AI Guide and Demos zh_CN
1.0.0
過去の学習プロセスを振り返ると、Ng Enda 先生と Li Honyi 先生のビデオが、私の深い学習の旅に大きな助けとなりました。ユーモアあふれる解説法とシンプルで直感的な解説が、退屈な理論学習を生き生きと面白くしてくれます。
しかし、実際には、多くの学生は最初は大規模な外国モデルの API をどのように入手するかについて心配しますが、最終的には解決策を見つけることができますが、初めての難しさへの恐怖が常に学習の進歩を遅らせ、徐々に変化する状態です。 「ビデオを見るだけ」の。コメント欄でも同様の議論がよく見られるので、学生がこの閾値を越えられるように自分の空き時間を利用することにしました。これがプロジェクトの本来の目的でもあります。
このプロジェクトは、科学的なインターネット アクセスに関するチュートリアルを提供するものではなく、プラットフォームにカスタマイズされたインターフェイスに依存するものではなく、より互換性の高い OpenAI SDK を使用して、誰もがより一般的な知識を学べるようにします。
このプロジェクトは単純な API 呼び出しから始まり、徐々に大規模なモデルの世界に移行します。その過程で、 AI ビデオ要約、 LLM 微調整、 AI 画像生成などのスキルを習得します。
同時に学習するには、Li Honyi 教師のコース「生成人工知能入門」を視聴することを強くお勧めします。コース関連のリンクに簡単にアクセスできます。
現在、このプロジェクトでは CodePlayground も提供されており、ドキュメントに従って環境を設定し、1 行のコードでスクリプトを実行し、AI の魅力を体験できます。
?論文エッセイはPaperNotesにあり、大型モデルに関連する基本的な論文は徐々にアップロードされます。
基本的なイメージは準備ができています。独自の深層学習環境を構成していない場合は、Docker を試してみるとよいでしょう。
良い旅を!
--- :基礎知識、必要に応じて視聴するか、一時的にスキップしてください。コード ファイルの結果は記事に示されますが、コードを手動で実行することをお勧めします。ビデオ メモリが必要な場合があります。API : この記事では大規模モデルの API のみを使用しており、デバイスの制限を受けず、GPU がなくても実行できます。LLM : 大規模な言語モデルに関連する実践では、コード ファイルにビデオ メモリが必要になる場合があります。SD : 安定拡散、ビンセント図に関連する実践、およびコード ファイルにはビデオ メモリ要件があります。Fileコードをダウンロードでき、学習効果は同じになります。Setting -> Accelerator ->选择GPU 。代码执行程序->更改运行时类型->选择GPU 。| ガイド | タグ | 説明する | ファイル | オンライン |
|---|---|---|---|---|
| 00. Alibaba Big Model APIの取得手順 | API | 初めて登録する場合は、本人確認 (顔認証) を実行する必要があります。 | ||
| 01. LLM API の初めての紹介: 環境構成と複数ラウンドの対話のデモンストレーション | API | これは入門用の構成とデモであり、会話コードは Alibaba 開発ドキュメントから変更されています。 | コード | カグル コラボ |
| 02. 簡単に始められます: API と Gradio を使用して AI アプリケーションを構築します | API | Gradio を使用してシンプルな AI アプリケーションを構築する方法をガイドします。 | コード | コラボ |
| 03. 上級ガイド: プロンプトをカスタマイズして大規模モデルの問題解決機能を向上させる | API | Gradio バージョンと非 Gradio バージョンも提供され、コードの詳細が表示されます。 | コード | カグル コラボ |
