Any-to-Any マルチモーダル基礎モデルをトレーニングするためのフレームワーク。
スケーラブル。オープンソース。数十のモダリティとタスクにわたって。
EPFL - アップル
Website | BibTeX | ? Demo
公式実装と事前トレーニング済みモデル:
4M: 大規模マルチモーダル マスク モデリング、NeurIPS 2023 (スポットライト)
David Mizrahi*、Roman Bachmann*、Oğuzhan Fatih Kar、Teresa Yeo、Mingfei Gao、Afshin Dehghan、Amir Zamir
4M-21: 数十のタスクとモダリティのための Any-to-Any ビジョン モデル、NeurIPS 2024
Roman Bachmann*、Oğuzhan Fatih Kar*、David Mizrahi*、Ali Garjani、Mingfei Gao、David Griffiths、Jiaming Hu、Afshin Dehghan、Amir Zamir
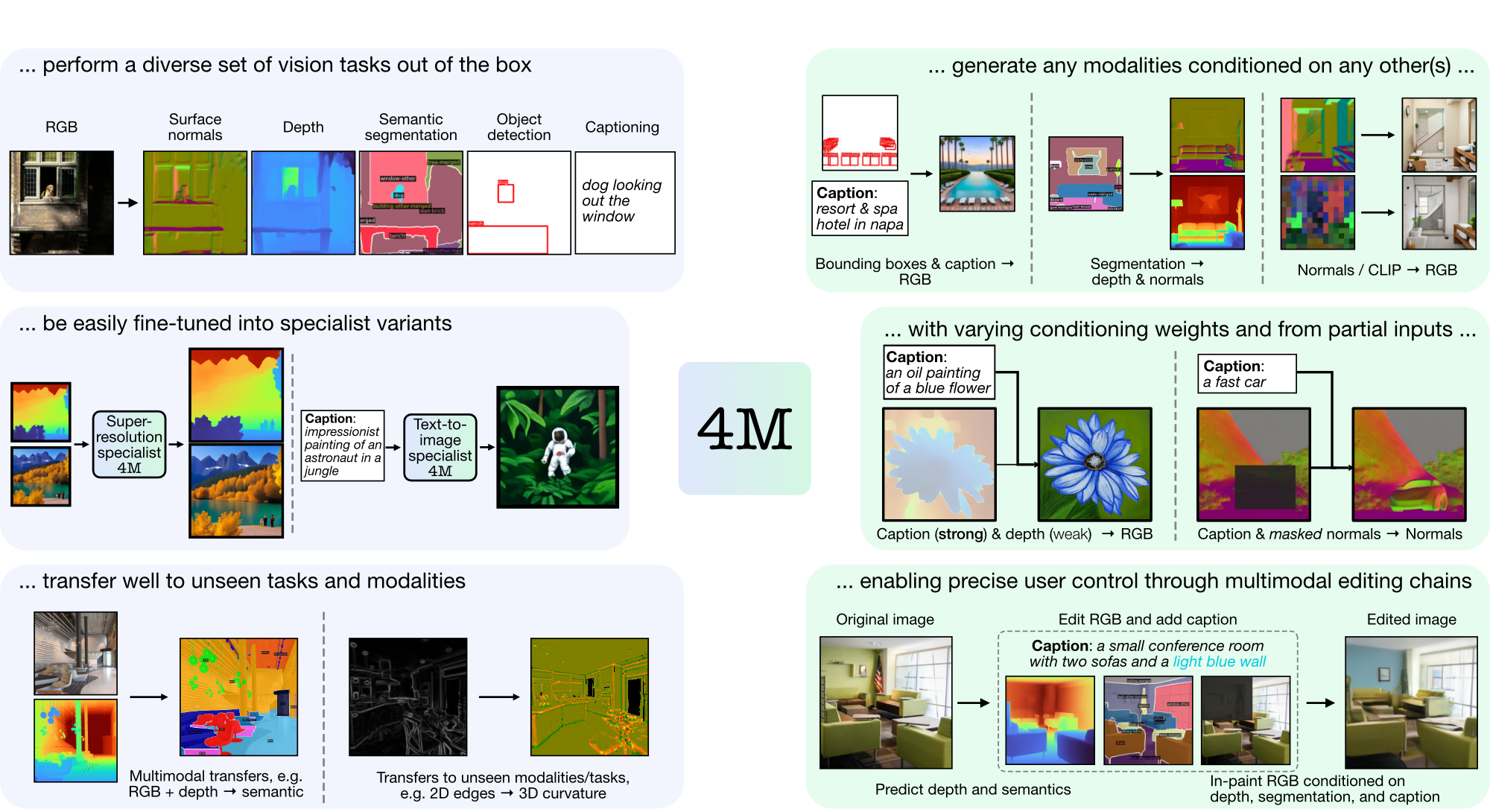
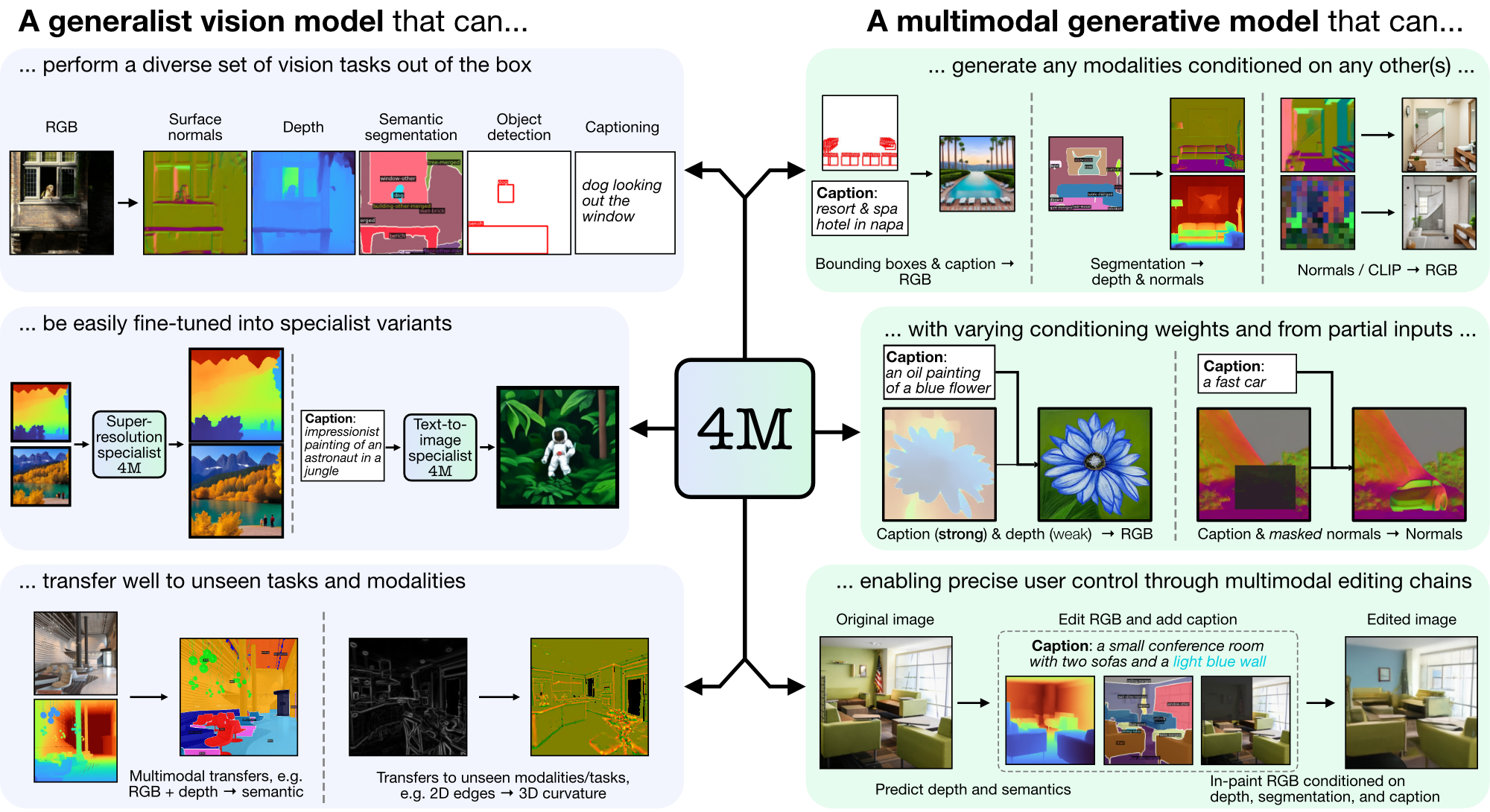
4M は、トークン化とマスキングを使用して多くの多様なモダリティに拡張する、「any-to-any」基盤モデルをトレーニングするためのフレームワークです。 4M を使用してトレーニングされたモデルは、広範囲の視覚タスクを実行でき、目に見えないタスクやモダリティに適切に移行でき、柔軟で操作可能なマルチモーダル生成モデルです。 「4M: Massively Multimodal Masked Modeling」(ここでは 4M-7 と表記) および「4M-21: An Any-to-Any Vision Model for Tens of Tasks and Modalities」(ここでは 4M と表記) のコードとモデルをリリースしています。 -21)。
git clone https://github.com/apple/ml-4m
cd ml-4m
conda create -n fourm python=3.9 -y
conda activate fourm
pip install --upgrade pip # enable PEP 660 support
pip install -e .
# Run in Python shell
import torch
print(torch.cuda.is_available()) # Should return True
CUDA が利用できない場合は、公式のインストール手順に従って PyTorch を再インストールすることを検討してください。同様に、xFormers (トークナイザーを高速化するためのオプション) をインストールする場合は、その README に従って、CUDA バージョンが正しいことを確認してください。
RGB からすべて、または {キャプション、バウンディング ボックス} からすべての生成タスクに 4M モデルの使用をすぐに開始できるデモ ラッパーを提供しています。たとえば、特定の RGB 入力からすべてのモダリティを生成するには、次のように呼び出します。
from fourm . demo_4M_sampler import Demo4MSampler , img_from_url
sampler = Demo4MSampler ( fm = 'EPFL-VILAB/4M-21_XL' ). cuda ()
