DeepKE
DeepKE 2.2.7
英語 | 简体中文
ディープラーニングベースの知識抽出ツールキット
ナレッジグラフ構築用
DeepKE は、 cnSchema 、低リソース、ドキュメントレベル、およびエンティティ、関係、および属性抽出のためのマルチモーダルシナリオをサポートするナレッジ グラフ構築のためのナレッジ抽出ツールキットです。初心者向けのドキュメント、オンラインデモ、論文、スライド、ポスターを提供します。
\使用してください。wisemodelまたはmodescapeの使用を検討してください。DeepKE および DeepKE-LLM のインストール中に問題が発生した場合は、ヒントを確認するか、すぐに問題を送信してください。問題の解決をお手伝いします。
April, 2024 Chinese-Alpaca-2-13B に基づく、OneKE と呼ばれる新しいバイリンガル (中国語と英語) スキーマベースの情報抽出モデルをリリースします。Feb, 2024 IEPile という名前の大規模 (0.32 億トークン) 高品質バイリンガル (中国語と英語) 情報抽出 (IE) 命令データセットと、 IEPileでトレーニングされた 2 つのモデル、baichuan2-13b-iepile-lora および llama2 をリリースします。 -13b-イエピレ-ロラ。Sep 2023 InstructIEと呼ばれる中国語、英語のバイリンガル情報抽出 (IE) 命令データセットが、命令ベースのナレッジ グラフ構築タスク (命令ベースの KGC) 用にリリースされました。詳細については、こちらをご覧ください。June, 2023 DeepKE-LLM をアップデートし、KnowLM、ChatGLM、LLaMA シリーズ、GPT シリーズなどによる知識抽出をサポートします。Apr, 2023 CP-NER(IJCAI'23)、ASP(EMNLP'22)、PRGC(ACL'21)、PURE(NAACL'21)などの新モデルを追加し、イベント抽出機能(中国語、英語)を提供しました。そして、Python パッケージの上位バージョン (Transformers など) との互換性を提供しました。Feb, 2023インコンテキスト学習 (EasyInstruct に基づく) およびデータ生成による LLM (GPT-3) の使用をサポートし、NER モデル W2NER(AAAI'22) を追加しました。Nov, 2022エンティティ認識と関係抽出のためのデータ アノテーション命令を追加し、弱教師データの自動ラベル付け (エンティティ抽出と関係抽出)、マルチ GPU トレーニングを最適化します。
Sept, 2022論文 DeepKE: 知識ベース母集団のための深層学習ベースの知識抽出ツールキットが EMNLP 2022 システム デモンストレーション トラックに受理されました。
Aug, 2022低リソース関係抽出のためのデータ拡張 (中国語、英語) のサポートを追加しました。
June, 2022エンティティおよびリレーション抽出のマルチモーダル サポートを追加しました。
May, 2022既製の知識抽出モデルを備えた DeepKE-cnschema をリリースしました。
Jan, 2022論文「DeepKE: A Deep Learning Based Knowledge Extraction Toolkit for Knowledge Base Population」をリリースしました。
Dec, 2021環境を自動作成するdockerfile追加しました。
Nov, 2021デプロイやトレーニングを行わずにリアルタイム抽出をサポートする DeepKE のデモを公開しました。
DeepKEのソースコードやデータセットなどの詳細を記載したドキュメントを公開しました。
Oct, 2021 pip install deepke
deepke-v2.0のコードを公開しました。
Aug, 2019 deepke-v1.0のコードを公開しました。
Aug, 2018 DeepKEプロジェクトの起動とdeepke-v0.1のコードを公開しました。