| 04. LoRA を理解する: 線形層から注意メカニズムまで | --- | 正式に実践に入る前に、LoRA の基本概念を理解する必要があります。この記事では、線形層の LoRA 実装からアテンション メカニズムまでを説明します。 | ||
05. Hugging Face のAutoModelシリーズを理解する: さまざまなタスクのための自動モデル読み込みクラス | --- | これから使用するモジュールは、Hugging Face の AutoModel です。この記事も前提知識です (もちろん、疑問がある場合は読み飛ばして後で読むこともできます)。 | コード | カグル コラボ |
| 06. 始めましょう: 最初の言語モデルをデプロイします | LLM | 非常に基本的な言語モデルのデプロイメントを実装するこのプロジェクトには、これまでのところ GPU に対する難しい要件がないため、学習を続けることができます。 | コード app_fastapi.py app_flask.py | |
| 07. モデルパラメータとビデオメモリの関係、および精度の違いによる影響を調査する | --- | モデルパラメータとビデオメモリの対応を理解し、精度の異なるインポート方法を使いこなすことで、モデル選択がより上手になります。 | ||
| 08. LLM を微調整してみる: 唐の詩を書かせてみる | LLM | この記事は「03. 上級ガイド: 大規模モデルの問題解決能力を向上させるためのプロンプトのカスタマイズ」と同じです。基本的には「作成」ではなく「使用」に重点を置いています。これまでと同様に、全体的なプロセスを理解することができます。ハイパーパラメータ セクションを参照して、微調整への影響を確認してください。 | コード | カグル コラボ |
| 09. ビーム検索の深い理解: 原理、例、コードの実装 | --- | 例からコードのデモンストレーションに進み、ビーム検索の数学的説明を行うことで、前に読んだことによる混乱がいくらか解消され、最後に Hugging Face Transformers ライブラリを使用する簡単な例が示されます (前の記事をスキップした場合は試してみることができます)。 。 | コード | カグル コラボ |
| 10. Top-K と Top-P: サンプリング戦略と生成モデルにおける温度の影響 | --- | さらに他の世代戦略を示します。 | コード | カグル コラボ |
| 11. DPO 微調整の例: 人間の好みに応じて LLM 大きな言語モデルを最適化する | LLM | DPOを使用した微調整の例。 | コード | カグル コラボ |
| 12. Inseq 機能の属性: LLM の出力を視覚的に解釈する | LLM | 翻訳とテキスト生成 (穴埋め) タスクの視覚的な例。 | コード | カグル コラボ |
| 13. AI に存在する可能性のあるバイアスを理解する | LLM | コードを理解する必要はなく、暇なときに楽しい探索として使用できます。 | コード | カグル コラボ |
| 14. PEFT: LoRA を大規模モデルに迅速に適用する | --- | モデルをインポートした後に LoRA レイヤーを追加する方法を学習します。 | コード | カグル コラボ |
| 15. API を使用して AI ビデオを実装する概要: 独自の AI ビデオ アシスタントを作成する | APIとLLM | 一般的な AI ビデオ要約アシスタントの背後にある原則を学び、AI ビデオ要約の実装を開始します。 | コード - フルバージョン コード - Lite バージョン ?スクリプト | カグル コラボ |
| 16. LoRA を使用して安定拡散を微調整する: 錬金術炉を分解し、最初の AI ペイントを実装する | SD | LoRA を使用して Vincent ダイアグラム モデルを微調整すると、LoRA ファイルを他の人に提供することもできるようになりました。 | コード コード - Lite バージョン | カグル コラボ |