img = img_from_url ( 'https://storage.googleapis.com/four_m_site/images/demo_rgb.png' ) # 1x3x224x224 ImageNet-standardized PyTorch Tensor
preds = sampler ({ 'rgb@224' : img . cuda ()}, seed = None )
sampler . plot_modalities ( preds , save_path = None )次のような出力が表示されることが予想されます。


すべてにキャプションを生成するには、サンプラー入力をpreds = sampler({'caption': 'A lake house with a boat in front [S_1]'})で置き換えることができます。利用可能な 4M モデルのリストについては、以下のモデル動物園を参照してください。生成の詳細については、README_GENERATION.md を参照してください。
位置合わせされたマルチモーダル データセットを準備する方法については、README_DATA.md を参照してください。
モダリティ固有のトークナイザーをトレーニングする方法については、README_TOKENIZATION.md を参照してください。
4M モデルをトレーニングする方法については、README_TRAINING.md を参照してください。
推論/生成に 4M モデルを使用する方法については、README_GENERATION.md を参照してください。また、4M 推論の例を含む生成ノートブックも提供しており、特に条件付き画像生成と共通ビジョン タスク (つまり、RGB-to-All) を実行します。
セーフテンサーとして 4M およびトークナイザー チェックポイントを提供し、Hugging Face Hub を介した簡単なロードも提供します。
| モデル | #モッド。 | データセット | # パラメータ | 構成 | 重み |
|---|---|---|---|---|---|
| 4MB-B | 7 | CC12M | 198M | 構成 | チェックポイント / HF ハブ |
| 4MB-B | 7 | COYO700M | 198M | 構成 | チェックポイント / HF ハブ |
| 4MB-B | 21 | CC12M+COYO700M+C4 | 198M | 構成 | チェックポイント / HF ハブ |
| 4M-L | 7 | CC12M | 705M | 構成 | チェックポイント / HF ハブ |
| 4M-L | 7 | COYO700M | 705M | 構成 | チェックポイント / HF ハブ |
| 4M-L | 21 | CC12M+COYO700M+C4 | 705M | 構成 | チェックポイント / HF ハブ |
| 4M-XL | 7 | CC12M | 2.8B | 構成 | チェックポイント / HF ハブ |
| 4M-XL | 7 | COYO700M | 2.8B | 構成 | チェックポイント / HF ハブ |
| 4M-XL | 21 | CC12M+COYO700M+C4 | 2.8B | 構成 | チェックポイント / HF ハブ |
Hugging Face Hub からモデルをロードするには:
from fourm . models . fm import FM
fm7b_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7_B_CC12M' )
fm7b_coyo = FM . from_pretrained ( 'EPFL-VILAB/4M-7_B_COYO700M' )
