storm
v1.0.0 & EMNLP 2024 Paper Accepted!
|研究プレビュー|ストームペーパー|コストームペーパー|ウェブサイト|
最新ニュース
[2024/09] Co-STORM コードベースがリリースされ、 knowledge-storm Python パッケージ v1.0.0 に統合されました。 pip install knowledge-storm --upgrade実行して確認してください。
[2024/09] 人とAIの協働ナレッジキュレーションを支援する協働STORM(Co-STORM)を導入します! Co-STORM Paper が EMNLP 2024 メインカンファレンスに採択されました。
[2024/07] pip install knowledge-stormでパッケージをインストールできるようになりました。
[2024/07] ユーザー提供のドキュメントに基づくサポートを行うためにVectorRMを追加し、検索エンジン ( YouRM 、 BingSearch ) の既存のサポートを補完します。 (#58をチェックしてください)
[2024/07] 開発者向けに、Python の streamlit フレームワークで構築された最小限のユーザー インターフェイスをリリースします。ローカル開発やデモ ホスティングに便利です (チェックアウト #54)
[2024/06] NAACL 2024にSTORMを出展します! 6 月 17 日のポスター セッション 2 で私たちを見つけるか、プレゼンテーション資料をご覧ください。
[2024/05] rm.py に Bing Search のサポートを追加しました。 GPT-4oを使用して STORM をテストします。GPT GPT-4oモデルを使用して、デモの記事生成部分を構成します。
[2024/04] STORMコードベースのリファクタリング版をリリースしました! STORM パイプラインのインターフェイスを定義し、STORM-wiki ( src/storm_wikiを確認してください) を再実装して、パイプラインをインスタンス化する方法を示します。さまざまな言語モデルのカスタマイズと検索/検索の統合をサポートする API を提供します。
このシステムは、多くの場合大幅な編集が必要となる出版用の記事を作成することはできませんが、経験豊富な Wikipedia 編集者は、執筆前の段階ではこのシステムが役立つと感じています。
70,000 人以上がライブリサーチプレビューを試しました。 STORM があなたの知識探索の旅にどのように役立つかを試してみてください。システムの改善に役立つフィードバックをお寄せください。
STORM は、引用を含む長い記事の生成を 2 つのステップに分けて行います。
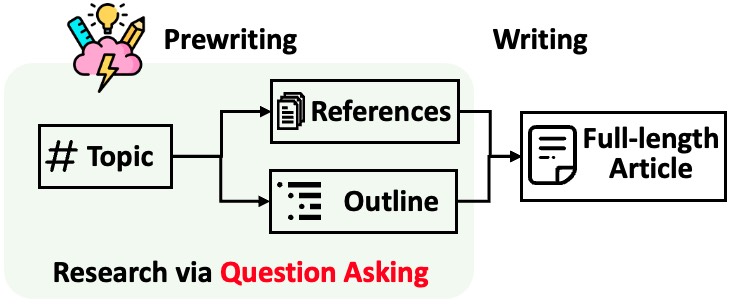
STORM は、調査プロセスの自動化の核心は、適切な質問を自動的に思いつくことであると特定しています。言語モデルに質問を直接促すことはうまく機能しません。質問の深さと幅を改善するために、STORM は 2 つの戦略を採用しています。
Co-STORMは、チーム間のスムーズなコラボレーションをサポートするターン管理ポリシーを実装する協調的な談話プロトコルを提案します。
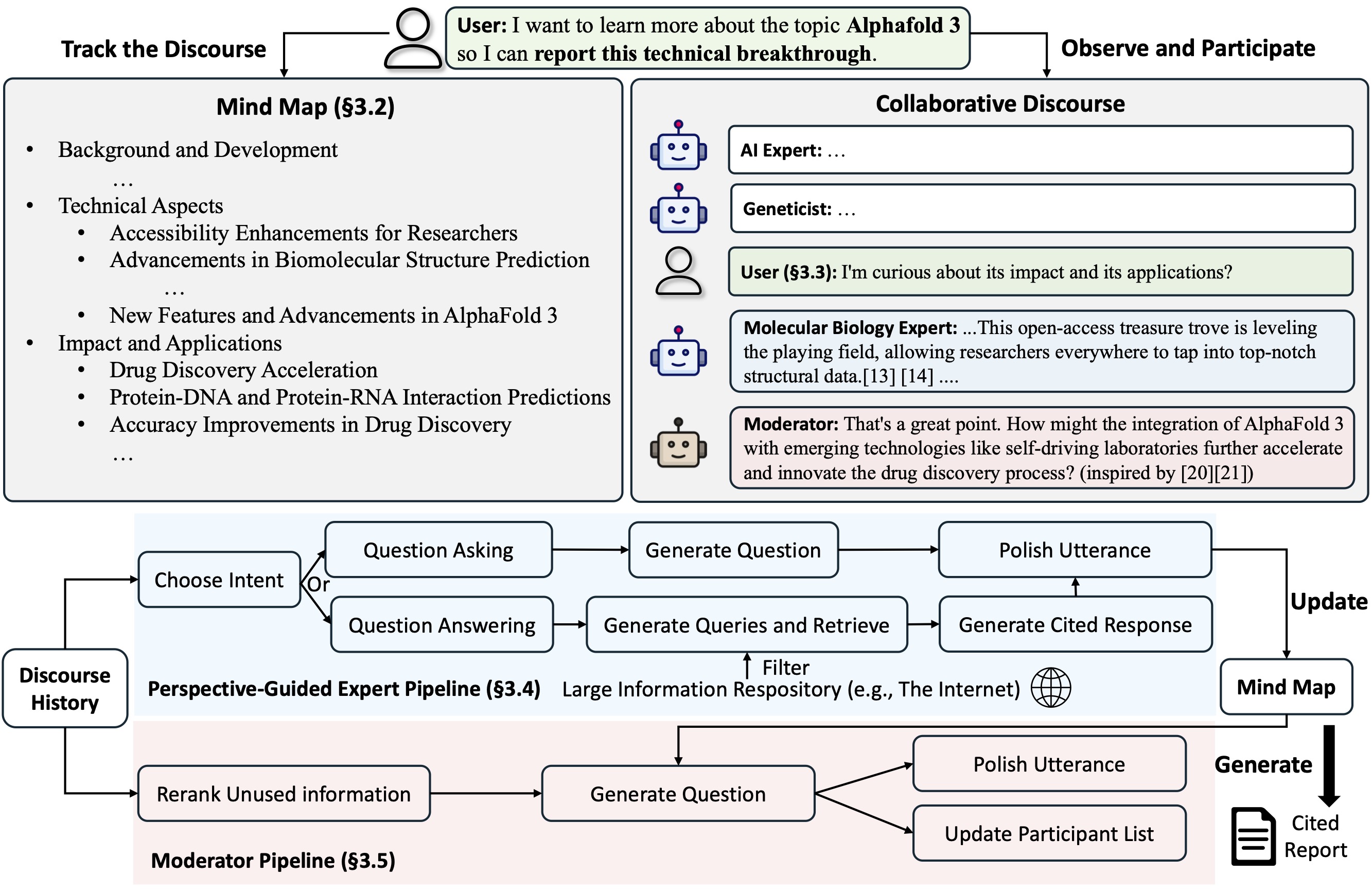
Co-STORM は、動的に更新されたマインド マップも維持します。これは、人間のユーザーとシステムの間に共有の概念空間を構築することを目的として、収集した情報を階層概念構造に編成します。マインド マップは、話が長くて深い場合に精神的負荷を軽減するのに役立つことが証明されています。
STORM と Co-STORM は両方とも、dspy を使用して高度にモジュール化された方法で実装されます。
ナレッジ ストーム ライブラリをインストールするには、 pip install knowledge-storm使用します。
STORM エンジンの動作を直接変更できるソース コードをインストールすることもできます。
git リポジトリのクローンを作成します。
git clone https://github.com/stanford-oval/storm.git
cd storm必要なパッケージをインストールします。
conda create -n storm python=3.11
conda activate storm