| 17. RTN モデルの量子化に関する簡単な説明: 非対称と対称.md | --- | RTN モデルの定量的な動作をさらに理解するために、この記事では INT8 を例として説明します。 | コード | カグル コラボ |
| 18. モデル定量化技術の概要とGGUF/GGMLファイル形式の解析 | --- | これは、GGUF/GGML を使用する際の疑問のいくつかを解決する可能性がある概要記事です。 | ||
| 19a. 読み込みから会話まで: Transformers を使用したローカルでの量子化 LLM モデル (GPTQ および AWQ) の実行 19b. 読み込みから会話まで: Llama-cpp-python を使用してローカルで量子化 LLM ラージ モデル (GGUF) を実行する | LLM | 70 億 (7B) のパラメーターを持つ定量的モデルをコンピューターにデプロイします。この記事ではグラフィック カードは必要ありません。 19 a Transformers の使用。GPTQ および AWQ 形式でのモデルの読み込みが含まれます。 19 b Llama-cpp-python を使用し、GGUF 形式でのモデルの読み込みを行います。 さらに、ローカル大規模モデルの対話インタラクション機能も完成します。 | コードトランスフォーマー コード-Llama-cpp-python ?スクリプト | |
| 20. RAG 入門演習: 文書分割からベクトルデータベース、質疑応答構築まで | LLM | RAG 関連のプラクティス。 再帰的なテキストのチャンク化がどのように機能するかを学びます。 | コード | |
| 21. BPE と WordPiece: Tokenizer の動作原理とサブワード分割方法を理解する | --- | トークナイザーの基本操作。 一般的なサブワード セグメンテーション手法である BPE と WordPiece について学びます。 アテンション マスク (アテンション マスク) とトークン タイプ ID (トークン タイプ ID) について理解します。 | コード | カグル コラボ |
| 22. 課題 - Bert の抽出的質問応答の微調整 | これは、BERT を使用して下流の質問と回答のタスクを調整する課題です。これを試して、すべてのヒントを含むガイド記事を 1 週間後に提供します。または後で残しておきます。 紹介記事では課題の説明は省略し、学習用に 2 つのバージョンのコードをアップロードしますので、ご安心ください。 ここには期限はありません。 | コード - 割り当て | カグル コラボ |
ヒント
ウェアハウスをプルして.mdローカルで読み取る場合は、数式エラーが発生したときに、 Ctrl+FまたはCommand+F使用して\_を検索し、すべてを_に置き換えてください。
さらに読む:
| ガイド | 説明する |
|---|---|
| a. HFD を使用して、Hugging Face モデルとデータ セットのダウンロードを高速化します。 | モデルのダウンロードが遅すぎると感じる場合は、この記事を参照して構成してください。 プロキシ関連の 443 エラーが発生した場合は、この記事も確認してみてください。 |
| b. 基本的なコマンドラインコマンドのクイックチェック (Linux/Mac に適用) | コマンド ライン コマンドのクイック チェックには、基本的に、現在のウェアハウスに関連するすべてのコマンドが含まれています。混乱した場合は確認してください。 |
| c. いくつかの問題の解決策 | ここでは、プロジェクトの運用中に発生する可能性のあるいくつかの問題を解決します。 - リモート ウェアハウスをプルしてローカルの変更をすべて上書きするにはどうすればよいですか? - Hugging Face でダウンロードしたファイルの表示と削除、および保存パスの変更方法を教えてください。 |
