MagicMix
1.0.0
MagicMix の実装: 拡散モデルを使用したセマンティック ミキシングに関する論文。
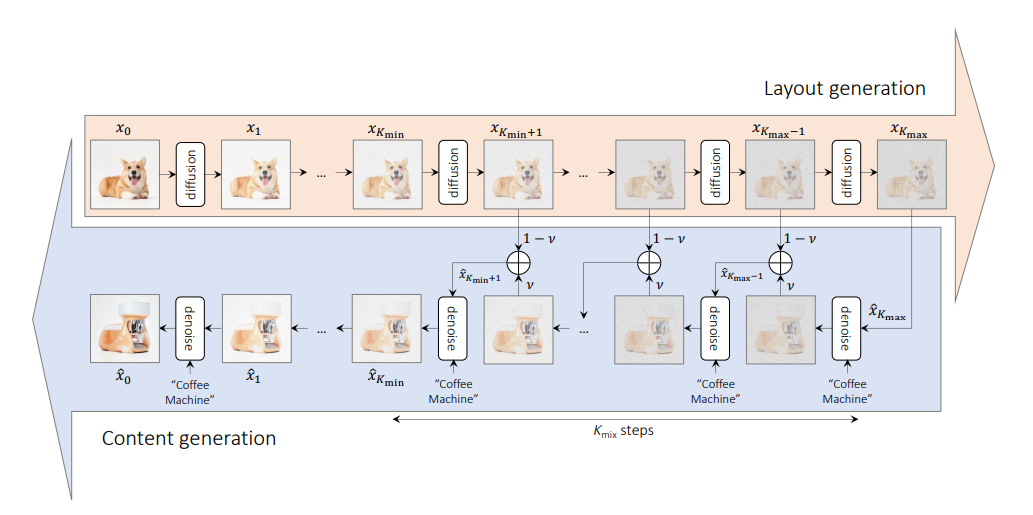
この方法の目的は、2 つの異なる概念を意味論的な方法で混合して、空間レイアウトと幾何学形状を維持しながら新しい概念を合成することです。
このメソッドは、レイアウト セマンティクスを提供する画像と、混合プロセスのコンテンツ セマンティクスを提供するプロンプトを取得します。
このメソッドには 3 つのパラメータがあります。
v : レイアウト生成フェーズで使用される補間定数です。 v の値が大きいほど、レイアウト生成プロセスに対するプロンプトの影響が大きくなります。kmaxおよびkmin : これらは、レイアウトおよびコンテンツ生成プロセスの範囲を決定します。 kmax の値が高くなると、元の画像のレイアウトに関する情報がより多く失われ、kmin の値が高くなると、コンテンツ生成プロセスのステップが増えます。 from PIL import Image
from magic_mix import magic_mix
img = Image . open ( 'phone.jpg' )
out_img = magic_mix ( img , 'bed' , kmax = 0.5 )
out_img . save ( "mix.jpg" ) python3 magic_mix.py
"phone.jpg"
"bed"
"mix.jpg"
--kmin 0.3
--kmax 0.6
--v 0.5
--steps 50
--seed 42
--guidance_scale 7.5
また、論文の例を再現するための実装の使用例については、デモ ノートブックを確認してください。
ディフューザー ライブラリのコミュニティ パイプラインを使用することもできます。
from diffusers import DiffusionPipeline , DDIMScheduler
from PIL import Image
pipe = DiffusionPipeline . from_pretrained (
"CompVis/stable-diffusion-v1-4" ,
custom_pipeline = "magic_mix" ,
scheduler = DDIMScheduler . from_pretrained ( "CompVis/stable-diffusion-v1-4" , subfolder = "scheduler" ),
). to ( 'cuda' )
img = Image . open ( 'phone.jpg' )
mix_img = pipe (
img ,
prompt = 'bed' ,
kmin = 0.3 ,
kmax = 0.5 ,
mix_factor = 0.5 ,
)
mix_img . save ( 'mix.jpg' )







私は論文の著者ではないので、これは正式な実装ではありません


