bulk
1.0.0
Bulk は、一括ラベルを適用するための迅速な開発者ツールです。 2D 埋め込みを含む準備されたデータセットがあれば、精度は低いものの、大量のアノテーションを迅速に追加できるインターフェイスを生成できます。
python -m pip install --upgrade pip
python -m pip install bulk
バルクの将来は、ノートブックで役立つウィジェットを提供することです。現時点では、 BaseTextExplorerがサポートされている主要なウィジェットです。前処理されたデータがあれば、エクスプローラーを使用してテキスト埋め込みの 2D UMAP を探索できます。
import pandas as pd
from umap import UMAP
from sklearn . pipeline import make_pipeline
# pip install "embetter[text]"
from embetter . text import SentenceEncoder
# Build a sentence encoder pipeline with UMAP at the end.
enc = SentenceEncoder ( 'all-MiniLM-L6-v2' )
umap = UMAP ()
text_emb_pipeline = make_pipeline (
enc , umap
)
# Load sentences
sentences = list ( pd . read_csv ( "tests/data/text.csv" )[ 'text' ])
# Calculate embeddings
X_tfm = text_emb_pipeline . fit_transform ( sentences )
# Write to disk. Note! Text column must be named "text"
df = pd . DataFrame ({ "text" : sentences })
df [ 'x' ] = X_tfm [:, 0 ]
df [ 'y' ] = X_tfm [:, 1 ]ウィジェットを使用するには、これを実行するだけです:
from bulk . widgets import BaseTextExplorer
widget = BaseTextExplorer ( df )
widget . show ()これにより、データに表示されるクラスターを迅速に探索できるようになります。マウス カーソルを押し続けると選択モードになり、項目を選択すると、右側にランダムなサブセットが表示されます。 [再サンプル] ボタンをクリックすると、選択内容から再サンプルできます。
選択を行うと、右側の更新でウィジェットが表示されますが、Python 属性からデータを取得することもできます。
widget . selected_idx
widget . selected_texts