| d. GGUF モデルをロードする方法 (Shared/Shared/Split/00001-of-0000... の解決策) | - GGUF についてトランスフォーマーの新機能について学びます。 - Transformers/Llama-cpp-python/Ollama を使用して、GGUF 形式のモデル ファイルをロードします。 - 断片化した GGUF ファイルをマージする方法を学びます。 ・LLama-cpp-pythonがオフロードできない問題を解決。 |
| e. データの強化: torchvision.transforms の一般的なメソッドの分析 | - 一般的に使用される画像データの補正方法を理解します。 コード | コラボ |
| f. クロスエントロピー損失関数 nn.CrossEntropyLoss() 詳細な説明と重要なポイントのリマインダー (PyTorch) | - クロスエントロピー損失と PyTorch 実装の数学的原理を理解します。 - 初めて使用するときの注意点を学びます。 |
| g. 埋め込み層 nn.Embedding() の詳細な説明と重要なポイントのリマインダー (PyTorch) | - 埋め込みレイヤーと単語埋め込みの概念を理解します。 - 事前トレーニングされたモデルを使用して埋め込みを視覚化します。 コード | コラボ |
| h. Docker を使用してディープラーニング環境を迅速に構成する (Linux) h. Docker の基本コマンドと一般的なエラー解決の概要 | - 2 行のコマンドを使用して深層学習環境を構成します - Dockerの基本コマンドの紹介 - 使用中によくある 3 つのエラーを解決します |
フォルダーの説明:
デモ
すべてのコード ファイルはそこに保存されます。
データ
コードで使用される可能性のある小さなデータを保存します。このフォルダーに注意を払う必要はありません。
GenAI_PDF
こちらはコース【生成人工知能入門】の課題のPDFファイルで、元々はGoogle Driveに保存されていたのでアップロードしました。
ガイド
すべてのガイダンス文書はそこに保管されます。
資産
.md ファイルで使用されている画像は次のとおりです。このフォルダーに注意を払う必要はありません。
紙のメモ
論文エッセイ。
コードプレイグラウンド
いくつかの興味深いコード スクリプトの例 (Toy バージョン)。
README.md
summaryer.py ?スクリプト
AIによる映像・音声・字幕の要約。
chat.py ?スクリプト
AIの会話。
生成型人工知能の学習リソースの概要
コースのホームページ
公式 | 認定ビデオ: YouTube |
中国語のミラー版の作成と共有は、Li Honyi 先生の許可を得ています。無私の知識の共有に感謝します。
PS 中国語のイメージは、ジョブ コード (ローカル操作) のすべての機能を完全に実現します。Kaggle は、中国で直接接続できるオンライン プラットフォームです。英語の Colab リンクは、元のジョブに対応しています。そのうちの 1 つを選択するだけで研究を完了できます。
実際のニーズに応じて、以下から学習環境を準備する方法を選択し、 ►またはテキストをクリックして展開します。
Kaggle (国内直接接続、推奨): 詳細については、記事「Kaggle: 無料の GPU 使用ガイド、Colab の理想的な代替案」をお読みください。
Colab (科学インターネットへのアクセスが必要)
プロジェクト内のコード ファイルは両方のプラットフォームで同期されます。
Linux (Ubuntu) :
sudo apt-get update
sudo apt-get install gitmacOS :
まず Homebrew をインストールします。
/bin/bash -c " $( curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh ) "次に、次を実行します。
brew install gitWindows :
