ai pizza
1.0.0
それでも、機械が何か新しいものを生み出すことができるのか、それともすでに知っていることに限定されるのかは誰にもわかりません。しかし現在でも、人工知能は複雑な問題を解決したり、非構造化データセットを分析したりできます。私たち Dodo は実験を行うことにしました。混沌とした主観的なもの、つまり味を整理し、構造的に説明すること。私たちは、人工知能を使用して、ほとんどの人がおいしいと感じるであろう、最もワイルドな食材の組み合わせを見つけることにしました。
MIPT および Skoltech の専門家と協力して、ケンブリッジおよびその他の米国のいくつかの大学が実施した 30 万件を超えるレシピと成分の分子の組み合わせに関する研究結果を分析した人工知能を開発しました。これに基づいて、AI は食材間の非自明な関係を見つけ、食材を組み合わせる方法と、それぞれの存在が他のすべての組み合わせにどのような影響を与えるかを理解することを学習しました。
どのモデルでもデータが必要です。 AI をトレーニングするために 300,000 を超える料理レシピを収集したのはそのためです。
難しいのは集めることではなく、同じ形にすることでした。たとえば、レシピでは唐辛子は「chilli」、「chili」、「chiles」、さらには「chillis」と記載されています。これらがすべて「唐辛子」を意味することは明らかですが、ニューラル ネットワークはそれぞれを個別の実体として認識します。
当初は 100,000 を超える一意の材料がありましたが、データをクリーンアップした後は 1,000 の一意の位置のみが残りました。
データセットを取得したら、初期分析を行いました。まず、データセットに存在する料理の数を定量的に評価しました。
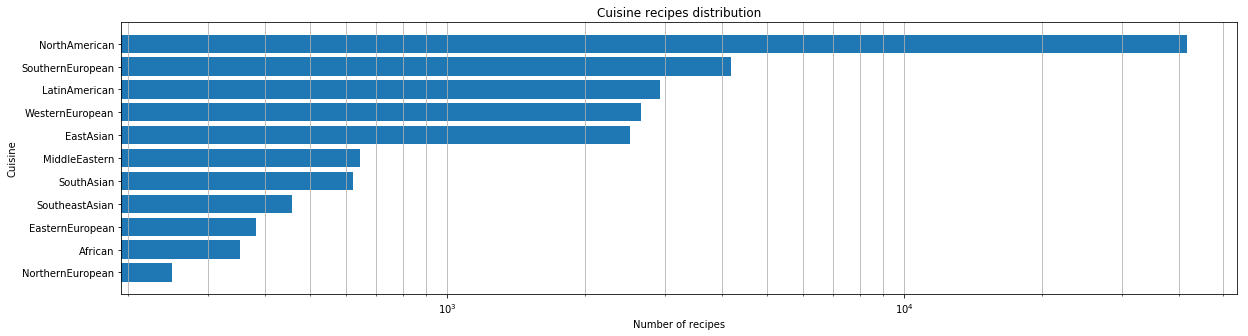
それぞれの料理について、最も人気のある食材を特定しました。
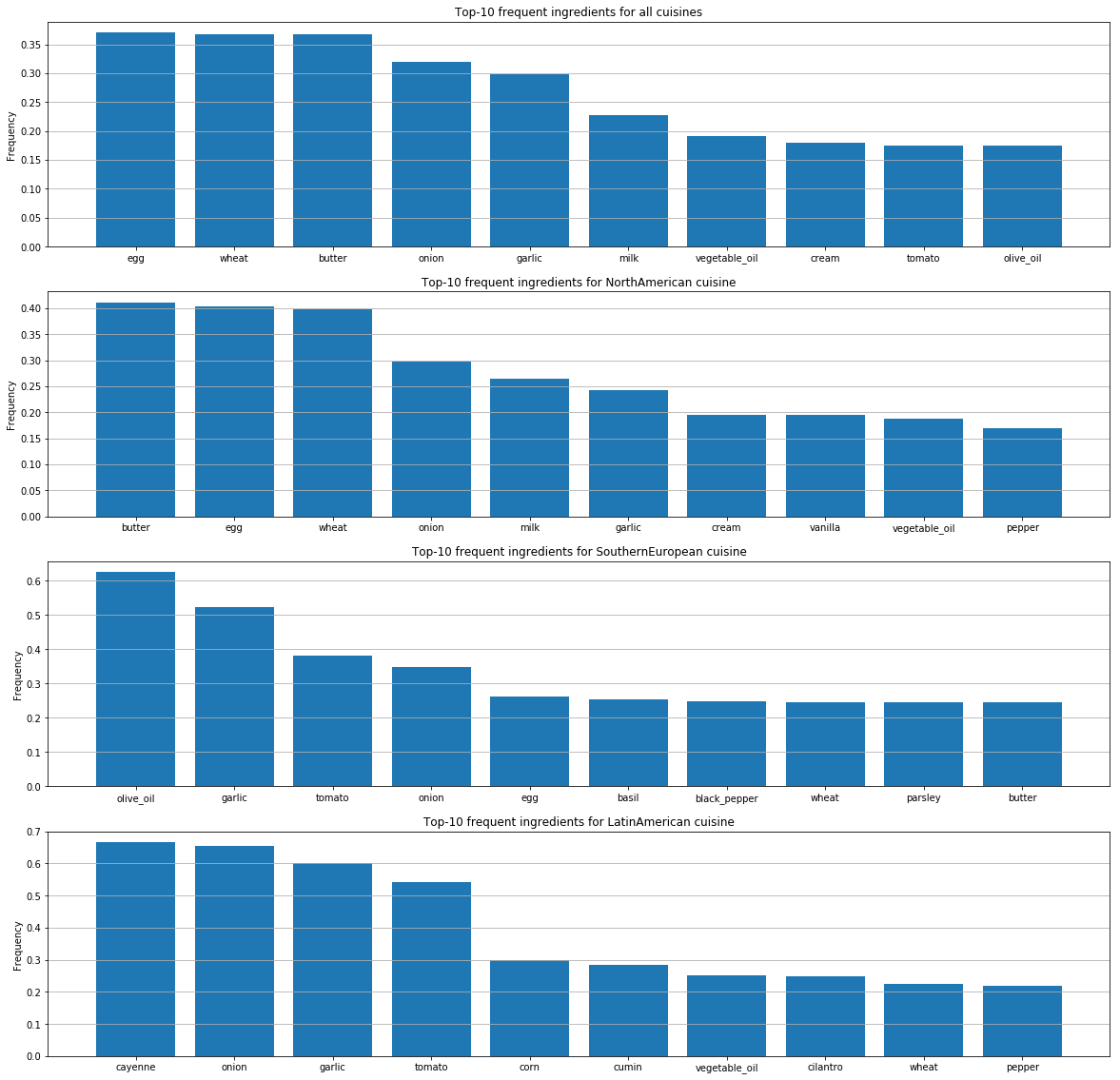
