プロジェクトページ |紙 |モデルカード?
私たちのフォローアップ研究である Photo-Realistic Image Restoration in the Wild with Controlled Vision-Language Models (CVPRW 2024) では、より良い画像生成のための事後サンプリングを提示し、Real-ESRGAN と同様に現実世界の混合劣化画像を処理します。
[ 2024.04.16 ] 続報「Photo-Realistic Image Restoration in the Wild with Controlled Vision-Language Models」が ArXiv に掲載されました。
[ 2024.04.15 ] 現実世界の劣化を考慮した Wild-IR モデルと、より良い画像生成のための事後サンプリングを更新しました。事前トレーニングされた重み wild-ir.pth および wild-daclip_ViT-L-14.pt も wild-ir に提供されます。
[ 2024.01.20 ] ???私たちの DA-CLIP 論文が ICLR 2024 に受理されました ???さらに、モデル カードでより堅牢なモデルを提供します。
[ 2023.10.25 ] トレーニングとテスト用のデータセットのリンクを追加しました。
[ 2023.10.13 ] Replicate デモと API を追加しました。 @chenxwh に感謝します! Hugging Face デモとオンライン Colab デモを更新しました。 @fffiloni と @camenduru に感謝します!ハグフェイス?のモデルカードも作りました。そして、テスト用にさらに多くの例を提供しました。
[ 2023.10.09 ] DA-CLIP と Universal IR モデルの事前学習済み重みをそれぞれ link1 と link2 で公開しました。さらに、独自の画像をテストしたい場合のために、Gradio アプリ ファイルも提供しています。
OS:Ubuntu 20.04
エヌビディア:
クダ:11.4
Python 3.8
まず、次のものを使用して仮想環境を作成することをお勧めします。
python3 -m venv .envsource .env/bin/activate pip install -U pip pip install -r 要件.txt
universal-image-restorationディレクトリに移動し、次を実行します。
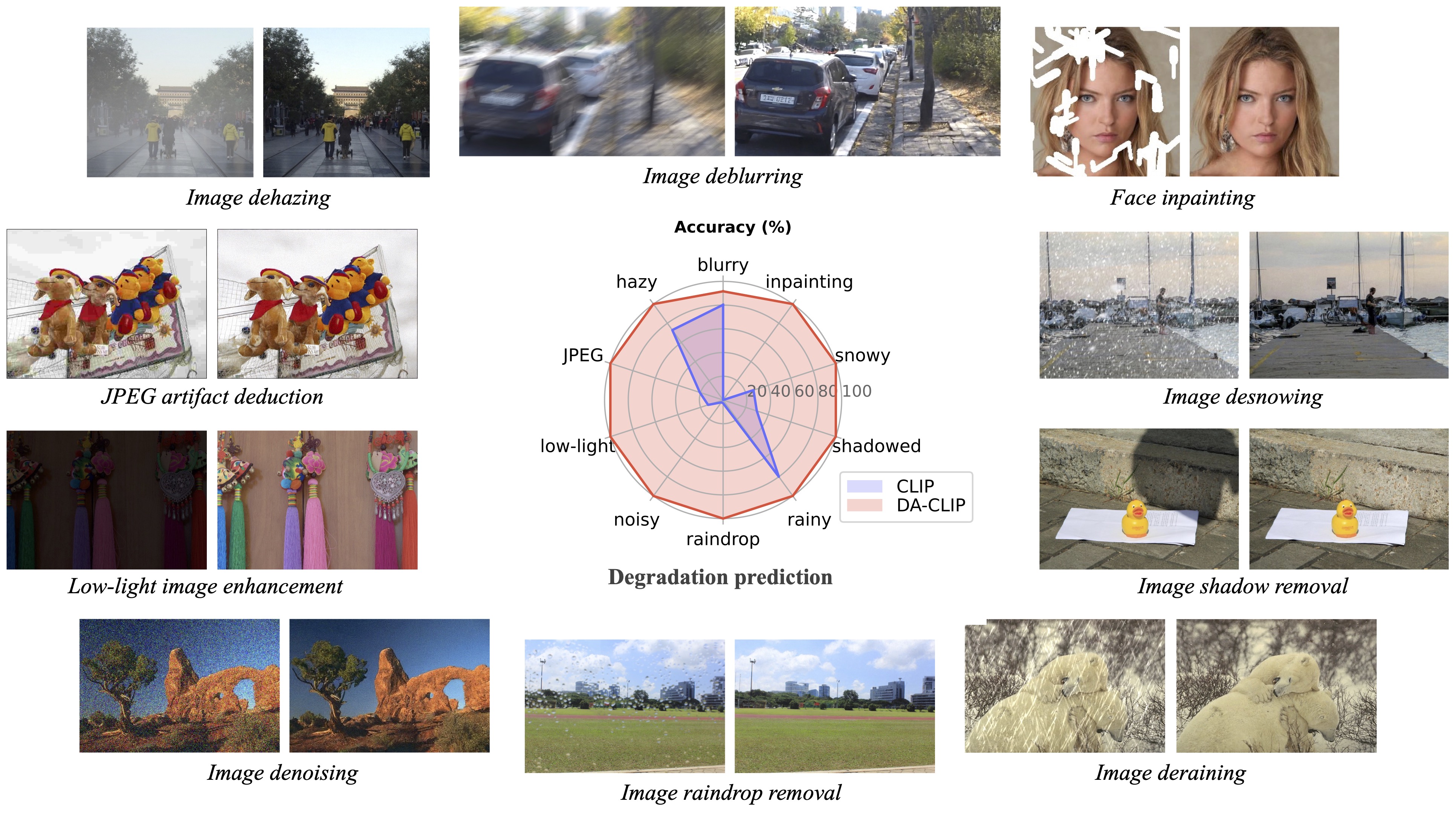
import torchfrom PIL import Imageimport open_clipcheckpoint = 'pretrained/daclip_ViT-B-32.pt'model、preprocess = open_clip.create_model_from_pretrained('daclip_ViT-B-32', pretrained=checkpoint)tokenizer = open_clip.get_tokenizer('ViT-B-32 ')画像 = preprocess(Image.open("haze_01.png")).unsqueeze(0)degradations = ['モーションブラー','かすんだ','jpeg圧縮','低光','ノイジー','雨滴' ,'雨','影','雪','未完了']text = tokenizer(劣化)with torch.no_grad(), torch.cuda.amp.autocast():text_features = model.encode_text(text)image_features, degra_features = model.encode_image(image, control=True)degra_features /= degra_features.norm(dim=-1, keepdim=True)text_features / = text_features.norm(dim=-1, keepdim=True)text_probs = (100.0 * degra_features @ text_features.T).softmax(dim=-1)index = torch.argmax(text_probs[0])print(f"タスク: {task_name}: {degradations[index]} - {text_probs[0][index]}")論文の「データセット構築」セクションに従って、トレーニング データセットとテスト データセットを次のように準備します。