予測のデモンストレーションがあります。 GIF ファイルは Terminalizer によって作成されます。コードを取得します。 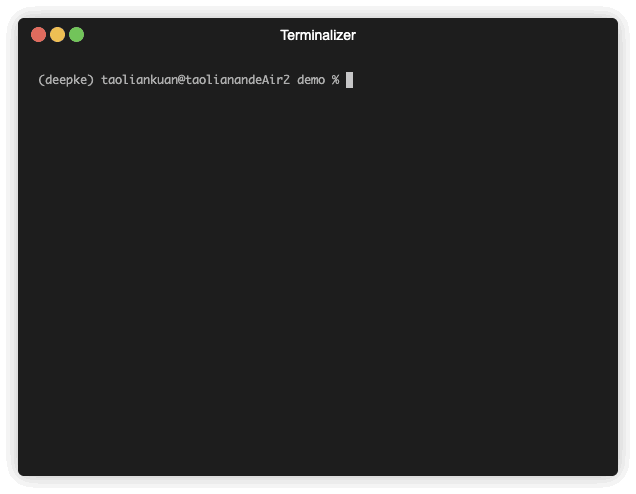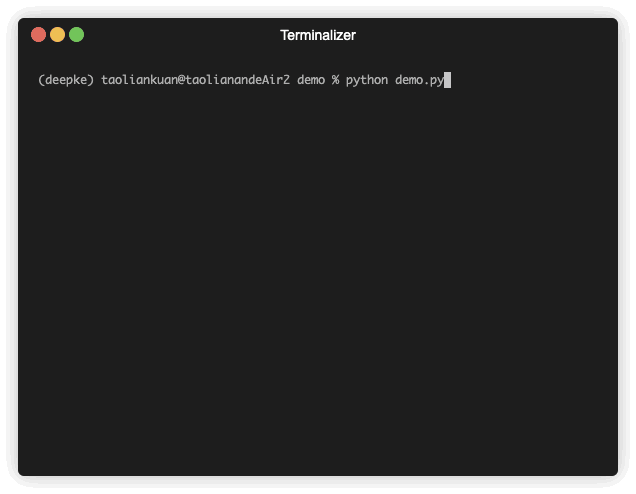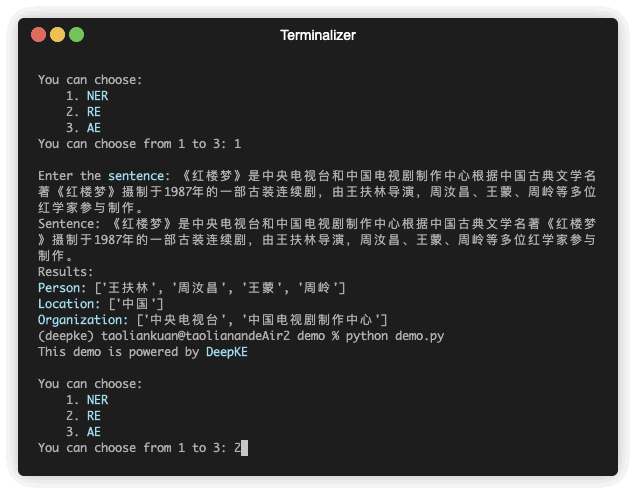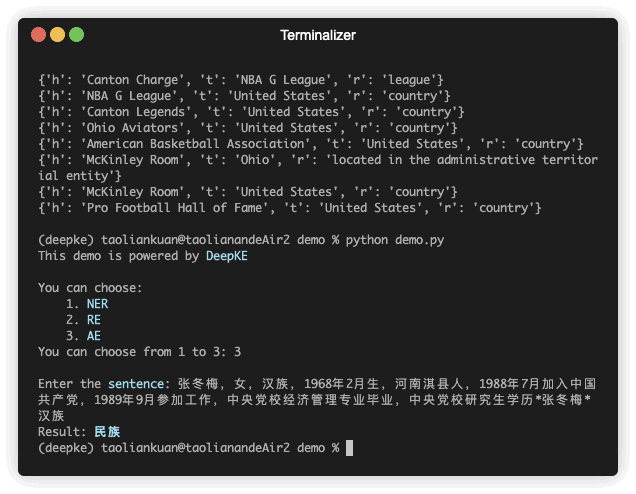
大規模モデルの時代において、DeepKE-LLM はまったく新しい環境依存関係を利用します。
conda create -n deepke-llm python=3.9
conda activate deepke-llm
cd example/llm
pip install -r requirements.txt
requirements.txtファイルはexample/llmフォルダーにあることに注意してください。
pip install deepkeをサポートしています。Step1基本コードをダウンロードする
git clone --depth 1 https://github.com/zjunlp/DeepKE.git Step2 Anaconda使って仮想環境を作成し、そこに入ります。
conda create -n deepke python=3.8
conda activate deepkeソースコードを使用してDeepKEをインストールする
pip install -r requirements.txt
python setup.py install
python setup.py develop pipを使用してDeepKE をインストールします (推奨されません! )
pip install deepkeStep3タスクディレクトリに入る
cd DeepKE/example/re/standardステップ 4データセットをダウンロードするか、アノテーションの指示に従ってデータを取得します
wget 120.27.214.45/Data/re/standard/data.tar.gz
tar -xzvf data.tar.gz多くの種類のデータ形式がサポートされており、詳細は各部に記載されています。
Step5トレーニング(トレーニング用のパラメータはconfフォルダで変更可能)
wandb を使用して視覚的なパラメータ調整をサポートします。
python run.py Step6予測(予測のパラメータはconfフォルダで変更可能)
predict.yamlでトレーニング済みモデルのパスを変更します。 xxx/checkpoints/2019-12-03_ 17-35-30/cnn_ epoch21.pthなど、モデルの絶対パスを使用する必要があります。
python predict.pyステップ1 Dockerクライアントをインストールする
Docker をインストールし、Docker サービスを開始します。
ステップ2 Dockerイメージをプルしてコンテナを実行します
docker pull zjunlp/deepke:latest
docker run -it zjunlp/deepke:latest /bin/bash残りの手順は、「手動環境設定」の手順 3 以降と同じです。
Python == 3.8
固有表現認識は、非構造化テキスト内で言及されている固有表現を特定し、人名、組織、場所、組織などの事前定義されたカテゴリに分類することを目的としています。
データは.txtファイルに保存されます。一部のインスタンスは次のとおりです (ユーザーは Doccano、MarkTool ツールに基づいてデータにラベルを付けることも、DeepKE の弱い監視を使用してデータを自動的に取得することもできます)。
| 文 | 人 | 位置 | 組織 |
|---|---|---|---|
| 本报北京9月4日讯记者杨涌报道:部分省区人民日报宣伝達工作座谈会9月3日4日京东京行。 | 杨涌 | 北京 | 人民日报 |