これらのグラフは、国による人々の味の好みの違いや、材料の組み合わせ方の違いを示しています。
その後、世界中のピザのレシピを分析してパターンを発見することにしました。これらが私たちが導き出した結論です。
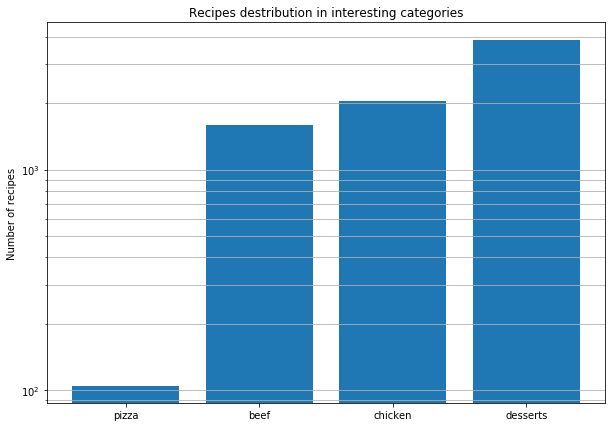
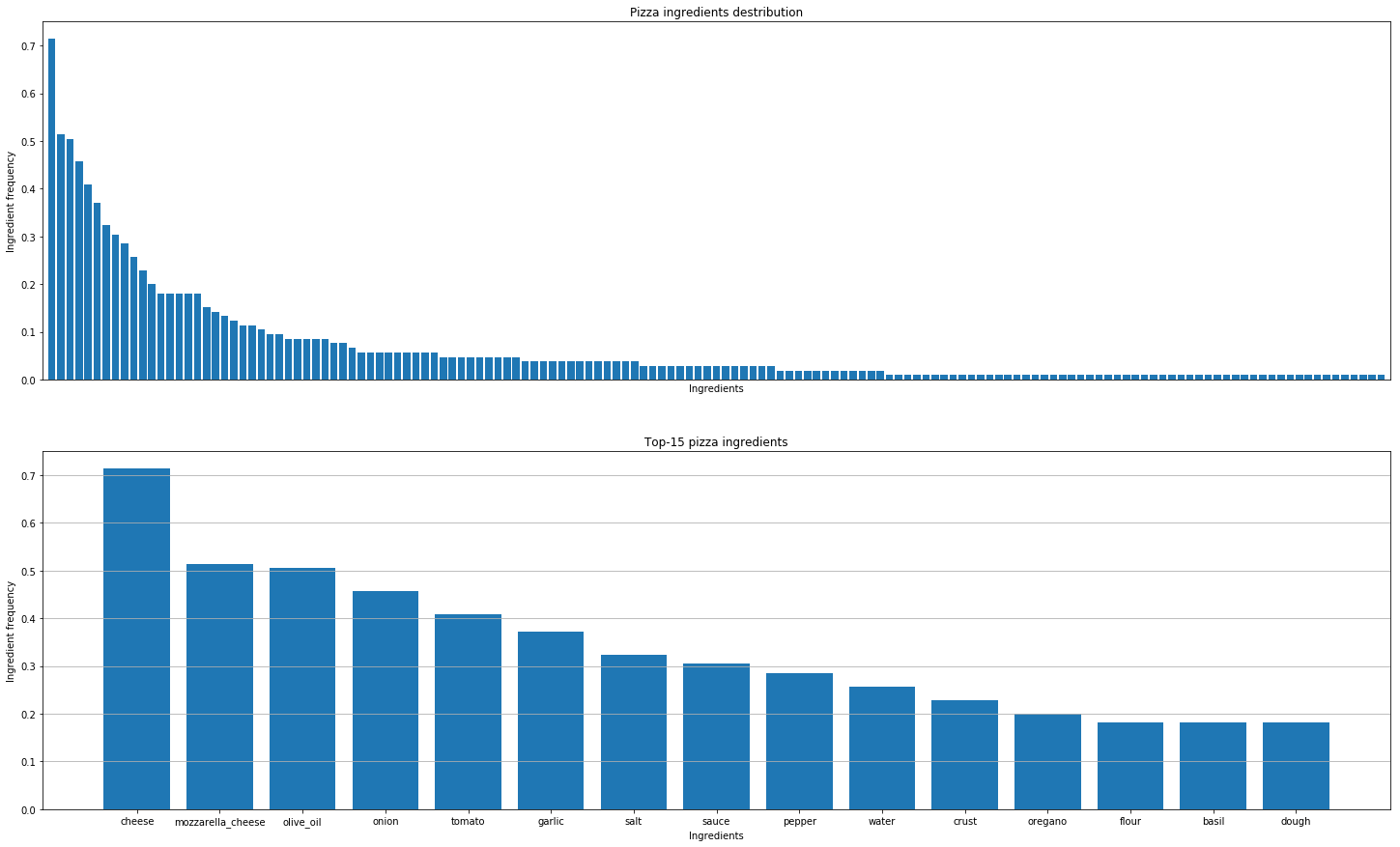
実際の味の組み合わせを見つけることは、分子の組み合わせを理解することと同じではありません。すべてのチーズは同じ分子組成を持っていますが、それは、良い組み合わせが最も近い材料からのみ得られるという意味ではありません。
ただし、成分を数学に変換するときに確認する必要があるのは、分子的に類似した成分の組み合わせです。なぜなら、似たもの(同じチーズ)は、どのように説明しても似たままでなければならないからです。このようにして、オブジェクトが正しく記述されているかどうかを判断できます。