Git for Windows からダウンロードしてインストールします。
Linux (Ubuntu) :
sudo apt-get update
sudo apt-get install wget curlmacOS :
brew install wget curlWindows :
Wget for Windows および Curl 公式 Web サイトからダウンロードしてインストールします。
Anaconda 公式 Web サイトにアクセスし、メール アドレスを入力してメールを確認すると、次の内容が表示されます。
Download Nowクリックし、適切なバージョンを選択してダウンロードします (Anaconda と Miniconda の両方が利用可能です)。

Linux (Ubuntu) :
アナコンダをインストールする
バージョンを選択するには、repo.anaconda.com にアクセスしてください。
# 下载 Anaconda 安装脚本(以最新版本为例)
wget https://repo.anaconda.com/archive/Anaconda3-2024.10-1-Linux-x86_64.sh
# 运行安装脚本
bash Anaconda3-2024.10-1-Linux-x86_64.sh
# 按照提示完成安装(先回车,空格一直翻页,翻到最后输入 yes,回车)
# 安装完成后,刷新环境变量或者重新打开终端
source ~ /.bashrcMiniconda をインストールする(推奨)
バージョンの選択については、repo.anaconda.com/miniconda にアクセスしてください。 Miniconda は Anaconda の合理化されたバージョンで、Conda と Python のみが含まれています。
# 下载 Miniconda 安装脚本
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
# 运行安装脚本
bash Miniconda3-latest-Linux-x86_64.sh
# 按照提示完成安装(先回车,空格一直翻页,翻到最后输入 yes,回车)
# 安装完成后,刷新环境变量或者重新打开终端
source ~ /.bashrcmacOS :
対応して、Linux コマンドの URL を置き換えます。
アナコンダをインストールする
バージョンを選択するには、repo.anaconda.com にアクセスしてください。
Miniconda をインストールする(推奨)
バージョンの選択については、repo.anaconda.com/miniconda にアクセスしてください。
ターミナルに以下のコマンドを入力し、バージョン情報が表示されればインストール成功です。
conda --versioncat << ' EOF ' > ~/.condarc
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirror.nju.edu.cn/anaconda/pkgs/main
- https://mirror.nju.edu.cn/anaconda/pkgs/r
- https://mirror.nju.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirror.nju.edu.cn/anaconda/cloud
pytorch: https://mirror.nju.edu.cn/anaconda/cloud
EOF[!注記]
昨年利用可能だった多くのミラー ソースは現在利用できなくなっています。他のミラー サイトの現在の構成については、NTU の非常に優れたドキュメント「ミラー使用法ヘルプ」を参照してください。
注: Anaconda または Miniconda がすでにインストールされている場合、 pipシステムに含まれるため、追加のインストールは必要ありません。
Linux (Ubuntu) :
sudo apt-get update
