Magika は、AI を活用した新しいファイル タイプ検出ツールであり、最近の深層学習の進歩に依存して正確な検出を提供します。 Magika は内部的に、わずか数 MB の高度に最適化されたカスタム Keras モデルを採用しており、単一の CPU で実行している場合でも、数ミリ秒以内に正確なファイル識別を可能にします。
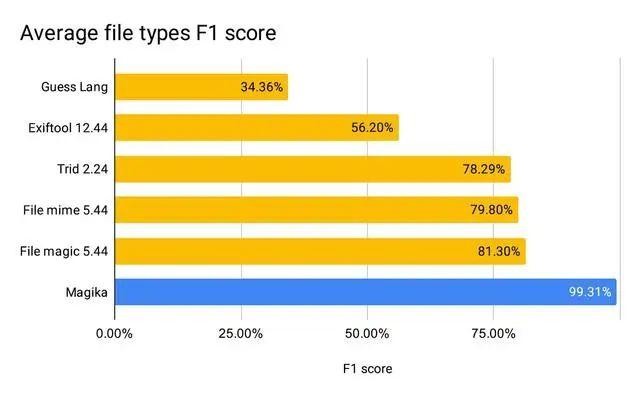
100 万を超えるファイルと 100 を超えるコンテンツ タイプ (バイナリ ファイル形式とテキスト ファイル形式の両方をカバー) を使用した評価で、Magica は 99% 以上の精度と再現率を達成しました。 Magika は、Gmail、ドライブ、セーフ ブラウジング ファイルを適切なセキュリティ スキャナとコンテンツ ポリシー スキャナにルーティングすることで、Google ユーザーの安全性を向上させるために大規模に使用されています。詳細については研究論文をご覧ください。
ブラウザでローカルに実行される Web デモを使用すると、何もインストールせずに Magika を試すことができます。
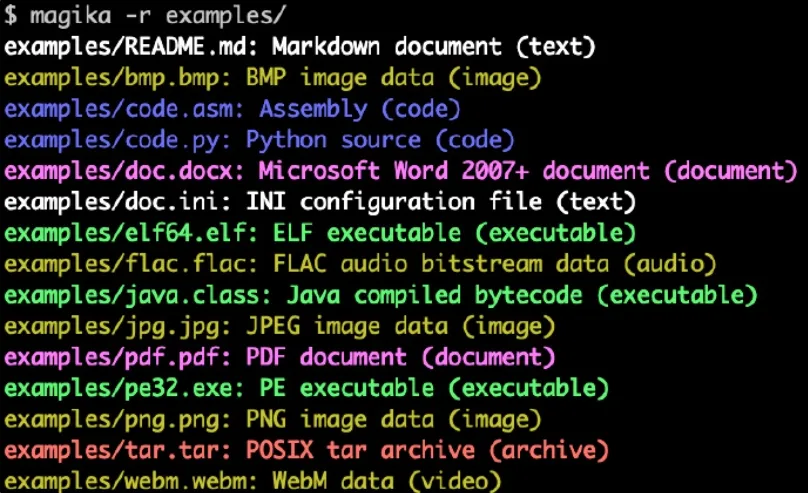
以下は、Magica コマンド ライン出力の例です。
詳細については、Google の OSS ブログでの最初の発表の投稿をご覧ください。

重要
私たちはこれから多くの新しいものをリリースする予定であり、それらはテストする準備ができています。
200 を超えるコンテンツ タイプをサポートする新しい ML モデル。
Rust で書かれた新しい CLI。これは、Python で書かれた以前の CLI を置き換えます。詳細については、こちらをご覧ください。 Rust コードベースは、Rust で書かれたアプリケーションにも使用できます。ドキュメントを参照してください。
Python パッケージ 0.6.0rc1: このバージョンには、200 以上のコンテンツ タイプをサポートする新しいモデル、Rust で書かれた CLI (Python で書かれた古いものを置き換える)、およびいくつかの重大な変更を加えた改良された Python API が同梱されています。ドキュメントを参照してください。そして変更ログ!安定版リリースに関するドキュメントが必要な場合は、ここで最新の安定版タグにあるこのリポジトリを参照してください。
Rust で書かれたコマンド ライン ツール、Python API、Rust API、および実験的な TFJS バージョン (Web デモを強化する) として利用できます。
100 を超えるコンテンツ タイプにわたる 2,500 万を超えるファイルのデータセットでトレーニングされました。
私たちの評価では、Magika は 99% 以上の平均精度と再現率を達成し、既存のアプローチを上回っています。
200 を超えるコンテンツ タイプ (完全なリストを参照)。
モデルがロードされた後 (これは 1 回限りのオーバーヘッドです)、推論時間はファイルごとに約 5 ミリ秒です。
バッチ処理: コマンド ラインと API に複数のファイルを同時に渡すことができ、Magika はバッチ処理を使用して推論時間を短縮します。数千のファイルでも Magika を同時に呼び出すことができます。 -r使用してディレクトリを再帰的にスキャンすることもできます。
ファイルサイズに関係なくほぼ一定の推論時間。 Magika は、ファイルのバイトの限られたサブセットのみを使用します。
Magika は、モデルの予測を「信頼する」かどうか、または「汎用テキスト ドキュメント」や「不明なバイナリ データ」などの汎用ラベルを返すかどうかを決定する、コンテンツ タイプごとのしきい値システムを使用します。
エラーに対する許容度を微調整する 3 つの異なる予測モード ( high-confidence 、 medium-confidence 、 best-guessをサポートします。
それはオープンソースです! (そして、さらに多くのことがまだ起こります。)
詳細については、python パッケージおよび js パッケージのドキュメント (dev docs) を参照してください。
