MedCalc Bench
1.0.0
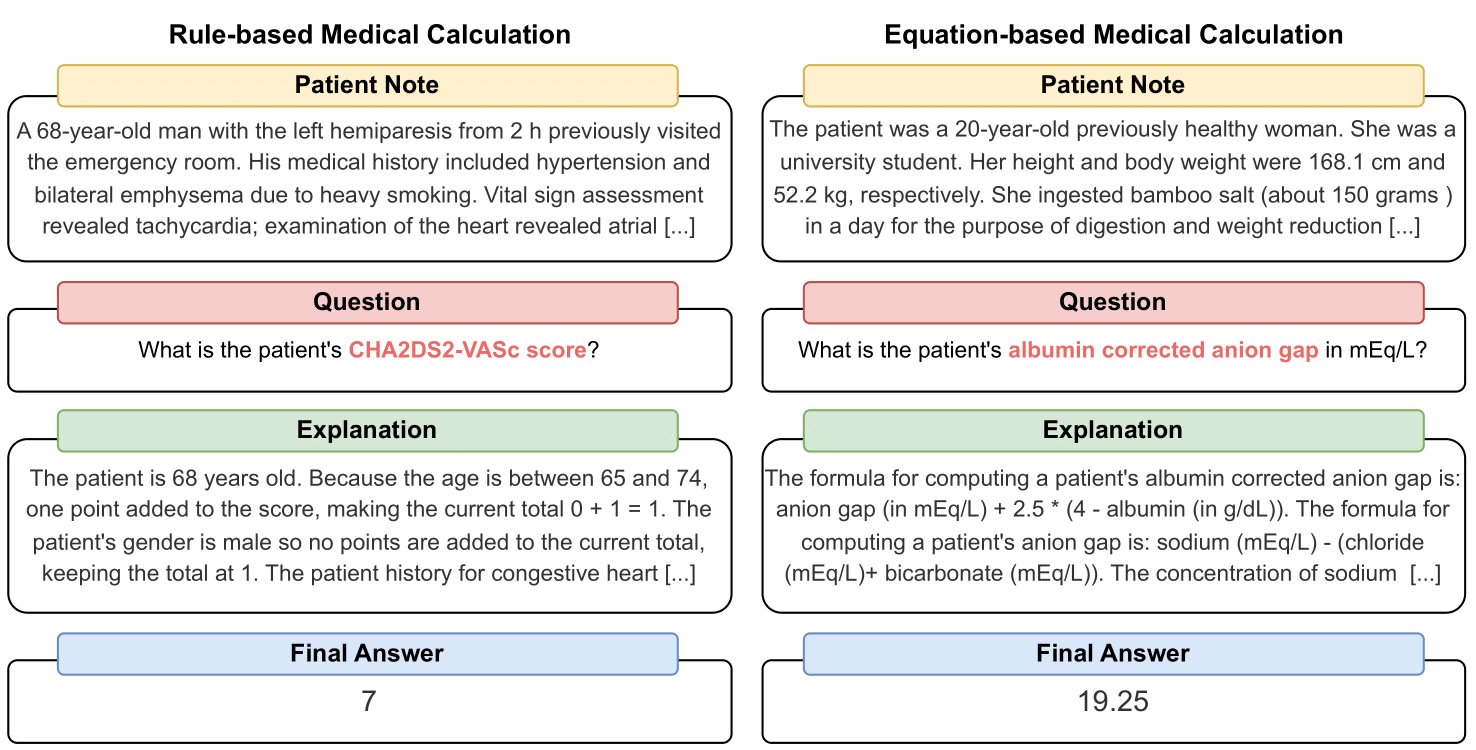
MedCalc-Bench は、臨床計算機として機能する LLM の機能をベンチマークするために使用される最初の医療計算データセットです。データセット内の各インスタンスは、患者のメモ、特定の臨床値の計算を求める質問、最終回答値、および最終回答がどのように得られたかを説明する段階的な解決策で構成されます。私たちのデータセットは、ルールベースの計算または方程式ベースの計算である 55 の異なる計算タスクをカバーしています。このデータセットには、10,053 インスタンスのトレーニング データセットと 1,047 インスタンスのテスト データセットが含まれています。
全体として、私たちのデータセットとベンチマークが、医療現場における LLM の計算推論スキルを向上させるための呼びかけとなることを願っています。
プレプリントは https://arxiv.org/abs/2406.12036 で入手できます。
MedCalc-Bench 評価データセットの CSV をダウンロードするには、このリポジトリのdatasetフォルダー内のファイルtest_data.csvをダウンロードしてください。 HuggingFace (https://huggingface.co/datasets/ncbi/MedCalc-Bench) から分割されたテスト セットをダウンロードすることもできます。
1,047 の評価インスタンスに加えて、オープンソース LLM の微調整に使用できる 10,053 インスタンスのトレーニング データセットも提供します (付録のセクション C を参照)。トレーニング データはdataset/train_data.csv.zipファイルにあり、解凍してtrain_data.csvを取得できます。このトレーニング データセットは、HuggingFace リンクのトレイン分割にもあります。
データセット内の各インスタンスには次の情報が含まれます。
このプロジェクトに必要なすべてのパッケージをインストールするには、コマンドconda env create -f environment.ymlを実行してください。このコマンドは、 medcalc-bench conda 環境を作成します。 OpenAI モデルを実行するには、この conda 環境で OpenAI キーを指定する必要があります。これを行うには、 medcalc-bench環境で次のコマンドを実行します: export OPENAI_API_KEY = YOUR_API_KEY 。ここで、 YOUR_API_KEY は OpenAI API キーです。次のコマンドを実行して、この環境で HuggingFace トークンを提供する必要もあります: export HUGGINGFACE_TOKEN=your_hugging_face_token ( your_hugging_face_tokenは、huggingface トークンです)。
論文から表 2 を再現するには、まずevaluationフォルダーにcd 。次に、コマンドpython run.py --model <model_name> and --prompt <prompt_style>を実行してください。
--modelのオプションは以下のとおりです。
--promptのオプションは以下のとおりです。
これから、すべての質問のステータスを出力する 1 つの jsonl ファイルを取得します。 run.pyを実行すると、結果は<model>_<prompt>.jsonlというファイルに保存されます。このファイルはoutputsフォルダーにあります。
jsonl 内の各インスタンスには、次のメタデータが関連付けられます。
{
"Row Number": Row index of the item,
"Calculator Name": Name of calculation task,
"Calculator ID": ID of the calculator,
"Category": type of calculation (risk, severity, diagnosis for rule-based calculators and lab, risk, physical, date, dosage for equation-based calculators),
"Note ID": ID of the note taken directly from MedCalc-Bench,
"Patient Note": Paragraph which is the patient note taken directly from MedCalc-Bench,
"Question": Question asking for a specific medical value to be computed,
"LLM Answer": Final Answer Value from LLM,
"LLM Explanation": Step-by-Step explanation by LLM,