| 《红楼梦》王扶林导演、周汝昌、王蒙、周岭等多人数参加制作。 | 王扶林、周汝昌、王蒙、周岭 | ||
| 秦始皇兵马も陕西省西安市に位置し、世界八大奇蹟の一つです。 | 秦始皇 | 陕西省,西安市 |
特定の README で詳細なプロセスを読んでください。
STANDARD (完全監視)
当社は LLM をサポートし、トレーニングなしで cnSchema 内のエンティティを抽出する既製のモデル DeepKE-cnSchema-NER を提供します。
ステップ 1 DeepKE/example/ner/standardと入力します。データセットをダウンロードします。
wget 120.27.214.45/Data/ner/standard/data.tar.gz
tar -xzvf data.tar.gz Step2トレーニング
データセットとパラメーターは、それぞれdataフォルダーとconfフォルダーでカスタマイズできます。
python run.pyStep3予測
python predict.py数ショット
ステップ 1 DeepKE/example/ner/few-shotと入力します。データセットをダウンロードします。
wget 120.27.214.45/Data/ner/few_shot/data.tar.gz
tar -xzvf data.tar.gz Step2低リソース設定でのトレーニング
モデルがロードおよび保存されるディレクトリーと構成パラメーターはconfフォルダー内でカスタマイズできます。
python run.py +train=few_shotユーザーはconf/train/few_shot.yamlのload_path変更して、ロードされた既存のモデルを使用できます。
ステップ3 conf/config.yamlに- predictを追加し、モデルパスとしてloda_path変更し、 conf/predict.yaml内で予測結果が保存されるパスとしてwrite_path変更して、 python predict.pyを実行します。
python predict.pyマルチモーダル
ステップ 1 DeepKE/example/ner/multimodalと入力します。データセットをダウンロードします。
wget 120.27.214.45/Data/ner/multimodal/data.tar.gz
tar -xzvf data.tar.gzRCNN で検出されたオブジェクトと元の画像からの視覚的なグラウンディング オブジェクトを視覚的なローカル情報として使用します。RCNN は Faster_rcnn を介して、視覚的なグラウンディングは onestage_grounding を介して行われます。
Step2マルチモーダル設定でのトレーニング
dataフォルダーとconfフォルダーでカスタマイズできます。conf/train.yamlのload_path変更します。また、トレーニングで生成されるパス保存ログはlog_dirによってカスタマイズできます。 python run.pyStep3予測
python predict.py関係抽出は、非構造化テキストからエンティティ間の意味論的な関係を抽出するタスクです。
データは.csvファイルに保存されます。一部のインスタンスは次のとおりです (ユーザーは Doccano、MarkTool ツールに基づいてデータにラベルを付けることも、DeepKE の弱い監視を使用してデータを自動的に取得することもできます)。
| 文 | 関係 | 頭 | ヘッドオフセット | しっぽ | テールオフセット |
|---|---|---|---|---|---|
| 《岳父も爹》は王家演出のテレビドラマで、马恩が主演を務めています。 | 导演 | 岳父也是爹 | 1 | 王军 | 8 |
| 《九玄珠》は、ネットワークにアップロードされている作品の一部であり、作者は陪審です。 | 连下网站 | 九玄珠 | 1 | 纵横中文网 | 7 |
| 杭州の美景、西湖は最初に映る諺である。 | 所在地城市 | 西湖 | 8 | 杭州 | 2 |
