
Xuan Ju 1* 、Yiming Gao 1* 、Zhaoyang Zhang 1*# 、Ziyang Yuan 1 、Xintao Wang 1 、Ailing Zeng、Yu Xiong、Qiang Xu、Ying Shan 1
1 ARC Lab、Tencent PCG 2香港中文大学*均等貢献#プロジェクトリーダー
ビデオ データセットは、Sora などのビデオ生成において重要な役割を果たします。ただし、既存のテキストビデオ データセットは、長いビデオ シーケンスの処理やショット トランジションのキャプチャに関しては不十分であることがよくあります。これらの制限に対処するために、長時間ビデオ生成タスク用に特別に設計されたビデオ データセットであるMiraDataを導入します。さらに、ビデオ生成における時間的一貫性とモーション強度をより適切に評価するために、3D 一貫性と追跡ベースのモーション強度メトリクスを追加することで既存のベンチマークを強化するMiraBenchを導入します。詳細については、当社の研究論文をご覧ください。
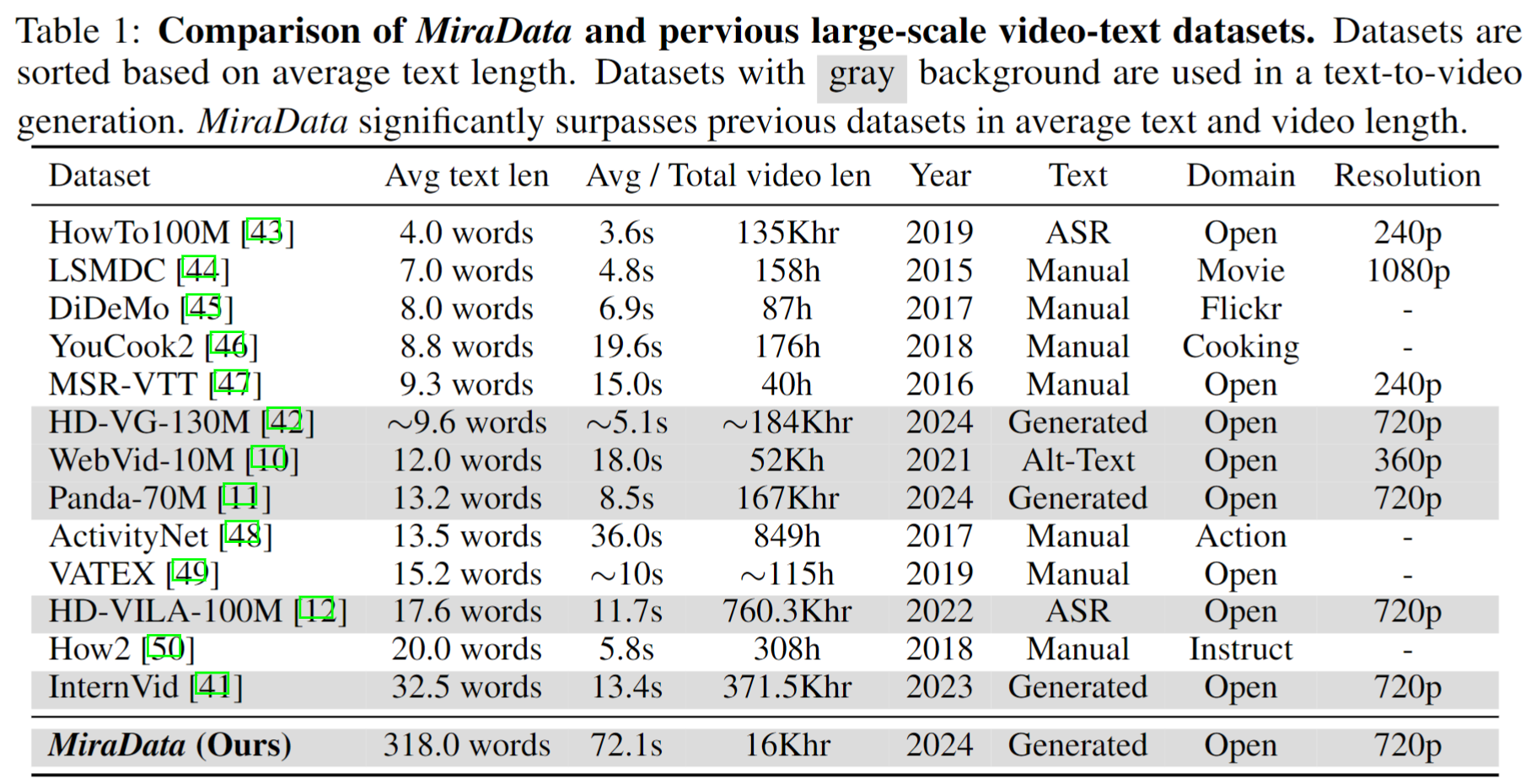
330K、93K、42K、9K データを含む 4 つのバージョンの MiraData をリリースします。
このバージョンの MiraData のメタ ファイルは、Google Drive および HuggingFace Dataset で提供されます。さらに、メタ ファイルの構成をより適切かつ迅速に理解するために、100 個のビデオ クリップのセットをランダムにサンプリングしています。これらのクリップには、ここからアクセスできます。メタ ファイルには次のインデックス情報が含まれています。
{download_id}.{clip_id}ビデオをダウンロードしてクリップに分割するには、まず Google ドライブまたは HuggingFace Dataset からメタ ファイルをダウンロードします。メタ ファイルを取得したら、次のスクリプトを使用してビデオ サンプルをダウンロードできます。