ニューラル ネットワークが理解できる形式でレシピを提示するために、文脈内の単語の出現に基づく word2vec のアルゴリズムであるスキップ グラム ネガティブ サンプリング (SGNS) を使用しました。
レシピの意味構造が単純なテキストとは異なるため、事前トレーニングされた word2vec モデルは使用しないことにしました。そして、これらのモデルでは、重要な情報が失われる可能性があります。
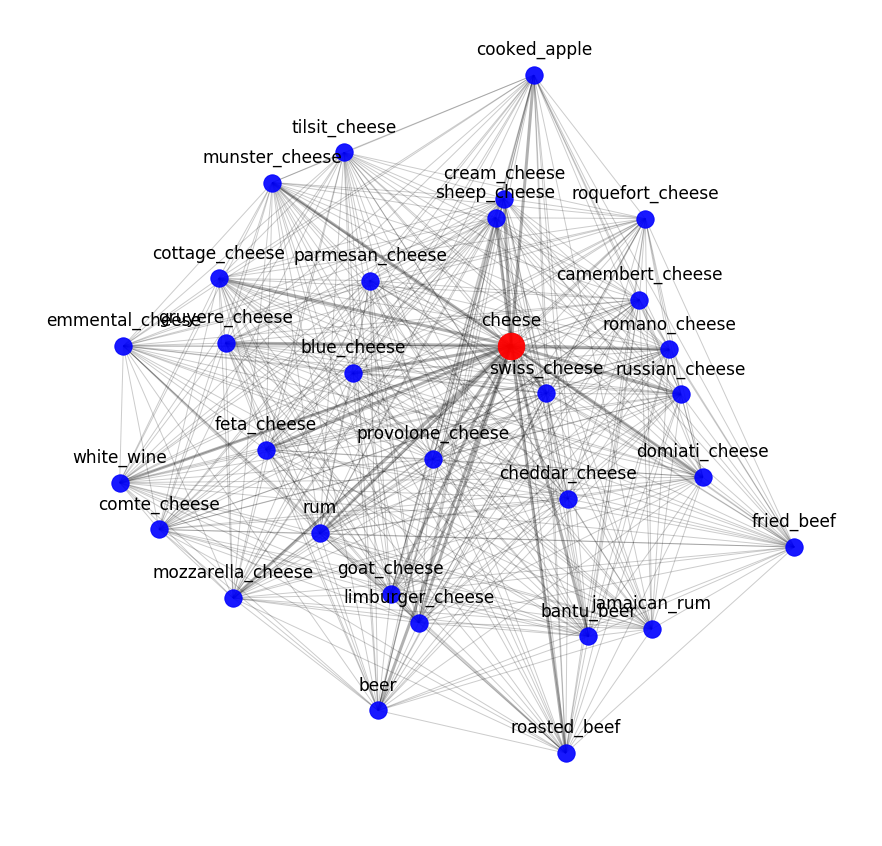
word2vec の結果は、意味上の最近傍を調べることで評価できます。たとえば、モデルがチーズについて知っていることは次のとおりです。
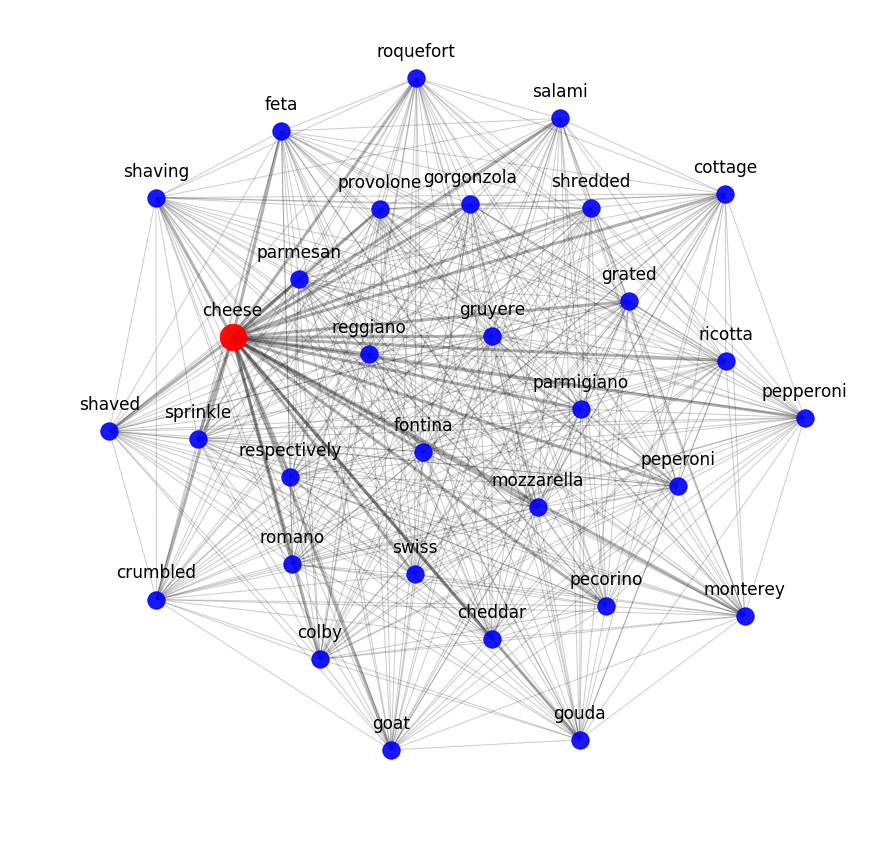
セマンティック モデルがレシピの材料の相互関係をどの程度把握できるかをテストするために、トピック モデルを適用しました。言い換えれば、数学的に決定された規則性に従ってレシピ データセットをクラスターに分割しようとしました。
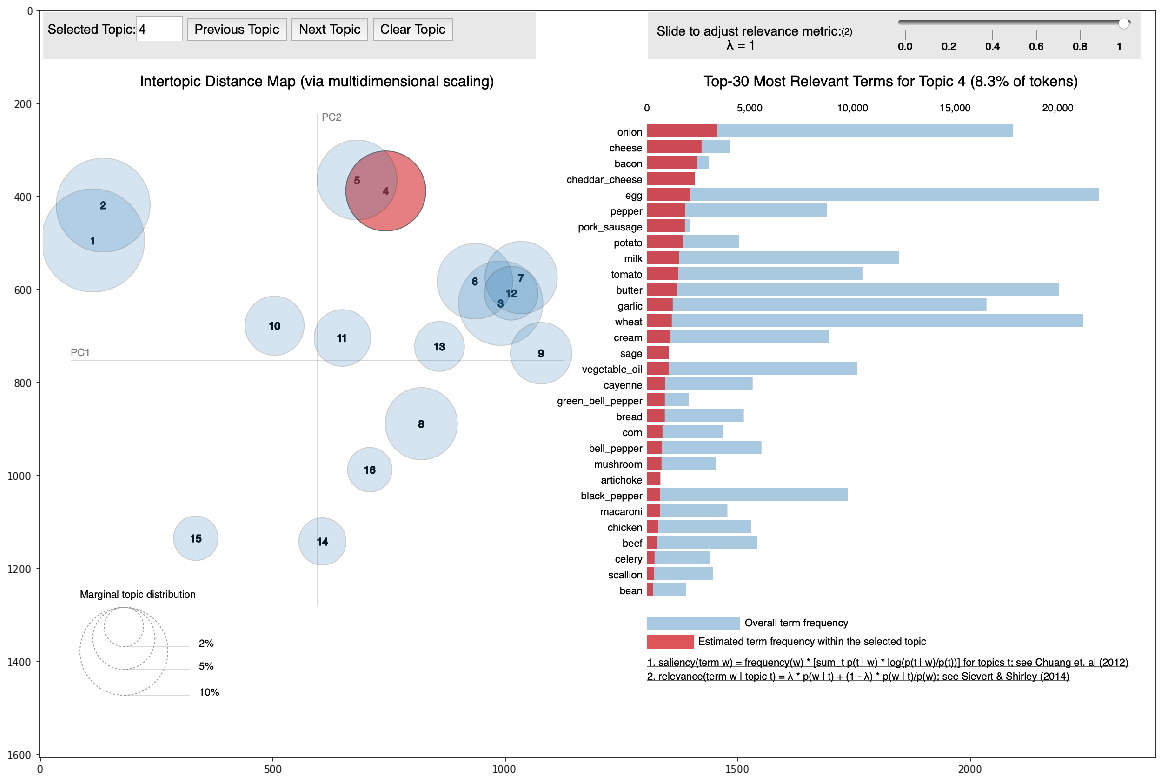
