自動ラウンド
Intel®
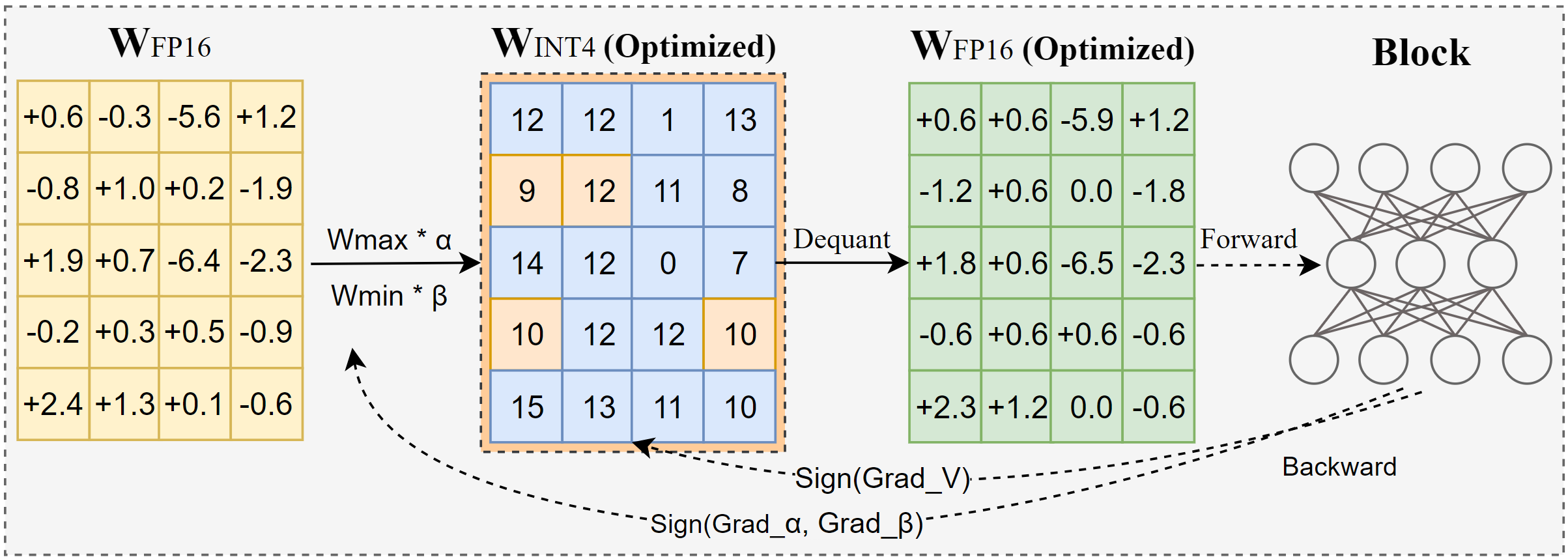
AutoRound は、低ビット LLM 推論用の高度な量子化アルゴリズムです。幅広いモデルに合わせて調整されています。 AutoRound は、符号勾配降下法を採用して丸め値と重みの最小最大値をわずか 200 ステップで微調整します。これは、追加の推論オーバーヘッドを導入せず、チューニング コストを低く抑えることなく、最近の方法と見事に競合します。以下の図は、AutoRound の概要を示しています。詳細については arxiv の論文を参照し、さまざまなモデルにわたるより正確なデータとレシピについては low_bit_open_llm_leaderboard にアクセスしてください。


[2024/10] AutoRound が torch/ao に統合されました。リリースノートを確認してください。
[2024/10] 重要な更新: フルレンジ対称量子化をサポートし、それをデフォルト構成にしました。この構成は通常、非対称量子化よりも優れているか同等であり、特に 2 ビットのような低いビット幅では、他の対称バリアントよりも大幅に優れています。
[2024/09] AutoRound 形式はいくつかの LVM モデルをサポートしています。例を確認してください。Qwen2-Vl、Phi-3-vision、Llava
[2024/08] AutoRound 形式が Intel Gaudi2 デバイスをサポートしました。 Intel/Qwen2-7B-int4-inc を参照してください。
[2024/08] AutoRound は、ノルム/バイアス パラメーター (2 ビットおよび W4A4 用) の高速調整、アクティベーション量子化、mx_fp データ型など、いくつかの実験的な機能を導入しました。
pip install -vvv --no-build-isolation -e 。
pip インストール自動ラウンド
サポートされている引数の完全なリストを詳しく説明したユーザー ガイドは、端末でauto-round -h呼び出すことによって提供されます。あるいは、 auto-roundの代わりにauto_round使用することもできます。 formatに必要な形式を設定し、複数の形式のエクスポートがサポートされています。
CUDA_VISIBLE_DEVICES=0 自動ラウンド
--モデルフェイスブック/opt-125m
-- ビット 4
--グループサイズ 128
--format "auto_round、auto_gptq"
--disable_eval
--output_dir ./tmp_autoround低メモリでも最高の精度と高速な実行速度を実現する 2 つのレシピが提供されています。詳細は以下の通り。
## 最高の精度、3 倍遅い、low_gpu_mem_usage は最大 20G を節約できますが、最大 30% 遅くなりますCUDA_VISIBLE_DEVICES=0 auto-round --モデルフェイスブック/opt-125m -- ビット 4 --グループサイズ 128 --nsamples 512 --イター 1000 --low_gpu_mem_usage --disable_eval
## 高速かつ低メモリ、2 ~ 3 倍の高速化、W4G128CUDA_VISIBLE_DEVICES=0 自動ラウンドで精度がわずかに低下 --モデルフェイスブック/opt-125m -- ビット 4 --グループサイズ 128 --nsamples 128 --イター 200 --シーケンス 512 --バッチサイズ 4 --disable_eval
AutoRound 形式: この形式は、CPU、HPU デバイス、2 ビット、および混合精度推論に適しています。 [2,4] ビットがサポートされています。また、Marlin カーネルの恩恵も受け、推論パフォーマンスを著しく向上させることができます。ただし、コミュニティではまだ広く普及していません。