はじめる
Python コマンドライン
Python API
実験的な TFJS モデルと npm パッケージ
インストール
Docker 上で実行する
使用法
開発セットアップ
重要な文書
既知の制限と貢献
よくある質問
追加リソース
研究論文と引用
ライセンス
免責事項
Magika は PyPI でmagikaとして利用できます。
$ pip インストールマジカ
Magika をコマンド ラインとしてのみ使用する場合は、代わりに$ pipx install magika使用するとよいでしょう。
git clone https://github.com/google/magika cd magika/ docker build -t magika . docker run -it --rm -v $(pwd):/magika magika -r /magika/tests_data
新しいコマンドラインは Rust で書かれており、 magika python パッケージで入手できます。
例:
$ cd testing_data/basic && magika -r *asm/code.asm: アセンブリ (コード) バッチ/simple.bat: DOS バッチ ファイル (コード) c/code.c: C ソース (コード) css/code.css: CSSソース(コード) csv/magika_test.csv:CSVドキュメント(コード) dockerfile/Dockerfile: Dockerfile (コード) docx/doc.docx: Microsoft Word 2007+ ドキュメント (ドキュメント) epub/doc.epub: EPUB ドキュメント (ドキュメント) epub/magika_test.epub: EPUB ドキュメント (ドキュメント) flac/test.flac: FLACオーディオビットストリームデータ(オーディオ) handlebars/example.handlebars: ハンドルバーのソース (コード) html/doc.html: HTML ドキュメント (コード) ini/doc.ini: INI 設定ファイル (テキスト) javascript/code.js: JavaScript ソース (コード) jinja/example.j2: Jinja テンプレート (コード) jpeg/magika_test.jpg:JPEG画像データ(画像) json/doc.json: JSONドキュメント(コード) latex/sample.tex: LaTeX ドキュメント (テキスト) makefile/simple.Makefile: Makefile ソース (コード) markdown/README.md: マークダウンドキュメント(テキスト) [...]
$ magika ./tests_data/basic/python/code.py --json
[
{ "path": "./tests_data/basic/python/code.py", "result": { "status": "ok", "value": { "dl": { "description": "Python ソース" , "拡張子": [ "py", "pyi"
]、"group": "code"、"is_text": true、"label": "python"、"mime_type": "text/x-python"
}, "出力": { "説明": "Python ソース", "拡張機能": [ "py", "pyi"
]、"group": "code"、"is_text": true、"label": "python"、"mime_type": "text/x-python"
}, "スコア": 0.753000020980835
}
}
}
】$ cat doc.ini |マギカ - -: INI設定ファイル(テキスト)
$ マジカ --ヘルプ
ディープラーニングを使用してファイルのコンテンツタイプを判断します
使用法: magika [オプション] [パス]...
引数: [パス]...