すべてのレシピについて、それらが対応する特定のクラスターがわかっていました。サンプル レシピについては、実際のクラスターとの関係がわかっていました。これに基づいて、これら 2 種類のクラスター間の関連性が見つかりました。
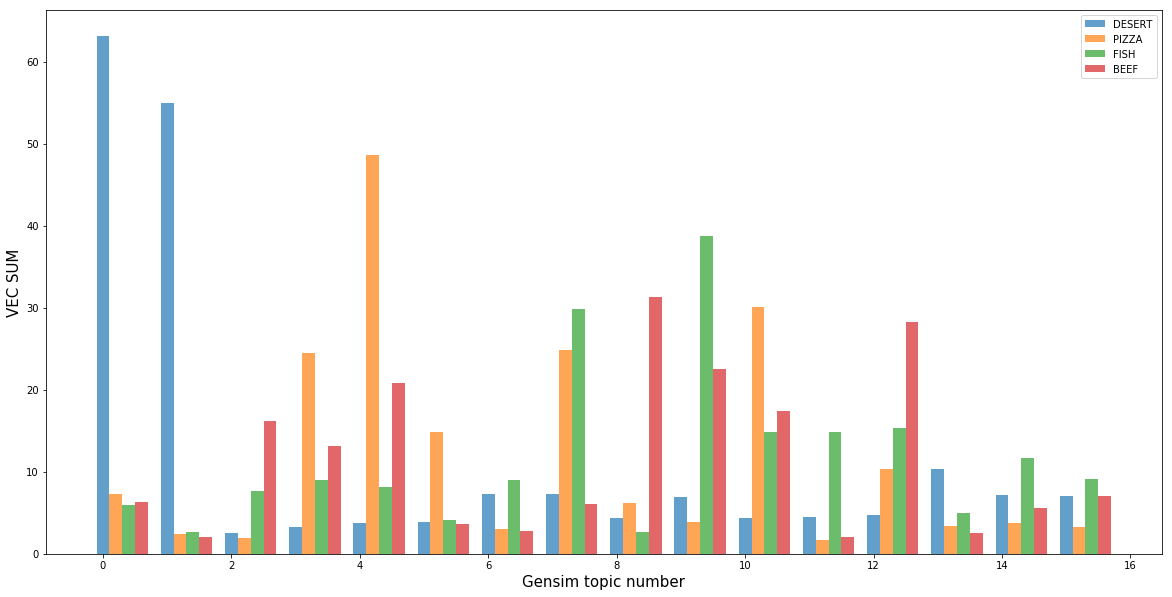
最も明らかなのは、トピック 0 と 1 に含まれるデザートのクラスで、トピック モデルによって生成されました。デザートに加えて、これらのトピックに関する他のクラスはほとんどありません。これは、デザートが他のクラスの料理から簡単に分離されたことを示唆しています。また、各トピックには、それを最もよく説明するクラスがあります。これは、私たちのモデルが「味」の非自明な意味を数学的に定義することに成功したことを意味します。
新しいレシピを作成するために 2 つの反復ニューラル ネットワークを使用しました。この目的のために、レシピ空間全体の中にピザのレシピに対応する部分空間があると仮定しました。