AutoGPTQ 形式: この形式は CUDA デバイスでの対称量子化に適しており、コミュニティで広く採用されており、[2,3,4,8] ビットがサポートされています。また、Marlin カーネルの恩恵も受け、推論パフォーマンスを著しく向上させることができます。ただし、非対称カーネルには、特に 2 ビット量子化や小規模モデルの場合に、精度の大幅な低下を引き起こす可能性がある問題があります。さらに、対称量子化は 2 ビット精度ではパフォーマンスが低下する傾向があります。
AutoAWQ 形式: この形式は CUDA デバイスでの非対称 4 ビット量子化に適しており、コミュニティ内で広く採用されています。サポートされているのは 4 ビット量子化のみです。 Llama モデルに合わせた特殊なレイヤー フュージョンが特徴です。
トランスフォーマーから import AutoModelForCausalLM, AutoTokenizermodel_name = "facebook/opt-125m"model = AutoModelForCausalLM.from_pretrained(model_name)tokenizer = AutoTokenizer.from_pretrained(model_name)from auto_round import AutoRoundbits, group_size, sym = 4, 128, Trueautoround = AutoRound(model, tokenizer) 、bits=bits、group_size=group_size、sym=sym)## 最高の精度、3 倍遅い、low_gpu_mem_usage は ~20G を節約できますが、~30% 遅くなります# autoround = AutoRound(model, tokenizer, nsamples=512, iters=1000, low_gpu_mem_usage =True、bits=bits、group_size=group_size、sym=sym)## 高速かつ低メモリ、2 ~ 3 倍の高速化、W4G128 で精度がわずかに低下# autoround = AutoRound(model, tokenizer, nsamples=128, iters=200, seqlen) =512、batch_size=4、bits=bits、group_size=group_size、sym=sym )autoround.quantize()output_dir = "./tmp_autoround"## format= 'auto_round' (バージョン > 0.3.0 のデフォルト)、'auto_gptq ', 'auto_awq'autoround.save_quantized(output_dir, format='auto_round', inplace=True)
テストは、PyTorch 2.6.0.dev20241029+cu124 のナイトリー バージョンを使用して、Nvidia A100 80G で実施されました。データ読み込みや梱包にかかる費用は評価対象外となりますのでご了承ください。 Torch 2.6 では torch.compile を有効にしますが、問題が発生したため 2.5 では有効にしません。
GPU メモリの使用量を最適化するには、 low_gpu_mem_usageをアクティブにすることに加えて、 gradient_accumulate_steps=8およびbatch_size=1を設定できますが、これにより調整時間が長くなる可能性があります。
3B および 14B モデルは Qwen 2.5 で評価され、8X7B モデルは Mixtral であり、残りのモデルは LLaMA 3.1 を利用しました。
| トーチのバージョン/構成 W4G128 | 3B | 8B | 14B | 70B | 8X7B |
|---|---|---|---|---|---|
| 2.6 トーチコンパイルあり | 7分 10GB | 12分 18GB | 23分 22GB | 120分 42GB | 28分 46GB |
| 2.6 トーチコンパイルあり low_gpu_mem_usage=True | 12分 6GB | 19分 10GB | 33分 11GB | 140分 25GB | 38分 36GB |