pip install -r requirements.txt現在、パッケージは以下をサポートしています:
OpenAIModel 、 AzureOpenAIModel 、 ClaudeModel 、 VLLMClient 、 TGIClient 、 TogetherClient 、 OllamaClient 、 GoogleModel 、 DeepSeekModel 、 GroqModelYouRM 、 BingSearch 、 VectorRM 、 SerperRM 、 BraveRM 、 SearXNG 、 DuckDuckGoSearchRM 、 TavilySearchRM 、 GoogleSearch 、およびAzureAISearch?より多くの言語モデルをKnowledge_storm/lm.pyに統合し、検索エンジン/レトリバーをknowledge_storm/rm.pyに統合するためのPRを高く評価します。
STORM と Co-STORM はどちらも情報キュレーション層で動作するため、情報取得モジュールと言語モデル モジュールを設定して、それぞれRunnerクラスを作成する必要があります。
STORM ナレッジ キュレーション エンジンは、単純な Python STORMWikiRunnerクラスとして定義されます。 You.com 検索エンジンと OpenAI モデルの使用例を次に示します。
import os
from knowledge_storm import STORMWikiRunnerArguments , STORMWikiRunner , STORMWikiLMConfigs
from knowledge_storm . lm import OpenAIModel
from knowledge_storm . rm import YouRM
lm_configs = STORMWikiLMConfigs ()
openai_kwargs = {
'api_key' : os . getenv ( "OPENAI_API_KEY" ),
'temperature' : 1.0 ,
'top_p' : 0.9 ,
}
# STORM is a LM system so different components can be powered by different models to reach a good balance between cost and quality.
# For a good practice, choose a cheaper/faster model for `conv_simulator_lm` which is used to split queries, synthesize answers in the conversation.
# Choose a more powerful model for `article_gen_lm` to generate verifiable text with citations.
gpt_35 = OpenAIModel ( model = 'gpt-3.5-turbo' , max_tokens = 500 , ** openai_kwargs )
gpt_4 = OpenAIModel ( model = 'gpt-4o' , max_tokens = 3000 , ** openai_kwargs )
lm_configs . set_conv_simulator_lm ( gpt_35 )
lm_configs . set_question_asker_lm ( gpt_35 )
lm_configs . set_outline_gen_lm ( gpt_4 )
lm_configs . set_article_gen_lm ( gpt_4 )
lm_configs . set_article_polish_lm ( gpt_4 )
# Check out the STORMWikiRunnerArguments class for more configurations.
engine_args = STORMWikiRunnerArguments (...)
rm = YouRM ( ydc_api_key = os . getenv ( 'YDC_API_KEY' ), k = engine_args . search_top_k )