そして、ニューラル ネットワークが新しいピザのレシピを作成する方法を学習するには、この部分空間を見つける必要がありました。
このタスクは画像の自動エンコーディングに似ており、画像を低次元ベクトルとして表現します。このようなベクトルには、画像に関する多くの特定の情報が含まれる場合があります。
たとえば、これらのベクトルは、写真内の顔認識のために、人の髪の色に関する情報を別のセルに保存できます。私たちがこのアプローチを選択したのは、まさに隠れた部分空間のユニークな特性のためです。
ピザの部分空間を特定するために、2 つの反復ニューラル ネットワークを通じてピザのレシピを実行しました。最初のものはピザのレシピを受け取り、その表現が潜在ベクトルとして見つかった。 2 番目のニューラル ネットワークは、最初のニューラル ネットワークから潜在ベクトルを受け取り、それに基づいてレシピを作成しました。最初のニューラル ネットワークの入力と 2 番目のニューラル ネットワークの出力のレシピは一致しているはずです。
このようにして、2 つのニューラル ネットワークは潜在ベクトルのレシピを正しく変換する方法を学習しました。そしてこれに基づいて、ピザのレシピ全体に対応する隠れた部分空間を見つけることができました。
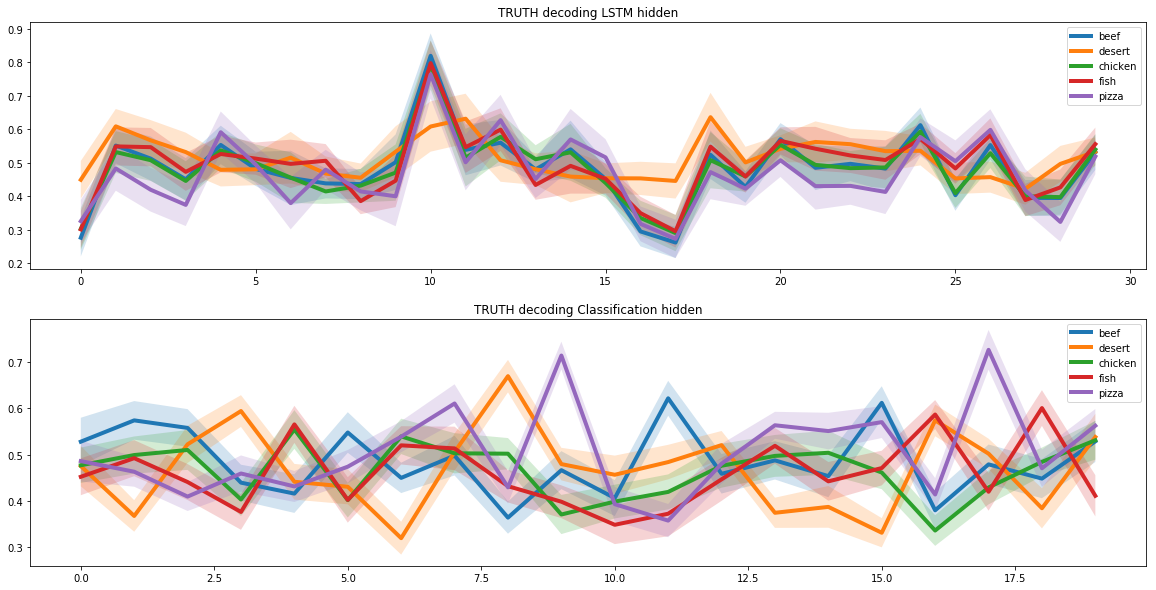
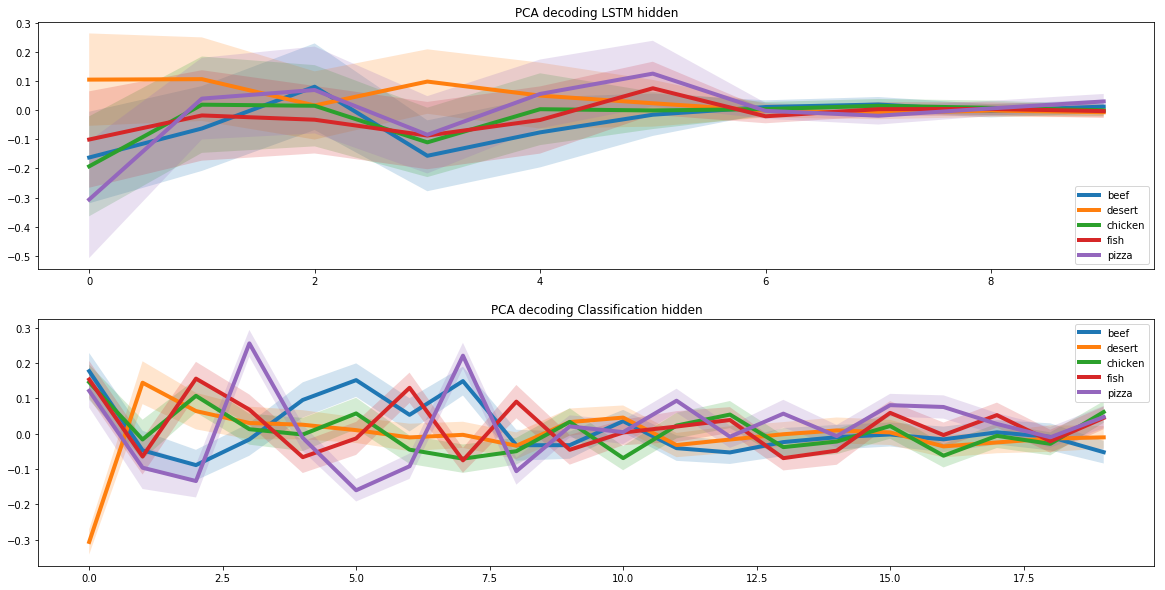
ピザのレシピを作成するという問題を解決するには、分子の組み合わせ基準をモデルに追加する必要がありました。これを行うために、ケンブリッジと米国のいくつかの大学の科学者による共同研究の結果を使用しました。
この研究では、最も一般的な分子ペアを持つ成分が最良の組み合わせを形成することがわかりました。したがって、レシピを作成するとき、ニューラル ネットワークは、類似した分子構造を持つ材料を優先しました。
その結果、私たちのニューラルネットワークはピザのレシピを作成することを学習しました。係数を調整することで、ニューラル ネットワークはマルガリータやペパロニなどの古典的なレシピと、その 1 つがオープンソース ピザの核心である珍しいレシピの両方を生成できます。
| いいえ | レシピ |
|---|---|
| 1 | ほうれん草、チーズ、トマト、ブラックオリーブ、オリーブ、ニンニク、コショウ、バジル、柑橘類、メロン、スプラウト、バターミルク、レモン、ベース、ナッツ、ルタバガ |
| 2 | 玉ねぎ、トマト、オリーブ、黒胡椒、パン、生地 |
| 3 | チキン、玉ねぎ、ブラックオリーブ、チーズ、ソース、トマト、オリーブオイル、モッツァレラチーズ |
| 4 | トマト、バター、クリームチーズ、コショウ、オリーブオイル、チーズ、黒胡椒、モッツァレラチーズ |
オープンソース ピザは MIT ライセンスに基づいてライセンスされています。
ゴロジャエフ・アルセニー、MIPT、スコルテック、[email protected]
エゴール・バリシニコフ、スコルテック、[email protected]