#### トレーニング データセット用 ######## (未完了とは修復を意味します) ####datasets/universal/train|--motion-blurry| |--LQ/*.png| |--GT/*.png|--かすんでいる|--jpeg圧縮|--低照度|--ノイズが多い|--雨滴|--雨|-影が入っている|--雪|--未完成## ## データセットのテスト用 ######## (train と同じ構造) ####datasets/universal/val ...#### クリーンなキャプションの場合 ####datasets/universal/daclip_train.csv データセット/ユニバーサル/daclip_val.csv
次に、 universal-image-restoration/config/daclip-sdeディレクトリに移動し、 options/train.ymlおよびoptions/test.ymlのオプション ファイルのデータセット パスを変更します。
trainディレクトリとvalディレクトリの両方にさらにタスクまたはデータセットを追加し、 distortionに劣化ワードを追加できます。
| 劣化 | モーションブラー | かすんでいる | JPEG圧縮* | 微光 | ノイズが多い* (jpegも同様) |
|---|---|---|---|---|---|
| データセット | ゴープロ | RESIDE-6k | DIV2K+Flickr2K | 笑 | DIV2K+Flickr2K |
| 劣化 | 雨粒 | 雨の | 影のある | 雪の多い | 未完成 |
|---|---|---|---|---|---|
| データセット | レインドロップ | Rain100H: 電車、テスト | SRD | 雪100K | セレバHQ-256 |
抽出するのはトレーニング用のトレーニング データセットのみです。すべての検証データセットはGoogle ドライブにダウンロードできます。 jpeg およびノイズの多いデータセットの場合、このスクリプトを使用して LQ イメージを生成できます。
詳細については、DA-CLIP.mdを参照してください。
トレーニング用のメイン コードはuniversal-image-restoration/config/daclip-sdeにあり、DA-CLIP のコア ネットワークはuniversal-image-restoration/open_clip/daclip_model.pyにあります。
事前トレーニングされたDA-CLIP 重みをpretrainedディレクトリに配置し、 daclipパスを確認します。
次に、以下の bash スクリプトに従ってモデルをトレーニングできます。
cd universal-image-restoration/config/daclip-sde# 単一 GPU の場合:python3 train.py -opt=options/train.yml# 分散トレーニングの場合、オプション filepython3 -m torch.distributed.launch の gpu_ids を変更する必要があります - -nproc_per_node=2 --master_port=4321 train.py -opt=options/train.yml --launcherパイトーチ
モデルとトレーニング ログはlog/universal-irに保存されます。 tail -f log/universal-ir/train_universal-ir_***.log -n 100実行すると、ログを随時出力できます。
同じトレーニング手順を、野生環境 (wild-ir) での画像復元に使用できます。
| モデル名 | 説明 | Googleドライブ | ハグ顔 |
|---|---|---|---|
| DAクリップ | 劣化を考慮したCLIPモデル | ダウンロード | ダウンロード |
| ユニバーサルIR | DA-CLIPベースの汎用画像復元モデル | ダウンロード | ダウンロード |