"Ground Truth Answer": Ground truth answer value,
"Ground Truth Explanation": Step-by-step ground truth explanation,
"Result": "Correct" or "Incorrect"
}
さらに、各サブカテゴリの平均精度と標準偏差のパーセンテージをresults_<model>_<prompt_style>.jsonというタイトルの json で提供します。 1,047 個のインスタンスすべての累積精度と標準偏差は、JSON の「全体」キーで確認できます。このファイルはresultsフォルダーにあります。
本文の表 2 の結果に加えて、LLM 自身に算術演算を行わせるのではなく、算術演算を実行するコードを書くように LLM に促しました。この結果は付録 D にあります。計算能力が限られているため、GPT-3.5 と GPT-4 の結果のみを実行しました。プロンプトを調べてこの設定で実行するには、 evaluationフォルダー内のgenerate_code_prompt.pyファイルを調べてください。
このコードを実行するには、 evaluationsフォルダーにcdて次のコマンドを実行します: python generate_code_prompt.py --gpt <gpt_model> 。 <gpt_model>のオプションは、GPT-4 を実行する場合は4 、GPT-3.5-turbo-16k を実行する場合は35です。結果は、 outputsフォルダー内のcode_exec_{model_name}.jsonlという名前の jsonl ファイルに保存されます。この場合、GPT-4 を使用して実行することを選択した場合、 model_name gpt_4になることに注意してください。それ以外の場合、GPT-3.5-turbo で実行することを選択した場合、 model_name gpt_35_16kになります。
コード インタープリターの結果の jsonl ファイル内の各インスタンスのメタデータは、上のセクションで提供されるインスタンス情報と同じです。唯一の違いは、ユーザーとアシスタント間の LLM チャット履歴が保存され、「LLM 説明」キーの代わりに「LLM チャット履歴」キーがあることです。さらに、サブカテゴリと全体の精度は、 results_<model_name>_code_augmented.jsonという名前の JSON ファイルに保存されます。この JSON はresultsフォルダーにあります。
この研究は、NIH 学内研究プログラム、国立医学図書館によって支援されました。さらに、ソーレン ダン氏による貢献は、米国科学財団 (受賞 OAC 電話番号:2005572) とイリノイ州によって支援されているデルタの高度なコンピューティングおよびデータ リソースを使用して行われました。デルタは、イリノイ大学アーバナ シャンペーン校 (UIUC) とその国立スーパーコンピューティング アプリケーション センター (NCSA) の共同研究です。
MedCalc-Bench での患者ノートの管理では、PubMed Central で公開された症例レポート記事および臨床医が作成した匿名の患者のビネットから一般に入手可能な患者ノートのみを使用します。そのため、この研究では個人を特定できる個人の健康情報は明らかにされません。 MedCalc-Bench は LLM の医療計算機能を評価するように設計されていますが、このデータセットは臨床専門家によるレビューや監視なしに直接診断に使用したり、医療上の意思決定を行うことを目的としたものではないことに注意してください。個人は私たちの研究に基づいてのみ健康行動を変えるべきではありません。
セクション 1 で説明したように、医療用電卓は臨床現場で一般的に使用されています。ドメイン固有のアプリケーションに LLM を使用することへの関心が急速に高まっているため、医療従事者は ChatGPT などのチャットボットに医療計算タスクの実行を直接促す可能性があります。ただし、これらのタスクにおける LLM の機能は現時点では不明です。医療は一か八かの分野であり、間違った医療計算は誤診、不適切な治療計画、患者への潜在的危害などの重大な結果につながる可能性があるため、医療計算における LLM のパフォーマンスを徹底的に評価することが重要です。驚くべきことに、MedCalc-Bench データセットの評価結果は、研究されたすべての LLM が医療計算タスクに苦戦していることを示しています。最も有能なモデル GPT-4 は、ワンショット学習と思考連鎖プロンプトでは 50% の精度しか達成できません。そのため、私たちの研究は、現在の LLM がまだ医療計算に使用できる状態にないことを示しています。 MedCalc-Bench の高スコアは医療計算タスクにおける卓越性を保証するものではありませんが、このデータセットで失敗した場合は、モデルをそのような目的でまったく考慮してはいけないことを示していることに注意してください。言い換えれば、MedCalc-Bench に合格することは、モデルが医療計算に使用されるための必要条件 (十分条件ではない) であるべきであると考えています。