widget . selected_dataframeこれらのクラスターを探索できるのは素晴らしいことですが、自由に使えるツールがもう少しあれば、すべてをもっと簡単に探索できるように感じます。特に、埋め込みスペースでクエリを使用できるように、エンコーダを周囲に配置したいと考えています。以下の UI では、テキスト プロンプトで色を更新することで、よりインタラクティブに探索できるようになります。
from embetter . text import SentenceEncoder
enc = SentenceEncoder ( 'all-MiniLM-L6-v2' )
# Pay attention here! The rows in df needs to align with the rows in X!
widget = BaseTextExplorer ( df , X = X , encoder = enc )
widget . show ()ipywidget や anywidget などのツールのおかげで、ノートブックをデータのニーズに応えられる場所にしておくためのツールの構築を本格的に開始できるようになりました。いくつかの適切なウィジェットがあれば、Jupyter ノートブックを超えることは決してできません。
このプロジェクトの主な目的は、データ品質のためのツールに取り組むことです。データポイントを一括で選択できることは、始めるのに最適な場所のように思えます。おそらく、最初に注釈を付ける興味深いサブセットが見つかるかもしれません。おそらく、1 つであるはずの 2 つの異なるクラスターを見て驚くかもしれません。素晴らしいことはすべてノートブックで起こる可能性があります。
Bulk には、Bokeh を使用して埋め込みの UMAP 表現に基づいた注釈インターフェイスを提供する小さな Web アプリも付属しています。テキスト用のインターフェイスを提供します。このインターフェースは、このプロジェクトのオリジナルのインターフェース/機能でした。
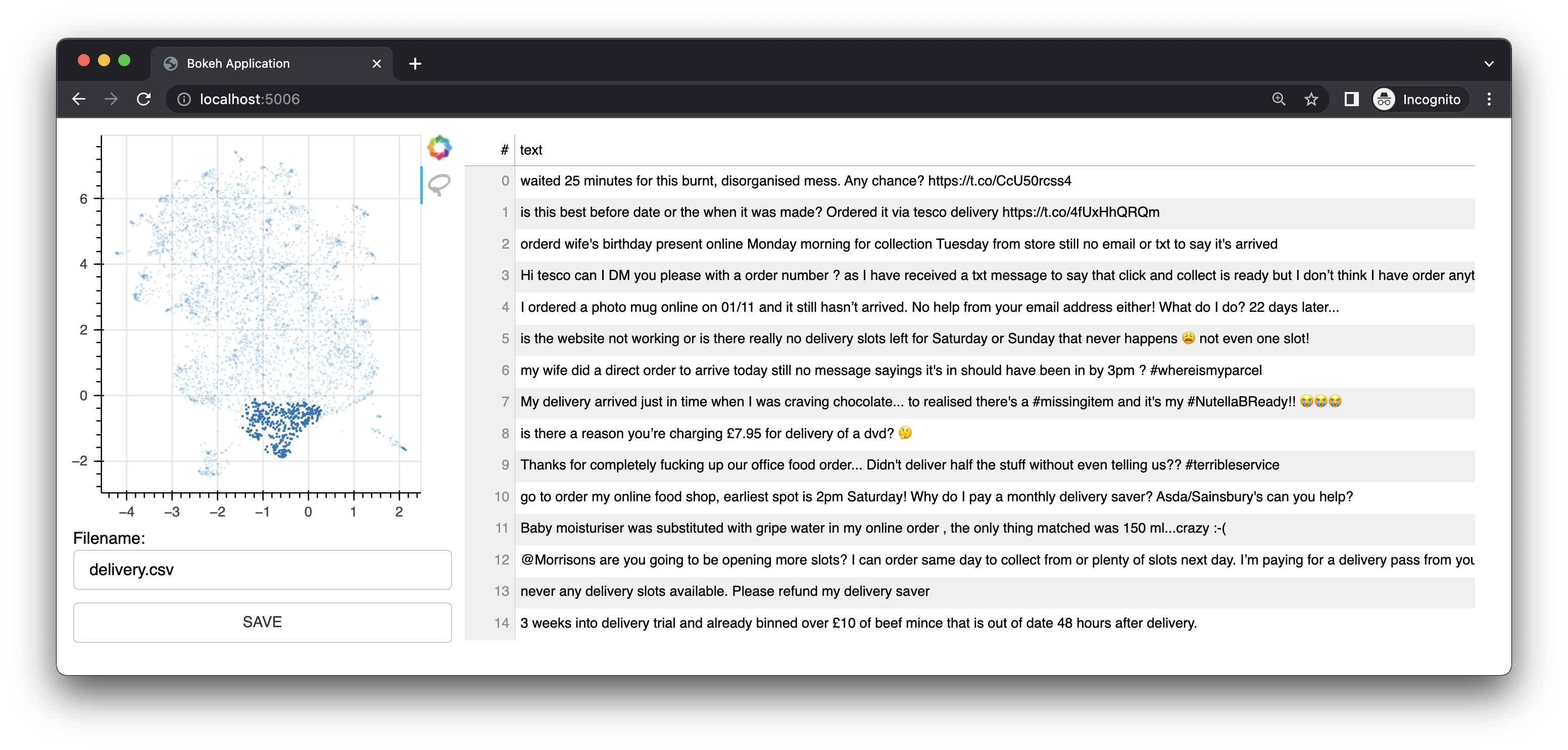
画像インターフェースも備えています。
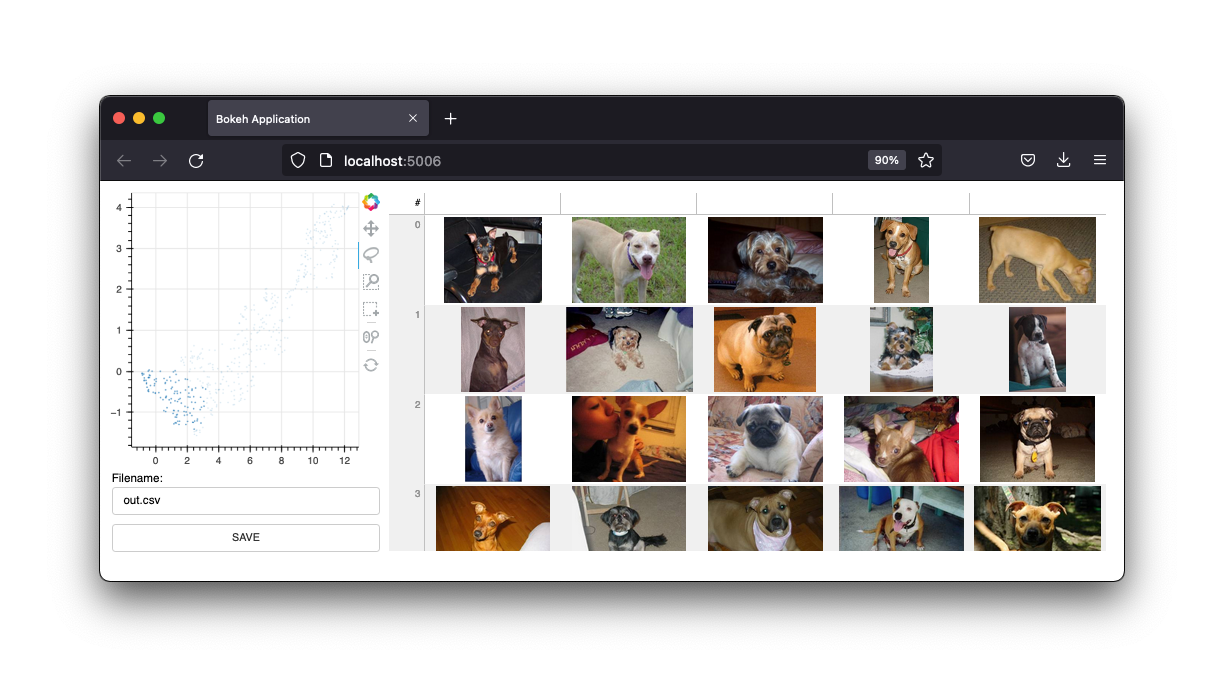
これらのインターフェイスは維持しますが、このプロジェクトの将来は Jupyter ノートブックのウィジェットになる予定です。ただし、Web アプリが依然として役立つことは確かです。
さらに詳しく知りたい場合は、テキストについては YouTube のこのビデオを、コンピュータ ビジョンについては YouTube のこのビデオをご覧ください。
テキストにバルクを使用するには、まず csv ファイルを準備する必要があります。
注記
以下の例では、embetter を使用して埋め込みを生成し、umap を使用して次元を削減します。ただし、好きなテキスト埋め込みツールを完全に自由に使用できます。これらのツールを個別にインストールする必要があります。 embetter は内部で文変換機能を使用していることに注意してください。