fm21b = FM . from_pretrained ( 'EPFL-VILAB/4M-21_B' )
fm7l_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7_L_CC12M' )
fm7l_coyo = FM . from_pretrained ( 'EPFL-VILAB/4M-7_L_COYO700M' )
fm21l = FM . from_pretrained ( 'EPFL-VILAB/4M-21_L' )
fm7xl_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7_XL_CC12M' )
fm7xl_coyo = FM . from_pretrained ( 'EPFL-VILAB/4M-7_XL_COYO700M' )
fm21xl = FM . from_pretrained ( 'EPFL-VILAB/4M-21_XL' )チェックポイントを手動でロードするには、まず上記のリンクからセーフテンソル ファイルをダウンロードし、次を呼び出します。
from fourm . utils import load_safetensors
from fourm . models . fm import FM
ckpt , config = load_safetensors ( '/path/to/checkpoint.safetensors' )
fm = FM ( config = config )
fm . load_state_dict ( ckpt )これらのモデルは標準の 4M-7 CC12M モデルで初期化されましたが、テキスト入力に大きく偏ったモダリティ混合でトレーニングを継続しました。他のすべてのタスクは引き続き実行できますが、微調整されていないモデルと比較して、テキストから画像への生成のパフォーマンスが向上します。
| モデル | #モッド。 | データセット | # パラメータ | 構成 | 重み |
|---|---|---|---|---|---|
| 4M-T2I-B | 7 | CC12M | 198M | 構成 | チェックポイント / HF ハブ |
| 4M-T2I-L | 7 | CC12M | 705M | 構成 | チェックポイント / HF ハブ |
| 4M-T2I-XL | 7 | CC12M | 2.8B | 構成 | チェックポイント / HF ハブ |
Hugging Face Hub からモデルをロードするには:
from fourm . models . fm import FM
fm7b_t2i_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-T2I_B_CC12M' )
fm7l_t2i_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-T2I_L_CC12M' )
fm7xl_t2i_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-T2I_XL_CC12M' )チェックポイントからの手動ロードは、基本 4M モデルの場合と同じ方法で実行されます。
| モデル | #モッド。 | データセット | # パラメータ | 構成 | 重み |
|---|---|---|---|---|---|
| 4M-SR-L | 7 | CC12M | 198M | 構成 | チェックポイント / HF ハブ |
Hugging Face Hub からモデルをロードするには:
from fourm . models . fm import FM