このデータセットへの変更 (つまり、新しいメモや計算機の追加) については、README 手順、test_set.csv および train_set.csv を更新します。これらのデータセットの古いバージョンは引き続きarchive/フォルダーに保存されます。また、HuggingFace のトレーニング セットとテスト セットも更新します。
このツールは、NCBI/NLM の計算生物学部門で実施された研究の結果を示します。このウェブサイトで作成された情報は、臨床専門家によるレビューや監督なしに直接診断に使用したり、医療上の意思決定を行うことを目的としたものではありません。個人は、このウェブサイトで生成された情報のみに基づいて健康行動を変更すべきではありません。 NIH は、このツールによって生成された情報の有効性や有用性を独自に検証しません。このウェブサイトで作成された情報について質問がある場合は、医療専門家に相談してください。 NCBI の免責事項ポリシーの詳細については、こちらをご覧ください。
計算機に応じて、データセットは、Python で実装されたテンプレートベースの関数から設計されたメモ、臨床医によって手書きされたメモ、またはデータセット Open-Patients から取得されたメモで構成されます。
Open-Patients は、3 つの異なるソースから取得した 180,000 件の患者のメモを集約したデータセットです。私たちは 3 つのソースすべてからのデータセットを使用する権限を持っています。最初のソースは、MIT ライセンスに基づいてリリースされている MedQA からの USMLE の質問です。データセットの 2 番目のソースは、Trec Clinical Decision Support と Trec Clinical Trial です。これらはどちらも政府所有のデータセットであり、一般に公開されているため、再配布が可能です。最後に、PMC-Patients は CC-BY-SA 4.0 ライセンスに基づいてリリースされているため、PMC-Patients を Open-Patients および MedCalc-Bench 内に組み込む許可はありますが、データセットは同じライセンスに基づいてリリースする必要があります。したがって、メモのソースである Open-Patients と、そこから厳選されたデータセットである MedCalc-Bench は、両方とも CC-BY-SA 4.0 ライセンスの下でリリースされています。
ライセンス規則の正当性に基づき、Open-Patients と MedCalc-Bench はいずれも CC-BY-SA 4.0 ライセンスに準拠していますが、権利侵害があった場合には、この文書の著者がすべての責任を負います。
@misc { khandekar2024medcalcbench ,
title = { MedCalc-Bench: Evaluating Large Language Models for Medical Calculations } ,
author = { Nikhil Khandekar and Qiao Jin and Guangzhi Xiong and Soren Dunn and Serina S Applebaum and Zain Anwar and Maame Sarfo-Gyamfi and Conrad W Safranek and Abid A Anwar and Andrew Zhang and Aidan Gilson and Maxwell B Singer and Amisha Dave and Andrew Taylor and Aidong Zhang and Qingyu Chen and Zhiyong Lu } ,
year = { 2024 } ,
eprint = { 2406.12036 } ,
archivePrefix = { arXiv } ,
primaryClass = { id='cs.CL' full_name='Computation and Language' is_active=True alt_name='cmp-lg' in_archive='cs' is_general=False description='Covers natural language processing. Roughly includes material in ACM Subject Class I.2.7. Note that work on artificial languages (programming languages, logics, formal systems) that does not explicitly address natural-language issues broadly construed (natural-language processing, computational linguistics, speech, text retrieval, etc.) is not appropriate for this area.' }
}