runner = STORMWikiRunner ( engine_args , lm_configs , rm ) STORMWikiRunnerインスタンスは、単純なrunメソッドで呼び出すことができます。
topic = input ( 'Topic: ' )
runner . run (
topic = topic ,
do_research = True ,
do_generate_outline = True ,
do_generate_article = True ,
do_polish_article = True ,
)
runner . post_run ()
runner . summary ()do_research : True の場合、さまざまな観点からの会話をシミュレートして、トピックに関する情報を収集します。それ以外の場合は、結果をロードします。do_generate_outline : True の場合、トピックのアウトラインを生成します。それ以外の場合は、結果をロードします。do_generate_article : True の場合、概要と収集した情報に基づいてトピックの記事を生成します。それ以外の場合は、結果をロードします。do_polish_article : True の場合、要約セクションを追加し、(オプションで) 重複コンテンツを削除して記事を磨きます。それ以外の場合は、結果をロードします。Co-STORM ナレッジ キュレーション エンジンは、単純な Python CoStormRunnerクラスとして定義されます。ここでは、Bing 検索エンジンと OpenAI モデルの使用例を示します。
from knowledge_storm . collaborative_storm . engine import CollaborativeStormLMConfigs , RunnerArgument , CoStormRunner
from knowledge_storm . lm import OpenAIModel
from knowledge_storm . logging_wrapper import LoggingWrapper
from knowledge_storm . rm import BingSearch
# Co-STORM adopts the same multi LM system paradigm as STORM
lm_config : CollaborativeStormLMConfigs = CollaborativeStormLMConfigs ()
openai_kwargs = {
"api_key" : os . getenv ( "OPENAI_API_KEY" ),
"api_provider" : "openai" ,
"temperature" : 1.0 ,
"top_p" : 0.9 ,
"api_base" : None ,
}
question_answering_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 1000 , ** openai_kwargs )
discourse_manage_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 500 , ** openai_kwargs )
utterance_polishing_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 2000 , ** openai_kwargs )
warmstart_outline_gen_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 500 , ** openai_kwargs )
question_asking_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 300 , ** openai_kwargs )
knowledge_base_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 1000 , ** openai_kwargs )
lm_config . set_question_answering_lm ( question_answering_lm )
lm_config . set_discourse_manage_lm ( discourse_manage_lm )