!NOTE: 1 つのリレーションに複数のエンティティ タイプがある場合、エンティティ タイプには入力としてリレーションをプレフィックスとして付けることができます。
特定の README で詳細なプロセスを読んでください。
STANDARD (完全監視)
当社は LLM をサポートし、トレーニングなしで cnSchema 内の関係を抽出する既製のモデル DeepKE-cnSchema-RE を提供します。
Step1 DeepKE/example/re/standardフォルダに入ります。データセットをダウンロードします。
wget 120.27.214.45/Data/re/standard/data.tar.gz
tar -xzvf data.tar.gz Step2トレーニング
データセットとパラメーターは、それぞれdataフォルダーとconfフォルダーでカスタマイズできます。
python run.pyStep3予測
python predict.py数ショット
ステップ 1 DeepKE/example/re/few-shotと入力します。データセットをダウンロードします。
wget 120.27.214.45/Data/re/few_shot/data.tar.gz
tar -xzvf data.tar.gzステップ 2トレーニング
dataフォルダーとconfフォルダーでカスタマイズできます。conf/train.yamlのtrain_from_saved_modelを、前回トレーニングしたモデルが保存されたパスとして変更します。また、トレーニングで生成されるパス保存ログはlog_dirによってカスタマイズできます。 python run.pyStep3予測
python predict.py書類
ステップ 1 DeepKE/example/re/documentと入力します。データセットをダウンロードします。
wget 120.27.214.45/Data/re/document/data.tar.gz
tar -xzvf data.tar.gz Step2トレーニング
dataフォルダーとconfフォルダーでカスタマイズできます。conf/train.yamlのtrain_from_saved_modelを、前回トレーニングしたモデルが保存されたパスとして変更します。また、トレーニングで生成されるパス保存ログはlog_dirによってカスタマイズできます。 python run.pyStep3予測
python predict.pyマルチモーダル
ステップ 1 DeepKE/example/re/multimodalと入力します。データセットをダウンロードします。
wget 120.27.214.45/Data/re/multimodal/data.tar.gz
tar -xzvf data.tar.gzRCNN で検出されたオブジェクトと元の画像からの視覚的なグラウンディング オブジェクトを視覚的なローカル情報として使用します。RCNN は Faster_rcnn を介して、視覚的なグラウンディングは onestage_grounding を介して行われます。
Step2トレーニング
dataフォルダーとconfフォルダーでカスタマイズできます。conf/train.yamlのload_path変更します。また、トレーニングで生成されるパス保存ログはlog_dirによってカスタマイズできます。 python run.pyStep3予測
python predict.py属性抽出は、非構造化テキスト内のエンティティの属性を抽出することです。
データは.csvファイルに保存されます。いくつかの例は次のとおりです。
| 文 | アト | エント | Ent_offset | ヴァル | Val_offset |
|---|---|---|---|---|---|
| 张冬梅,女,汉族,1968年2月生,河南淇县人 | 民族 | 张冬梅 | 0 | 汉族 | 6 |
| 葛亮、字孔明、三国時代に発表された政治家、文学家、発明家。 | 朝代 | 诸葛亮 | 0 | 三国時代 | 8 |