python download_data.py --meta_csv {meta file} --download_start_id {the start of download id} --download_end_id {the end of download id} --raw_video_save_dir {the path of saving raw videos} --clip_video_save_dir {the path of saving cutted video}
必要な限り、データセット/Github/プロジェクト Web ページからビデオ サンプルを削除します。ご要望は弊社までご連絡ください。
MiraData を収集するには、まずさまざまなシナリオで YouTube チャンネルを手動で選択し、HD-VILA-100M、Videovo、Pixabay、および Pexels からのビデオを含めます。次に、対応するチャンネルのすべてのビデオがダウンロードされ、PySceneDetect を使用して分割されます。次に、複数のモデルを使用して短いクリップをつなぎ合わせ、低品質のビデオを除外しました。これに続いて、再生時間の長いビデオ クリップを選択しました。最後に、GPT-4V を使用してすべてのビデオ クリップにキャプションを付けました。

MiraData の各ビデオには構造化されたキャプションが付いています。これらのキャプションは、さまざまな観点から詳細な説明を提供し、データセットの充実度を高めます。
6種類のキャプション
既存のオープンソースのビジュアル LLM 手法と GPT-4V をテストしたところ、GPT-4V のキャプションのほうが時間的シーケンスの観点から意味の理解においてより高い精度と一貫性を示すことがわかりました。
アノテーションのコストとキャプションの精度のバランスをとるために、各ビデオから 8 フレームを均一にサンプリングし、それらを 1 つの大きな画像の 2x4 グリッドに配置します。次に、Panda-70M のキャプション モデルを使用して、各ビデオにメイン コンテンツのヒントとなる 1 文のキャプションを注釈付けし、それを微調整されたプロンプトに入力します。微調整されたプロンプトと 2x4 の大きな画像を GPT-4V に供給することで、たった 1 ラウンドの会話で複数の次元のキャプションを効率的に出力できます。特定のプロンプト コンテンツは caption_gpt4v.py にあります。より高品質のテキスト ビデオ データへの貢献を歓迎します。 ?