lm_config . set_utterance_polishing_lm ( utterance_polishing_lm )
lm_config . set_warmstart_outline_gen_lm ( warmstart_outline_gen_lm )
lm_config . set_question_asking_lm ( question_asking_lm )
lm_config . set_knowledge_base_lm ( knowledge_base_lm )
# Check out the Co-STORM's RunnerArguments class for more configurations.
topic = input ( 'Topic: ' )
runner_argument = RunnerArgument ( topic = topic , ...)
logging_wrapper = LoggingWrapper ( lm_config )
bing_rm = BingSearch ( bing_search_api_key = os . environ . get ( "BING_SEARCH_API_KEY" ),
k = runner_argument . retrieve_top_k )
costorm_runner = CoStormRunner ( lm_config = lm_config ,
runner_argument = runner_argument ,
logging_wrapper = logging_wrapper ,
rm = bing_rm ) CoStormRunnerインスタンスは、 warmstart()メソッドとstep(...)メソッドを使用して呼び出すことができます。
# Warm start the system to build shared conceptual space between Co-STORM and users
costorm_runner . warm_start ()
# Step through the collaborative discourse
# Run either of the code snippets below in any order, as many times as you'd like
# To observe the conversation:
conv_turn = costorm_runner . step ()
# To inject your utterance to actively steer the conversation:
costorm_runner . step ( user_utterance = "YOUR UTTERANCE HERE" )
# Generate report based on the collaborative discourse
costorm_runner . knowledge_base . reorganize ()
article = costorm_runner . generate_report ()
print ( article )さまざまな構成で STORM および Co-STORM を実行するためのクイック スタートとして、サンプル フォルダーにスクリプトが用意されています。
API キーを設定するには、 secrets.tomlを使用することをお勧めします。ルート ディレクトリの下にファイルsecrets.tomlを作成し、次の内容を追加します。
# Set up OpenAI API key.
OPENAI_API_KEY= " your_openai_api_key "
# If you are using the API service provided by OpenAI, include the following line:
OPENAI_API_TYPE= " openai "
# If you are using the API service provided by Microsoft Azure, include the following lines:
OPENAI_API_TYPE= " azure "
AZURE_API_BASE= " your_azure_api_base_url "
AZURE_API_VERSION= " your_azure_api_version "