| 2014年10月1日许鞍华执导的電影《黄金時間代》上映 | 上映時間 | 黄金時間 | 19 | 2014年10月1日 | 0 |
特定の README で詳細なプロセスを読んでください。
STANDARD (完全監視)
Step1 DeepKE/example/ae/standardフォルダに入ります。データセットをダウンロードします。
wget 120.27.214.45/Data/ae/standard/data.tar.gz
tar -xzvf data.tar.gz Step2トレーニング
データセットとパラメーターは、それぞれdataフォルダーとconfフォルダーでカスタマイズできます。
python run.pyStep3予測
python predict.py.tsvファイルに保存されます。いくつかのインスタンスは次のとおりです。| 文 | イベントの種類 | トリガー | 役割 | 口論 | |
|---|---|---|---|---|---|
| 《ヨーロッパ時間》の記録によると、27日の予定で、ベトナムのフォーラム・パーク・プロセスは、稼働条件を超えて作業を進めず、その結果、そのパーク・フィールドのゲストも1日停止することになった。 | 組織運営は罢工 | 罢工 | 罢工人员 | 法国巴黎卢浮宫博物馆员工 | |
| 時間 | 適切な時間27日 | ||||
| 所属組織 | 法国巴黎卢浮宫博物馆 | ||||
| 外运2019年上半期归母净利润增长17%:收购了少数股东股权 | 财经/交易出售/收购 | 收购 | 出方 | 少股东 | |
| 收购方 | 外运 | ||||
| 取引容易物 | 股权 | ||||
| 国家特大航海展13日、同時多発的にパフォーマンスマシンの事故が発生し、安全に安全に運行し、事故はありませんでした。 | 灾害/意外-坠机 | 坠机 | 時間 | 13日 | |
| 場所 | 美国亚特兰 | ||||
特定の README で詳細なプロセスを読んでください。
STANDARD(完全監視)
Step1 DeepKE/example/ee/standardフォルダに入ります。データセットをダウンロードします。
wget 120.27.214.45/Data/ee/DuEE.zip
unzip DuEE.zipステップ 2トレーニング
データセットとパラメーターは、それぞれdataフォルダーとconfフォルダーでカスタマイズできます。
python run.pyステップ 3予測
python predict.py1. 中国の THU にUsing nearest mirror 、 Anacondaのインストールが高速化されます。中国の aliyun はpip install XXXを高速化します。
2. ModuleNotFoundError: No module named 'past' 。 pip install futureを実行します。
3.事前トレーニング済み言語モデルをオンラインでインストールすると時間がかかります。使用前に事前トレーニング済みモデルをダウンロードし、 pretrainedフォルダーに保存することをお勧めします。すべてのタスク ディレクトリにあるREADME.md読んで、事前トレーニングされたモデルを保存するための特定の要件を確認してください。
4.DeepKEの古いバージョンは deepke-v1.0 ブランチにあります。ユーザーは古いバージョンを使用するようにブランチを変更できます。旧バージョンは標準関係抽出(example/re/standard)に完全移行しました。
5.ソースコードを変更したい場合は、 DeepKEをソースコードとともにインストールすることをお勧めします。そうしないと、変更は機能しません。問題を参照
6.その他の関連する低リソースの知識抽出作業については、「低リソースのシナリオでの知識の抽出: 調査と展望」を参照してください。
requirements.txtで要件の正確なバージョンを確認してください。