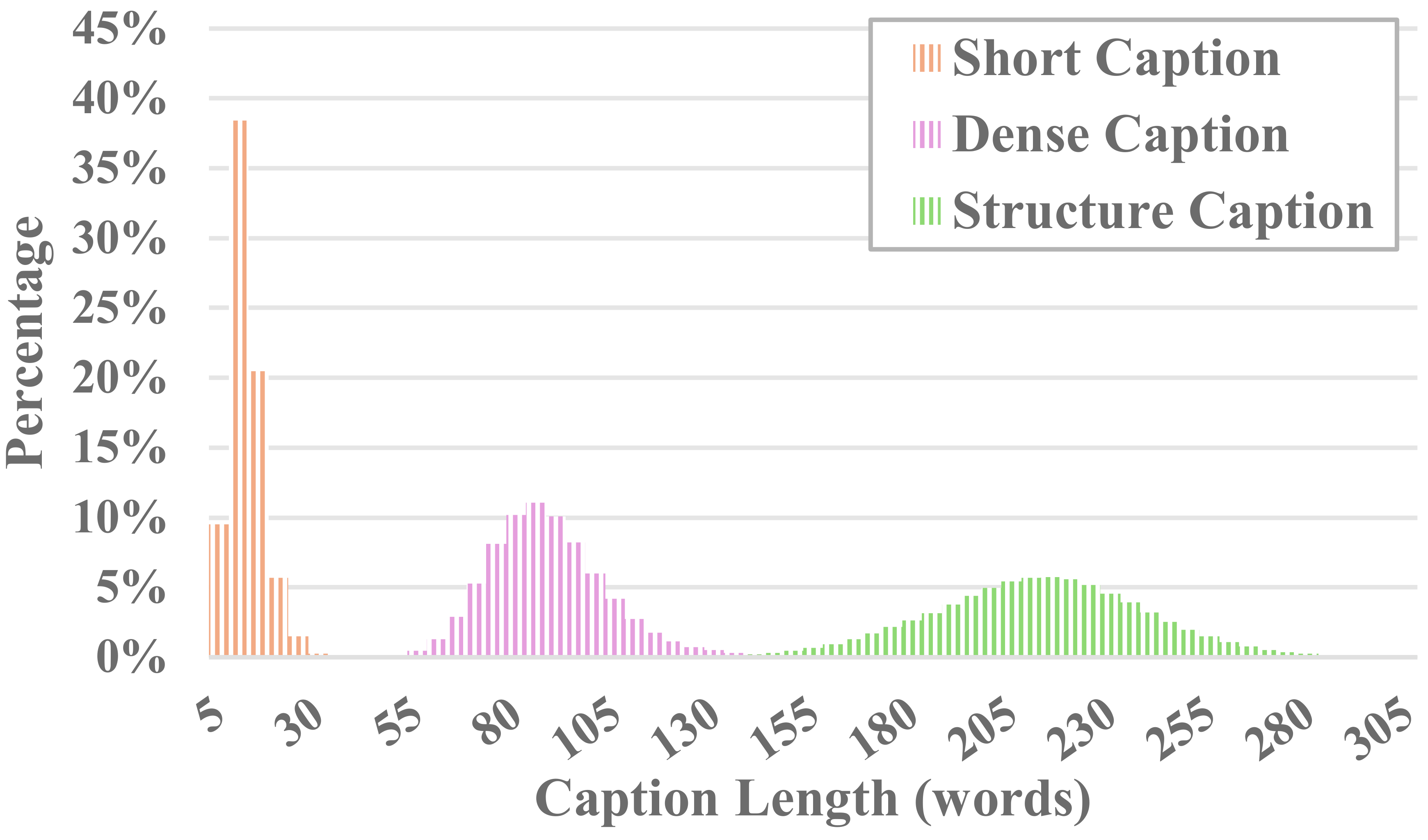

長時間ビデオの生成を評価するために、時間的一貫性、時間的モーション強度、3D 一貫性、ビジュアル品質、テキストとビデオの位置合わせ、配信の一貫性を含む 6 つの観点から、MiraBench で 17 の評価指標を設計します。これらのメトリクスは、以前のビデオ生成モデルやテキストからビデオへのベンチマークで使用されていた一般的な評価基準のほとんどを網羅しています。
生成されたビデオを評価するには、まず次の方法で Python 環境をセットアップしてください。
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu116
pip install -r requirements.txt
次に、次のように評価を実行します。
python calculate_score.py --meta_file data/evaluation_example/meta_generated.csv --frame_dir data/evaluation_example/frames_generated --gt_meta_file data/evaluation_example/meta_gt.csv --gt_frame_dir data/evaluation_example/frames_gt --output_folder data/evaluation_example/results --ckpt_path data/ckpt --device cuda
data/evaluation_exampleの例に従って、独自に生成したビデオを評価できます。
ライセンスを参照してください。
このプロジェクトがあなたの研究に役立つと思われる場合は、私たちの論文を引用してください。 ?
@misc{ju2024miradatalargescalevideodataset,
title={MiraData: A Large-Scale Video Dataset with Long Durations and Structured Captions},
author={Xuan Ju and Yiming Gao and Zhaoyang Zhang and Ziyang Yuan and Xintao Wang and Ailing Zeng and Yu Xiong and Qiang Xu and Ying Shan},
year={2024},
eprint={2407.06358},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2407.06358},
}
お問い合わせについては、 [email protected]メールでお問い合わせください。
MiraData は GPL-v3 ライセンスに基づいており、商用利用がサポートされています。 MiraData の商用ライセンスが必要な場合は、お気軽にお問い合わせください。