| 2.6 トーチコンパイルあり low_gpu_mem_usage=True gradient_accumulate_steps=8,bs=1 | 15分 3GB | 25分 6GB | 45分 7GB | 187分 19GB | 75分 36GB |
| 2.5 (トーチコンパイルなし) | 8分 10GB | 16分 20GB | 30分 25GB | 140分 49GB | 50分 49GB |
最初に量子化コードを実行してください
CPU : auto_round バージョン >0.3.1 、 pip install intel-extension-for-pytorch (Intel CPU でははるかに高速) または pip install intel-extension-for-transformers、
HPU : Gaudi Software Stack を使用した docker イメージが推奨されます。詳細については、Gaudi ガイドをご覧ください。
CUDA : sym 量子化には追加の操作はありません。asym 量子化の場合は、ソースから自動ラウンドをインストールする必要があります。
from トランスフォーマー import AutoModelForCausalLM、AutoTokenizerfrom auto_round import AutoRoundConfigbackend = "auto" ##cpu、hpu、cuda、cuda:marlin (auto_round>0.3.1 および 'pip install -v gptqmodel --no-build-isolation' でサポート)quantization_config = AutoRoundConfig(backend=backend)quantized_model_path = "./tmp_autoround"model = AutoModelForCausalLM.from_pretrained(quantized_model_path, device_map=backend.split(':')[0], quantization_config=quantization_config)tokenizer = AutoTokenizer.from_pretrained(quantized_model_path)text = "冒険好きな女の子がいます。"inputs = tokenizer(text, return_tensors="pt").to(model.device)print(tokenizer.decode(model.generate(**inputs, max_new_tokens=50)[0]) )自動丸め --model 保存された_quantized_model
--eval
--タスクlambada_openai
--eval_bs 1from トランスフォーマー import AutoModelForCausalLM, AutoTokenizerquantized_model_path = "./tmp_autoround"model = AutoModelForCausalLM.from_pretrained(quantized_model_path, device_map="auto")tokenizer = AutoTokenizer.from_pretrained(quantized_model_path)text = "冒険が好きな女の子がいます。"inputs = tokenizer( text, return_tensors="pt").to(model.device)print(tokenizer.decode(model.generate(**inputs, max_new_tokens=50)[0]))
AutoRound は基本的にすべての主要な大規模言語モデルをサポートします。
アスタリスク (*) はサードパーティの量子化モデルを示しており、精度データが不足していたり、別のレシピが使用されている可能性があることに注意してください。私たちは彼らの努力に非常に感謝しており、モデルのほとんどを私たち自身でリリースすることができないため、より多くのユーザーがモデルを共有することを奨励します。