次のバージョンでは、KE 用のより強力な LLM をリリースする予定です。
その間、バグを修正し、問題を解決し、新しいリクエストに応えるための長期メンテナンスを提供します。何か問題がある場合は、私たちに問題を提出してください。
データ効率の高いナレッジ グラフの構築、高效知识图谱构建 (CCKS 2022 のチュートリアル) [スライド]
効率的で堅牢なナレッジ グラフの構築 (AACL-IJCNLP 2022 に関するチュートリアル) [スライド]
PromptKG ファミリー: プロンプト学習と KG 関連の研究作品、ツールキット、論文リストのギャラリー [リソース]
低リソースシナリオにおける知識の抽出: 調査と展望 [調査][論文リスト]
Doccano、MarkTool、LabelStudio: データ注釈ツールキット
LambdaKG: PLM ベースの KG 埋め込み用のライブラリおよびベンチマーク
EasyInstruct: 大規模言語モデルを指示するための使いやすいフレームワーク
読み物:
データ効率の高いナレッジ グラフの構築、高效知识图谱构建 (CCKS 2022 のチュートリアル) [スライド]
効率的で堅牢なナレッジ グラフの構築 (AACL-IJCNLP 2022 に関するチュートリアル) [スライド]
PromptKG ファミリー: プロンプト学習と KG 関連の研究作品、ツールキット、論文リストのギャラリー [リソース]
低リソースシナリオにおける知識の抽出: 調査と展望 [調査][論文リスト]
関連ツールキット:
Doccano、MarkTool、LabelStudio: データ注釈ツールキット
LambdaKG: PLM ベースの KG 埋め込み用のライブラリおよびベンチマーク
EasyInstruct: 大規模言語モデルを指示するための使いやすいフレームワーク
仕事で DeepKE を使用する場合は、論文を引用してください。
@inproceedings { EMNLP2022_Demo_DeepKE ,
author = { Ningyu Zhang and
Xin Xu and
Liankuan Tao and
Haiyang Yu and
Hongbin Ye and
Shuofei Qiao and
Xin Xie and
Xiang Chen and
Zhoubo Li and
Lei Li } ,
editor = { Wanxiang Che and
Ekaterina Shutova } ,
title = { DeepKE: {A} Deep Learning Based Knowledge Extraction Toolkit for Knowledge Base Population } ,
booktitle = { {EMNLP} (Demos) } ,
pages = { 98--108 } ,
publisher = { Association for Computational Linguistics } ,
year = { 2022 } ,
url = { https://aclanthology.org/2022.emnlp-demos.10 }
}Ningyu Zhang、Haofen Wang、Fei Huang、Feiyu Xiong、Liankuan Tao、Xin Xu、Honghao Gui、Zhenru Zhang、Chuanqi Tan、Qiang Chen、Xiaohan Wang、Zekun Xi、Xinrong Li、Haiyang Yu、Hongbin Ye、Shuofei Qiao、Peng Wang 、Yuqi Zhu、Xin Xie、Xiang Chen、Zhoubo Li、 Lei Li、Xiaozhuan Liang、Yunzhi Yao、Jing Chen、Yuqi Zhu、Shumin Deng、Wen Zhang、Guozhou Zheng、Huajun Chen
コミュニティ寄稿者: thredreams、eltociear、Ziwen Xu、Rui Huang、Xiaolong Weng


