッド
使用するスレッドの数
-c CTX_SIZE、--ctx-size CTX_SIZE
プロンプトコンテキストのサイズ
-temp 温度、--temp 温度
温度、生成されるテキストのランダム性を制御するハイパーパラメータモデルを提供する推論ベンチマークを実行するためのスクリプトを提供します。
usage: e2e_benchmark.py -m MODEL [-n N_TOKEN] [-p N_PROMPT] [-t THREADS] Setup the environment for running the inference required arguments: -m MODEL, --model MODEL Path to the model file. optional arguments: -h, --help Show this help message and exit. -n N_TOKEN, --n-token N_TOKEN Number of generated tokens. -p N_PROMPT, --n-prompt N_PROMPT Prompt to generate text from. -t THREADS, --threads THREADS Number of threads to use.
各引数の簡単な説明は次のとおりです。
-m 、 --model : モデル ファイルへのパス。これは、スクリプトの実行時に指定する必要がある必須の引数です。
-n 、 --n-token : 推論中に生成するトークンの数。これはオプションの引数で、デフォルト値は 128 です。
-p 、 --n-prompt : テキストの生成に使用するプロンプト トークンの数。これはオプションの引数で、デフォルト値は 512 です。
-t 、 --threads : 推論の実行に使用するスレッドの数。これはオプションの引数であり、デフォルト値は 2 です。
-h 、 --help : ヘルプ メッセージを表示して終了します。この引数を使用して、使用法情報を表示します。
例えば:
python utils/e2e_benchmark.py -m /path/to/model -n 200 -p 256 -t 4
このコマンドは、 /path/to/modelにあるモデルを使用して推論ベンチマークを実行し、4 つのスレッドを利用して 256 トークン プロンプトから 200 トークンを生成します。
パブリック モデルでサポートされていないモデル レイアウトについては、指定されたモデル レイアウトでダミー モデルを生成し、マシン上でベンチマークを実行するためのスクリプトが提供されています。
python utils/generate-dummy-bitnet-model.py models/bitnet_b1_58-large --outfile models/dummy-bitnet-125m.tl1.gguf --outtype tl1 --model-size 125M# 生成されたモデルでベンチマークを実行します。 -m でモデルのパスを指定し、-p で処理されるプロンプトを指定します。-n で生成するトークンの数を指定します。python utils/e2e_benchmark.py -m models/dummy-bitnet-125m.tl1.gguf -p 512 -n 128