| モデル | サポートされています |
|---|---|
| メタラマ/メタラマ-3.1-70B-命令 | レシピ |
| metal-llama/Meta-Llama-3.1-8B-Instruct | モデル-kaitchup-autogptq-int4*、モデル-kaitchup-autogptq-sym-int4*、レシピ |
| メタラマ/メタラマ-3.1-8B | モデル-kaitchup-autogptq-sym-int4* |
| クウェン/クウェン-VL | 精度、レシピ |
| クウェン/クウェン2-7B | モデル-autoround-sym-int4、モデル-autogptq-sym-int4 |
| クウェン/Qwen2-57B-A14B-命令 | モデル-autoround-sym-int4、モデル-autogptq-sym-int4 |
| 01-ai/Yi-1.5-9B | モデル-LnL-AI-autogptq-int4* |
| 01-ai/Yi-1.5-9B-チャット | モデル-LnL-AI-autogptq-int4* |
| インテル/ニューラルチャット-7b-v3-3 | モデル-autogptq-int4 |
| インテル/ニューラルチャット-7b-v3-1 | モデル-autogptq-int4 |
| TinyLlama-1.1B-中間 | モデル-LnL-AI-autogptq-int4* |
| ミストラライ/ミストラル-7B-v0.1 | モデル-autogptq-lmhead-int4、モデル-autogptq-int4 |
| google/gemma-2b | モデル-autogptq-int4 |
| ティウアエ/ファルコン-7b | モデル-autogptq-int4-G64 |
| sapienzanlp/modello-italia-9b | モデル-fbaldassarri-autogptq-int4* |
| マイクロソフト/ファイ-2 | モデル-autoround-sym-int4 モデル-autogptq-sym-int4 |
| Microsoft/Phi-3.5-mini-instruct | モデル-kaitchup-autogptq-sym-int4* |
| Microsoft/Phi-3-vision-128k-instruct | レシピ |
| ミストラライ/Mistral-7B-Instruct-v0.2 | 精度、レシピ、例 |
| ミストラライ/Mixtral-8x7B-Instruct-v0.1 | 精度、レシピ、例 |
| ミストラライ/Mixtral-8x7B-v0.1 | 精度、レシピ、例 |
| メタラマ/メタラマ-3-8B-命令 | 精度、レシピ、例 |
| google/gemma-7b | 精度、レシピ、例 |
| メタラマ/ラマ-2-7b-チャット-hf | 精度、レシピ、例 |
| Qwen/Qwen1.5-7B-チャット | 精度、対称レシピ、非対称レシピ、例 |
| baichuan-inc/baichuan2-7B-Chat | 精度、レシピ、例 |
| 01-ai/Yi-6B-チャット | 精度、レシピ、例 |
| フェイスブック/オプト-2.7b | 精度、レシピ、例 |
| ビッグサイエンス/ブルーム-3b | 精度、レシピ、例 |
| エレウザーAI/gpt-j-6b | 精度、レシピ、例 |
AutoRound は複数のリポジトリに統合されています。
インテル ニューラル コンプレッサー
モデルクラウド/GPTQモデル
pytorch/ao
AutoRound が研究に役立つと思われる場合は、私たちの論文を引用してください。
@article{cheng2023最適化、
title={LLM の量子化のための符号付き勾配降下による重み丸めの最適化},
author={チェン、ウェンファとチャン、ウェイウェイとシェン、ハイハオとカイ、イーヤンとヘ、シンとLv、カオカオとリウ、イー}、
ジャーナル={arXiv プレプリント arXiv:2309.05516},
年={2023}
}