# Set up You.com search API key.
YDC_API_KEY= " your_youcom_api_key "デフォルト構成のgptファミリ モデルで STORM を実行するには:
次のコマンドを実行します。
python examples/storm_examples/run_storm_wiki_gpt.py
--output-dir $OUTPUT_DIR
--retriever you
--do-research
--do-generate-outline
--do-generate-article
--do-polish-articleお気に入りの言語モデルを使用するか、独自のコーパスに基づいて STORM を実行するには、 examples/storm_examples/README.md を確認してください。
デフォルト構成のgptファミリ モデルで Co-STORM を実行するには、
BING_SEARCH_API_KEY="xxx"とENCODER_API_TYPE="xxx"をsecrets.tomlに追加しますpython examples/costorm_examples/run_costorm_gpt.py
--output-dir $OUTPUT_DIR
--retriever bingソース コードをインストールしている場合は、独自のユースケースに基づいて STORM をカスタマイズできます。 STORM エンジンは 4 つのモジュールで構成されています。
各モジュールのインターフェースはknowledge_storm/interface.pyで定義され、その実装はknowledge_storm/storm_wiki/modules/*でインスタンス化されます。これらのモジュールは、特定の要件に応じてカスタマイズできます (たとえば、段落全体ではなく箇条書き形式でセクションを生成するなど)。
ソースコードをインストールしている場合は、独自のユースケースに基づいて Co-STORM をカスタマイズできます
knowledge_storm/interface.pyで定義され、その実装はknowledge_storm/collaborative_storm/modules/co_storm_agents.pyでインスタンス化されます。さまざまな LLM エージェント ポリシーをカスタマイズできます。knowledge_storm/collaborative_storm/engine.pyのDiscourseManager介したターン ポリシー管理の実装例を提供します。カスタマイズしてさらに改良することも可能です。 自動知識キュレーションと複雑な情報探索の研究を促進するために、私たちのプロジェクトは次のデータセットをリリースしています。
FreshWiki データセットは、2022 年 2 月から 2023 年 9 月までに最も編集されたページに焦点を当てた 100 件の高品質な Wikipedia 記事のコレクションです。詳細については、STORM 論文のセクション 2.1 を参照してください。
データセットは、huggingface から直接ダウンロードできます。データ汚染の問題を軽減するために、将来的に繰り返すことができるデータ構築パイプラインのソース コードをアーカイブします。
実際の複雑な情報探索タスクに対するユーザーの関心を調査するために、Web リサーチ プレビューから収集したデータを利用して WildSeek データセットを作成しました。トピックの多様性とデータの品質を確保するために、データをダウンサンプリングしました。各データ ポイントは、トピックと、そのトピックについて詳細な検索を実行するためのユーザーの目標で構成されるペアです。詳細については、Co-STORM 論文のセクション 2.2 および付録 A を参照してください。
WildSeek データセットはここから入手できます。
STORM 紙の実験については、ここからブランチNAACL-2024-code-backupに切り替えてください。
Co-STORM 紙実験の場合は、ブランチEMNLP-2024-code-backupに切り替えてください (今のところプレースホルダーですが、すぐに更新されます)。
私たちのチームは次のことに積極的に取り組んでいます。
ご質問やご提案がございましたら、お気軽にイシューまたはプルリクエストを開いてください。システムとコードベースを改善するための貢献を歓迎します。
連絡担当者: Yijia Shao および Yucheng Jiang
優れたオープンソース コンテンツを提供してくださった Wikipedia に感謝いたします。 FreshWiki データセットのソースは Wikipedia であり、Creative Commons Attribution-ShareAlike (CC BY-SA) ライセンスに基づいてライセンスされています。
このプロジェクトのロゴをデザインしてくれた Michelle Lam と、UI 開発を主導してくれた Dekun Ma に非常に感謝しています。
このコードまたはその一部を仕事で使用する場合は、論文を引用してください。
@misc { jiang2024unknownunknowns ,
title = { Into the Unknown Unknowns: Engaged Human Learning through Participation in Language Model Agent Conversations } ,
author = { Yucheng Jiang and Yijia Shao and Dekun Ma and Sina J. Semnani and Monica S. Lam } ,
year = { 2024 } ,
eprint = { 2408.15232 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL } ,
url = { https://arxiv.org/abs/2408.15232 } ,
}
@inproceedings { shao2024assisting ,
title = { {Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models} } ,
author = { Yijia Shao and Yucheng Jiang and Theodore A. Kanell and Peter Xu and Omar Khattab and Monica S. Lam } ,
year = { 2024 } ,
booktitle = { Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) }
}