分析するファイルへのパスのリスト。
標準入力から読み取るにはダッシュ (-) を使用します (一度のみ使用可能)。
オプション:
-r、--再帰的
ディレクトリ自体を識別するのではなく、ディレクトリ内のファイルを識別します
--逆参照なし
シンボリック リンクをたどってコンテンツを識別するのではなく、そのままのシンボリック リンクを識別します。
- 色
端末のサポートに関係なくカラーで印刷します
--色なし
端末のサポートに関係なく色なしで印刷します
-s、--出力スコア
コンテンツタイプに加えて予測スコアを出力します
-i、--mime-type
コンテンツタイプの説明の代わりにMIMEタイプを出力します。
-l、--ラベル
コンテンツタイプの説明の代わりに単純なラベルを印刷します。
--json
JSON形式で印刷します
--jsonl
JSONL形式で印刷します
--format <カスタム>
カスタム形式を使用して印刷します (詳細については --help を使用してください)。
次のプレースホルダーがサポートされています。
%p ファイルパス
%l コンテンツ タイプを識別する一意のラベル
%d コンテンツ タイプの説明
%g コンテンツ タイプのグループ
%m コンテンツ タイプの MIME タイプ
%e コンテンツ タイプに使用できるファイル拡張子
%s ファイルのコンテンツ タイプのスコア
%S ファイルのコンテンツ タイプのスコア (パーセント単位)
%b 無効な場合はモデル出力 (無効な場合は空)
%% リテラル %
-h、--ヘルプ
ヘルプを印刷します (「-h」で概要を参照)
-V、--バージョン
印刷版詳細なドキュメントについては、ここを参照してください。
例:
>>> from magika import Magika>>> m = Magika()>>> res = m.identify_bytes(b"# Examplenこれはマークダウンの例です!")>>> print(res.output.label)markdown
詳細なドキュメントについては、Python のドキュメントを参照してください。
Web アプリでの使用に興味がある人向けに、実験的なパッケージとして Magika も提供しています。 Magika JS 実装のパフォーマンスは大幅に遅くなり、ファイルごとに 100 ミリ秒以上かかることが予想されることに注意してください。
詳細については、js ドキュメントを参照してください。
Python ドキュメントの「開発セットアップ」セクションを参照してください。
CLI に関するドキュメント
新しいRust CLIに関するドキュメント
さまざまな言語のバインディングに関するドキュメント
サポートされているコンテンツ タイプのリスト (v1 の場合、さらに追加される予定)。
新しいモデルでサポートされるコンテンツ タイプのリスト
Magika の出力を解釈する方法に関するドキュメント。
よくある質問
Magika は最先端技術よりも大幅に改善されていますが、常に改善の余地があります。検出の精度、追加のコンテンツ タイプのサポート、より多くの言語のバインディングなどを向上させるために、さらに多くの作業を行うことができます。
この最初のリリースは多言語検出をターゲットとしていないため、コミュニティからの敵対的な例を確認することを楽しみにしています。また、発生した問題、誤検出、機能のリクエスト、追加のコンテンツ タイプのサポートの必要性などについてコミュニティからの意見もお待ちしています。
オープンしている GitHub の問題をチェックしてロードマップに記載されている内容を確認し、GitHub の問題をオープンする (推奨) か、[email protected] に電子メールを送信して、誤検出や機能リクエストを報告してください。
注: PII が含まれる可能性のあるファイルに関するレポートは送信しないでください。レポートにはファイルの内容の (ほんの一部) が含まれます。
詳細については、 CONTRIBUTING.md参照してください。
いくつかの FAQ をここに集めました。
Magika の発表に関する Google の OSS ブログ投稿。
ウェブデモ: ウェブデモ。
Magika を開発した方法と、研究論文で行った選択について説明します。
このソフトウェアを研究に使用する場合は、次のように引用してください。
@misc{magika, title={{Magika: AI を活用したコンテンツ タイプの検出}}、author={{Fratantonio、Yanick と Invernizzi、Luca と Farah、Loua と Kurt、Thomas と Zhang、Marina と Albertini、Ange と Galilee 、フランソワとメティティエリ、ジャンカルロとクレタン、ジュリアンとプティビアンコ、アレクサンドルとタオ、デヴィッドとブルシュテイン、エリー}}、年={2024}、eprint={2409.13768}、archivePrefix={arXiv}、primaryClass={cs. CR}、url={https://arxiv.org/abs/2409.13768}、
}[email protected] まで直接ご連絡ください。
アパッチ2.0;詳細については、 LICENSEを参照してください。
このプロジェクトは Google の公式プロジェクトではありません。これは Google によってサポートされておらず、Google はその品質、商品性、または特定の目的への適合性に関するすべての保証を特に否認します。