sudo apt-get install python3-pipmacOS :
brew install python3Windows :
Python をダウンロードしてインストールし、「Python を PATH に追加」オプションがチェックされていることを確認します。
コマンド プロンプトを開いて次のように入力します。
python -m ensurepip --upgradeターミナルに以下のコマンドを入力し、バージョン情報が表示されればインストール成功です。
pip --versionpip config set global.index-url https://mirrors.aliyun.com/pypi/simple次のコマンドを使用してプロジェクトをプルします。
git clone https://github.com/Hoper-J/AI-Guide-and-Demos-zh_CN.git
cd AI-Guide-and-Demos-zh_CNバージョンに制限はありません。それ以降も可能です。
conda create -n aigc python=3.9作成が完了したら、 yと Enter を押して仮想環境をアクティブ化します。
conda activate aigc次に、基本的な依存関係をインストールする必要があります。CUDA 11.8 を例として、PyTorch 公式 Web サイトを参照し (グラフィック カードが 11.8 をサポートしていない場合は、コマンドを変更する必要があります)、インストールする 2 つのうちの 1 つを選択します。
# pip
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# conda
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidiaこれで、必要な環境がすべて正常に構成され、学習を開始する準備が整いました :) 残りの依存関係については、各記事で個別にリストされます。
[!注記]
Docker イメージには依存関係がプリインストールされているため、再インストールする必要はありません。
まず、 jupyter-labをインストールします。これは、 jupyter notebookよりもはるかに使いやすいです。
pip install jupyterlabインストールが完了したら、次のコマンドを実行します。
jupyter-lab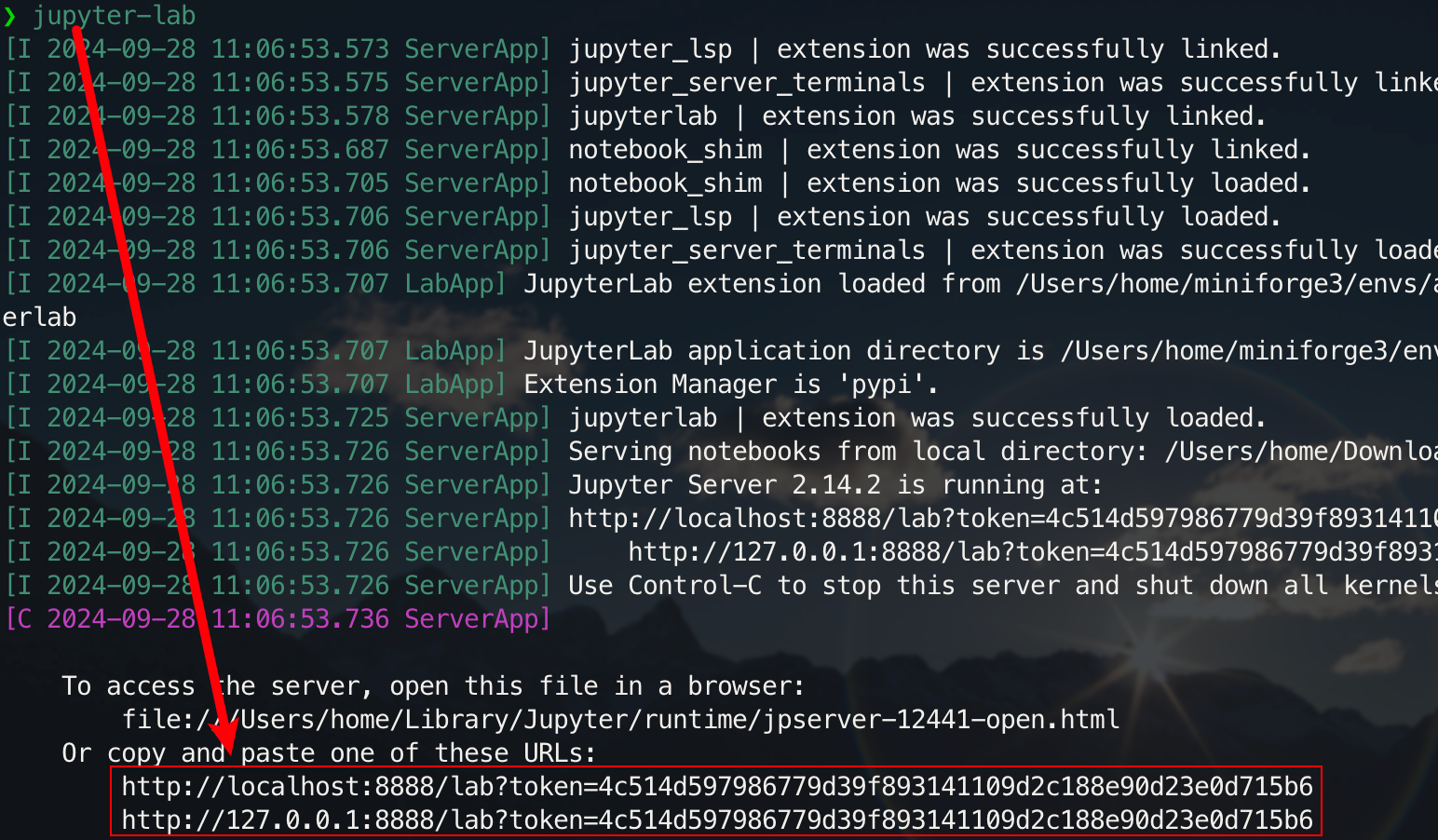
これで、通常はポート 8888 にあるポップアップ リンクを介してアクセスできるようになります。グラフィカル インターフェイスの場合は、Windows/Linux ではCtrlを押し、Mac ではCommandを押したままリンクをクリックして直接ジャンプします。この時点で、プロジェクトの全体像がわかります。
Docker をインストールしていない学生は、「Docker を使用してディープ ラーニング環境をすばやく構成する (Linux)」の記事を読むことができます。初心者は、「Docker の基本コマンドと一般的なエラーの解決方法の紹介」を読むことをお勧めします。
すべてのバージョンにsudo 、 pip 、 conda 、 wget 、 curl 、 vimなどの共通ツールがプリインストールされており、 pipとcondaの国産イメージ ソースが設定されています。同時に、 zshといくつかの実用的なコマンド ライン プラグイン (コマンドの自動補完、構文の強調表示、およびディレクトリ ジャンプ ツールz ) が統合されています。また、 jupyter notebookとjupyter labプリインストールされており、深層学習の開発を容易にするためにデフォルトのターミナルがzshに設定されており、コンテナ内の中国語表示は文字化けを回避するように最適化されています。 Hugging Face の国内ミラー アドレスも事前に設定されています。