fm7l_sr_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-SR_L_CC12M' )チェックポイントからの手動ロードは、基本 4M モデルの場合と同じ方法で実行されます。
| モダリティ | 解決 | トークンの数 | コードブックのサイズ | 拡散デコーダ | 重み |
|---|---|---|---|---|---|
| RGB | 224-448 | 196-784 | 16k | ✓ | チェックポイント / HF ハブ |
| 深さ | 224-448 | 196-784 | 8k | ✓ | チェックポイント / HF ハブ |
| 法線 | 224-448 | 196-784 | 8k | ✓ | チェックポイント / HF ハブ |
| エッジ (キャニー、SAM) | 224-512 | 196-1024 | 8k | ✓ | チェックポイント / HF ハブ |
| COCO セマンティック セグメンテーション | 224-448 | 196-784 | 4k | ✗ | チェックポイント / HF ハブ |
| クリップ-B/16 | 224-448 | 196-784 | 8k | ✗ | チェックポイント / HF ハブ |
| DINOv2-B/14 | 224-448 | 256-1024 | 8k | ✗ | チェックポイント / HF ハブ |
| DINOv2-B/14 (グローバル) | 224 | 16 | 8k | ✗ | チェックポイント / HF ハブ |
| イメージバインド-H/14 | 224-448 | 256-1024 | 8k | ✗ | チェックポイント / HF ハブ |
| ImageBind-H/14 (グローバル) | 224 | 16 | 8k | ✗ | チェックポイント / HF ハブ |
| SAM インスタンス | - | 64 | 1k | ✗ | チェックポイント / HF ハブ |
| 3D 人間のポーズ | - | 8 | 1k | ✗ | チェックポイント / HF ハブ |
Hugging Face Hub からモデルをロードするには:
from fourm . vq . vqvae import VQVAE , DiVAE
# 4M-7 modalities
tok_rgb = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_rgb_16k_224-448' )
tok_depth = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_depth_8k_224-448' )
tok_normal = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_normal_8k_224-448' )
tok_semseg = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_semseg_4k_224-448' )
tok_clip = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_CLIP-B16_8k_224-448' )
# 4M-21 modalities
tok_edge = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_edge_8k_224-512' )
tok_dinov2 = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_DINOv2-B14_8k_224-448' )
