論文:視覚言語モデルのテスト時のゼロショット一般化について: 迅速な学習は本当に必要ですか? 。
著者: マキシム・ザネラ、イスマイル・ベン・アイド。
これは、CVPR '24 で採択された論文の公式 GitHub リポジトリです。この研究では、迅速な学習を必要とせずに視覚言語モデルを活用する、MeanShift テスト時間拡張 (MTA) メソッドを導入します。私たちの方法では、単一の画像を N 個の拡張ビューにランダムに拡張し、2 つの重要なステップを交互に実行します (mta.py とコード セクションの詳細を参照)。
このステップには、各拡張ビューのスコアを計算して、その関連性と品質 (非直線性スコア) を評価することが含まれます。
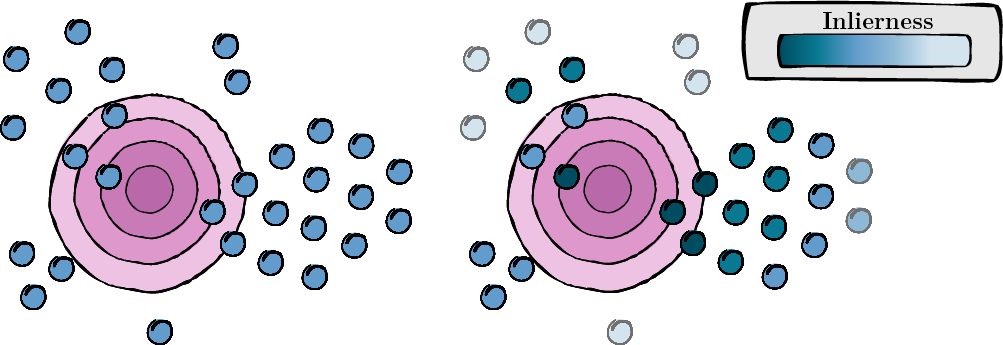
図 1: 各拡張ビューのスコア計算。
前のステップで計算されたスコアに基づいて、データ ポイントのモード (MeanShift) を求めます。
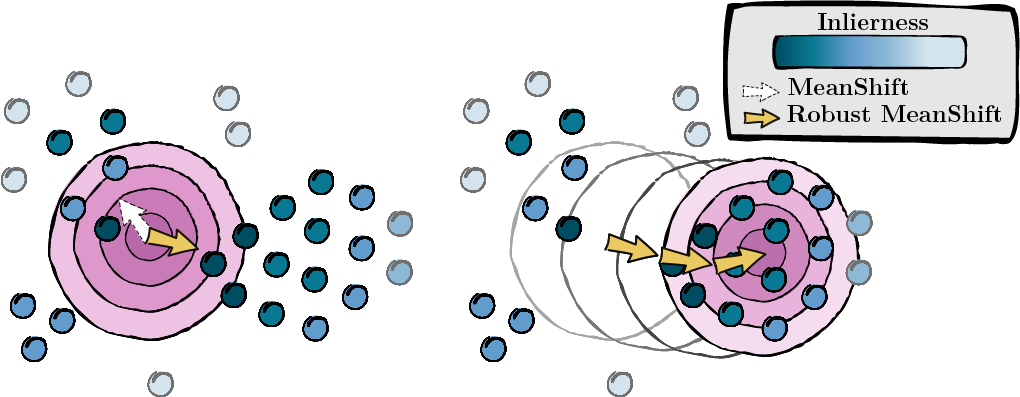
図 2: インライアネス スコアによって重み付けされたモードのシーク。
TPT のインストールと前処理に従います。これにより、データセットが適切にフォーマットされることが保証されます。ここでリポジトリを見つけることができます。より便利な場合は、data/datautils.py (20 行目) の辞書 ID_to_DIRNAME で各データセットのフォルダー名を変更できます。
次のコマンドを入力して、ランダム シード 1 と「a photo of a」プロンプトを使用して、ImageNet データセットに対して MTA を実行します。
python main.py --data /path/to/your/data --mta --testsets I --seed 1または、一度に 15 個のデータセット:
python main.py --data /path/to/your/data --mta --testsets I/A/R/V/K/DTD/Flower102/Food101/Cars/SUN397/Aircraft/Pets/Caltech101/UCF101/eurosat --seed 1手順の詳細については、mta.py を参照してください。
gaussian_kernelsolve_mtay ) の初期値を均一に設定します。このプロジェクトが役立つと思われる場合は、次のように引用してください。
@inproceedings { zanella2024test ,
title = { On the test-time zero-shot generalization of vision-language models: Do we really need prompt learning? } ,
author = { Zanella, Maxime and Ben Ayed, Ismail } ,
booktitle = { Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition } ,
pages = { 23783--23793 } ,
year = { 2024 }
}オープンソースへの貢献に対する TPT 作成者に感謝の意を表します。ここでリポジトリを見つけることができます。