pytorch/pytorch:2.5.1-cuda11.8-cudnn9-develに基づいています。デフォルトのpythonバージョンは 3.11.10 です。このバージョンはconda install python==版本号を通じて直接変更できます。適切なインストール:
wget 、 curl : コマンドラインダウンロードツールvim 、 nano : テキストエディタgit : バージョン管理ツールgit-lfs : Git LFS (大容量ファイルストレージ)zip 、 unzip : ファイルの圧縮および解凍ツールhtop : システム監視ツールtmux 、 screen : セッション管理ツールbuild-essential : コンパイル ツール ( gcc 、 g++など)iputils-ping 、 iproute2 、 net-tools : ネットワーク ツール ( ping 、 ip 、 ifconfig 、 netstatなどのコマンドを提供します)ssh : リモート接続ツールrsync : ファイル同期ツールtree : ファイルとディレクトリのツリーを表示します。lsof : システム上で現在開いているファイルを表示しますaria2 : マルチスレッドダウンロードツールlibssl-dev : OpenSSL 開発ライブラリpipのインストール:
jupyter notebook 、 jupyter lab : インタラクティブな開発環境virtualenv : Python 仮想環境管理ツール。conda を直接使用できます。tensorboard : 深層学習トレーニング可視化ツールipywidgets : プログレスバーを正しく表示するための Jupyter ウィジェット ライブラリプラグイン:
zsh-autosuggestions : コマンドの自動補完zsh-syntax-highlighting : 構文の強調表示z : ディレクトリに素早くジャンプしますdl (ディープ ラーニング) バージョンはベースに基づいており、ディープ ラーニングで使用される可能性のある基本的なツールとライブラリを追加でインストールします。
適切なインストール:
ffmpeg : オーディオおよびビデオ処理ツールlibgl1-mesa-glx : グラフィックス ライブラリの依存関係 (深層学習フレームワークのグラフィックス関連の問題を解決します)pipのインストール:
numpy 、 scipy : 数値計算と科学計算pandas : データ分析matplotlib 、 seaborn : データの視覚化scikit-learn : 機械学習ツールtensorflow 、 tensorflow-addons : もう 1 つの人気のある深層学習フレームワークtf-keras : Keras インターフェースの TensorFlow 実装transformers 、 datasets : Hugging Face が提供する NLP ツールnltk 、 spacy : 自然言語処理ツール追加のライブラリが必要な場合は、次のコマンドを使用して手動でインストールできます。
pip install --timeout 120 <替换成库名>ここで--timeout 120 、ネットワークが貧弱な場合でもインストールに十分な時間が確保できるように、タイムアウトを 120 秒に設定します。設定を行わないと、国内環境においてダウンロードタイムアウトによりパッケージのインストールが失敗する場合があります。
すべてのイメージが事前にウェアハウスを取得するわけではないことに注意してください。
Docker をインストールして構成していると仮定すると、現在のプロジェクトの場合、2 行のimage_name:tagのみで、バージョンの説明を確認した後に選択できます。以下に続きます:
hoperj/quickstart:base-torch2.5.1-cuda11.8-cudnn9-develhoperj/quickstart:dl-torch2.5.1-cuda11.8-cudnn9-develプルコマンドは次のとおりです。