import pandas as pd
from umap import UMAP
from sklearn . pipeline import make_pipeline
# pip install "embetter[text]"
from embetter . text import SentenceEncoder
# Build a sentence encoder pipeline with UMAP at the end.
text_emb_pipeline = make_pipeline (
SentenceEncoder ( 'all-MiniLM-L6-v2' ),
UMAP ()
)
# Load sentences
sentences = list ( pd . read_csv ( "original.csv" )[ 'sentences' ])
# Calculate embeddings
X_tfm = text_emb_pipeline . fit_transform ( sentences )
# Write to disk. Note! Text column must be named "text"
df = pd . DataFrame ({ "text" : sentences })
df [ 'x' ] = X_tfm [:, 0 ]
df [ 'y' ] = X_tfm [:, 1 ]
df . to_csv ( "ready.csv" , index = False )これで、このready.csvファイルを使用して、一括ラベル付けを適用できるようになります。
python -m bulk text ready.csv
試してみるサンプル ファイルを探している場合は、このリポジトリでデモ .csv ファイルをダウンロードできます。このデータセットには、Kaggle で見つかったデータセットのサブセットが含まれています。オリジナルはここで見つけることができます。
「color」という追加の列を CSV ファイルに渡すこともできます。この列は、インターフェイス内のポイントの色付けに使用されます。
--keywordsコマンド ライン アプリに渡して、特定のキーワードを含む要素を強調表示することもできます。
python -m bulk text ready.csv --keywords "deliver,card,website,compliment"
以下の例では、 embetterライブラリを使用して、画像を一括ラベルするためのデータセットを作成します。
注記
以下の例では、embetter を使用して埋め込みを生成し、umap を使用して次元を削減します。ただし、好きなテキスト埋め込みツールを完全に自由に使用できます。これらのツールを個別にインストールする必要があります。 embetter は内部で TIMM を使用していることに注意してください。
import pathlib
import pandas as pd
from sklearn . pipeline import make_pipeline
from umap import UMAP
from sklearn . preprocessing import MinMaxScaler
# pip install "embetter[vision]"
from embetter . grab import ColumnGrabber
from embetter . vision import ImageLoader , TimmEncoder
# Build image encoding pipeline
image_emb_pipeline = make_pipeline (
ColumnGrabber ( "path" ),
ImageLoader ( convert = "RGB" ),
TimmEncoder ( 'xception' ),
UMAP (),
MinMaxScaler ()
)
# Make dataframe with image paths
img_paths = list ( pathlib . Path ( "downloads" , "pets" ). glob ( "*" ))
dataf = pd . DataFrame ({
"path" : [ str ( p ) for p in img_paths ]
})
# Make csv file with Umap'ed model layer
# Note! Bulk assumes the image path column to be called "path"!
X = image_emb_pipeline . fit_transform ( dataf )
dataf [ 'x' ] = X [:, 0 ]
dataf [ 'y' ] = X [:, 1 ]
dataf . to_csv ( "ready.csv" , index = False )これにより、次の方法で一括ロードできる CSV ファイルが生成されます。
python -m bulk image ready.csv
画像のサムネイルのセットを生成することもできます。これは、大規模なデータセットを操作する場合に便利です。
python -m bulk util resize ready.csv ready2.csv temp
これにより、サイズ変更されたすべての画像を含むtempという名前のフォルダーが作成されます。このフォルダーを--thumbnail-path引数として使用できます。
python -m bulk image ready2.csv --thumbnail-path temp
一括を使用して、いくつかのデータセットをダウンロードして再生することもできます。詳細については:
python -m bulk download --help
このインターフェイスはラベル付けを非常に迅速に行うのに役立ちますが、ラベル自体はかなりノイズが多い場合があります。このツールの意図された使用例は、prodi.gy で後で使用する興味深いサブセットを準備することです。