tok_dinov2_global = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_DINOv2-B14-global_8k_16_224' )
tok_imagebind = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_ImageBind-H14_8k_224-448' )
tok_imagebind_global = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_ImageBind-H14-global_8k_16_224' )
sam_instance = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_sam-instance_1k_64' )
human_poses = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_human-poses_1k_8' )チェックポイントを手動でロードするには、まず上記のリンクからセーフテンソル ファイルをダウンロードし、次を呼び出します。
from fourm . utils import load_safetensors
from fourm . vq . vqvae import VQVAE , DiVAE
ckpt , config = load_safetensors ( '/path/to/checkpoint.safetensors' )
tok = VQVAE ( config = config ) # Or DiVAE for models with a diffusion decoder
tok . load_state_dict ( ckpt )このリポジトリのコードは、LICENSE ファイルに記載されている Apache 2.0 ライセンスに基づいてリリースされています。
このリポジトリ内のモデルの重みは、LICENSE_WEIGHTS ファイルにあるサンプル コード ライセンスに基づいてリリースされています。
このリポジトリが役立つと思われる場合は、私たちの成果を引用することを検討してください。
@inproceedings{4m,
title={{4M}: Massively Multimodal Masked Modeling},
author={David Mizrahi and Roman Bachmann and O{u{g}}uzhan Fatih Kar and Teresa Yeo and Mingfei Gao and Afshin Dehghan and Amir Zamir},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023},
}
@article{4m21,
title={{4M-21}: An Any-to-Any Vision Model for Tens of Tasks and Modalities},
author={Roman Bachmann and O{u{g}}uzhan Fatih Kar and David Mizrahi and Ali Garjani and Mingfei Gao and David Griffiths and Jiaming Hu and Afshin Dehghan and Amir Zamir},
journal={arXiv 2024},
year={2024},
}