docker pull < image_name:tag >以下では、コマンドを実行する方法の 1 つを選択する例としてDLバージョンを使用します。
docker pull dockerpull.org/hoperj/quickstart:dl-torch2.5.1-cuda11.8-cudnn9-develdocker pull hoperj/quickstart:dl-torch2.5.1-cuda11.8-cudnn9-develファイルは、Baidu Cloud Disk を通じてダウンロードできます (Alibaba Cloud Disk は、大きな圧縮ファイルの共有をサポートしていません)。
同じ名前のファイルは同じ内容です
.tar.gz圧縮されたバージョンです。ダウンロード後、次のコマンドで解凍します。gzip -d dl.tar.gz
dl.tarが~/Downloadsにダウンロードされていると仮定して、対応するディレクトリに切り替えます。
cd ~ /Downloads次に、画像をロードします。
docker load -i dl.tarこのモードでは、コンテナはホストのネットワーク構成を直接使用し、すべてのポートはホストのポートと同じであるため、個別にマッピングする必要はありません。特定のポートのみをマッピングする必要がある場合は、
--network host-p port:portに置き換えます。
docker run --gpus all -it --name ai --network host hoperj/quickstart:dl-torch2.5.1-cuda11.8-cudnn9-devel /bin/zshプロキシを使用する必要がある学生の場合は、 -eを追加して環境変数を設定します。次の拡張記事も参照できます。
プロキシの HTTP/HTTPS ポート番号が 7890、SOCKS5 が 7891 であると仮定します。
-e http_proxy=http://127.0.0.1:7890-e https_proxy=http://127.0.0.1:7890-e all_proxy=socks5://127.0.0.1:7891前のコマンドに統合されました。
docker run --gpus all -it
--name ai
--network host
-e http_proxy=http://127.0.0.1:7890
-e https_proxy=http://127.0.0.1:7890
-e all_proxy=socks5://127.0.0.1:7891
hoperj/quickstart:dl-torch2.5.1-cuda11.8-cudnn9-devel
/bin/zsh[!ヒント]
一般的な操作を事前に確認してください。
- コンテナを開始します:
docker start <容器名>- コンテナーを実行します:
docker exec -it <容器名> /bin/zsh
- コンテナ内で終了するには:
Ctrl + Dまたはexit。- コンテナを停止します:
docker stop <容器名>- コンテナを削除します:
docker rm <容器名>
git clone https://github.com/Hoper-J/AI-Guide-and-Demos-zh_CN.git
cd AI-Guide-and-Demos-zh_CNjupyter lab --ip=0.0.0.0 --port=8888 --no-browser --allow-root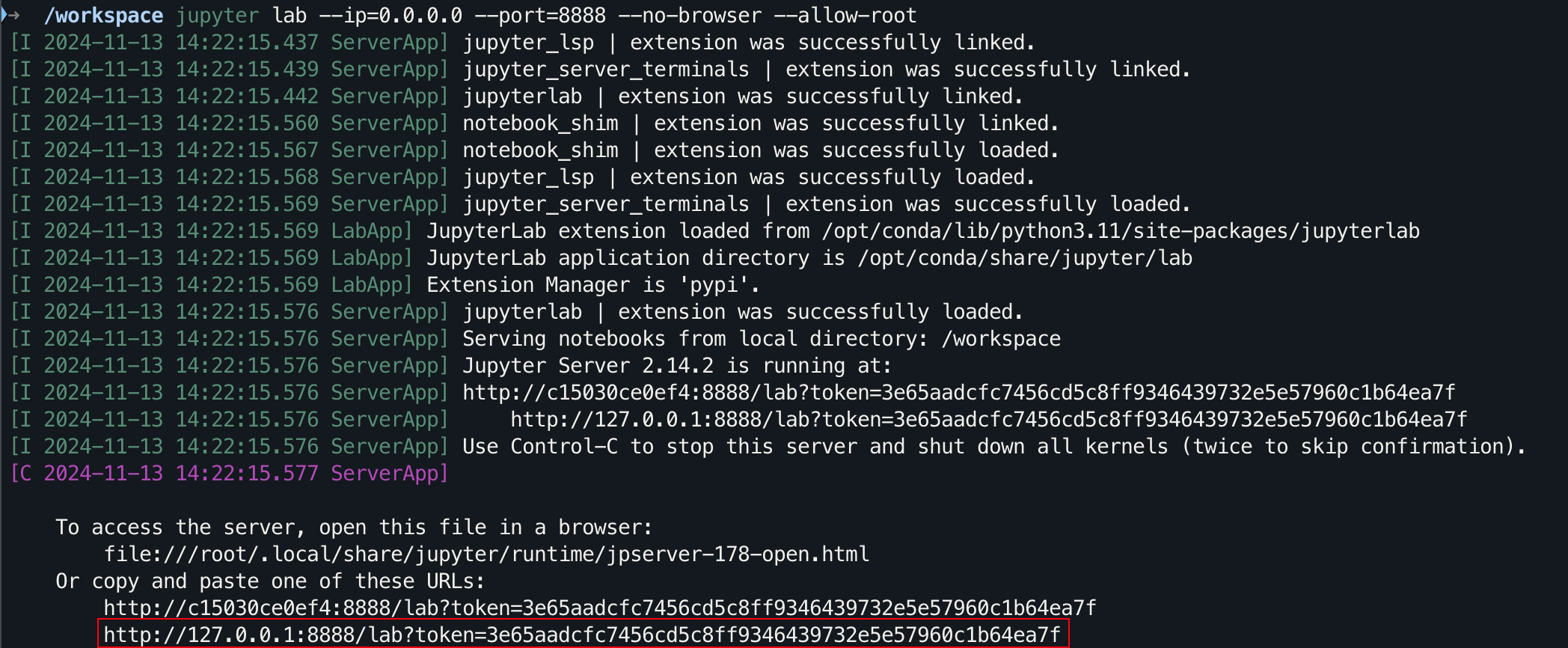
グラフィカル インターフェイスの場合は、Windows/Linux ではCtrlを押し、Mac ではCommandを押したままリンクをクリックして直接ジャンプします。
STAR? をありがとうございます。お役に立てば幸いです。