| DA-CLIP-ミックス | 劣化を考慮した CLIP モデル (ガウスぼかし + 顔修復およびガウスぼかし + レイニーを追加) | ダウンロード | ダウンロード |
| ユニバーサル IR ミックス | DA-CLIP ベースのユニバーサル画像復元モデル (堅牢なトレーニングとミックス劣化を追加) | ダウンロード | ダウンロード |
| ワイルドダクリップ | 劣化を認識した実際の CLIP モデル (ViT-L-14) | ダウンロード | ダウンロード |
| ワイルドIR | DA-CLIPベースの実際の画像復元モデル | ダウンロード | ダウンロード |
画像復元の方法を評価するには、ベンチマーク パスとモデル パスを変更して実行してください。
cd ユニバーサルイメージ復元/config/universal-ir python test.py -opt=options/test.yml
ここでは、独自のイメージをテストするための app.py ファイルを提供します。その前に、事前トレーニングされた重み (DA-CLIP および UIR) をダウンロードし、 options/test.ymlのモデル パスを変更する必要があります。次に、 python app.pyを実行するだけで、 http://localhost:7860を開いてモデルをテストできます。 ( imagesディレクトリには、劣化の異なるいくつかのイメージも用意されています)。 Google ドライブのテスト データセットからのさらなる例も提供しています。
同じ手順を野生環境 (wild-ir) でのイメージ復元に使用できます。
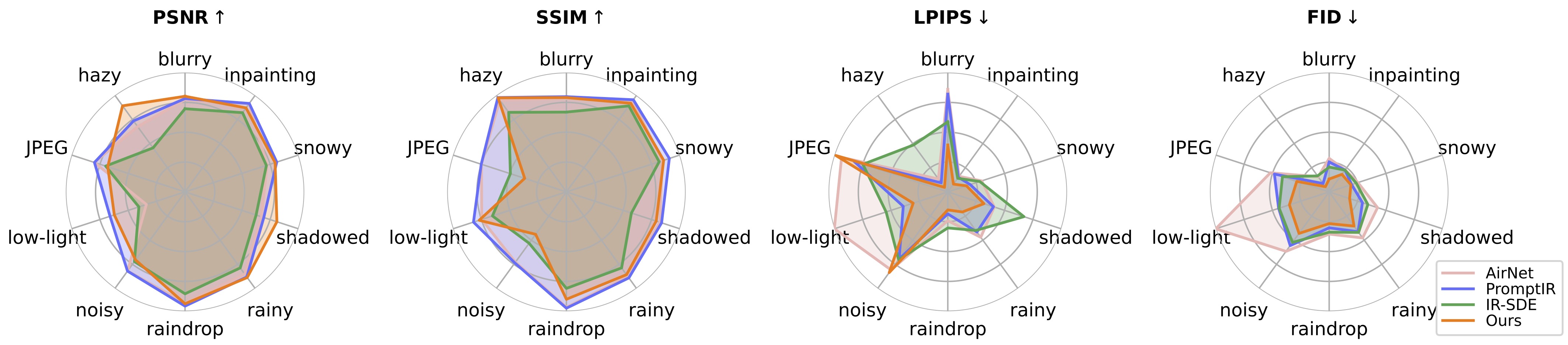



?テストの結果、現在の事前トレーニング済みモデルでは、トレーニング データセット (異なるデバイス、または異なる解像度や劣化でキャプチャされたもの) で分布が変化する可能性のある一部の実世界の画像を処理するのがまだ難しいことがわかりました。今後の課題として、モデルをより実用的なものにしていくつもりです。また、私たちの研究に興味のあるユーザーには、より大きなデータセットとより多くの劣化タイプを使用して独自のモデルをトレーニングすることをお勧めします。
?ところで、入力画像のサイズを直接変更すると、ほとんどのタスクのパフォーマンスが低下することもわかりました。トレーニングにサイズ変更ステップを追加することもできますが、補間により常に画質が損なわれます。
?修復タスクについては、データセットの制限により、現在のモデルは顔の修復のみをサポートします。マスクの例が提供されており、generate_masked_face スクリプトを使用して未完成の顔を生成できます。
謝辞:私たちの DA-CLIP は IR-SDE と open_clip に基づいています。コードをありがとう!
ご質問がある場合は、[email protected] までご連絡ください。
私たちのコードがあなたの研究や仕事に役立つ場合は、論文の引用を検討してください。 BibTeX の参考文献は次のとおりです。
@article{luo2023controlling,
title={Controlling Vision-Language Models for Universal Image Restoration},
author={Luo, Ziwei and Gustafsson, Fredrik K and Zhao, Zheng and Sj{"o}lund, Jens and Sch{"o}n, Thomas B},
journal={arXiv preprint arXiv:2310.01018},
year={2023}
}
@article{luo2024photo,
title={Photo-Realistic Image Restoration in the Wild with Controlled Vision-Language Models},
author={Luo, Ziwei and Gustafsson, Fredrik K and Zhao, Zheng and Sj{"o}lund, Jens and Sch{"o}n, Thomas B},
journal={arXiv preprint arXiv:2404.09732},
year={2024}
}

