CQN
1.0.0
Coarse-to-fine Q-Network (CQN)の再実装は、連続制御のためのサンプル効率の高い値ベースの RL アルゴリズムであり、以下で導入されています。
粗いから細かいへの強化学習による継続的制御
ソ・ヨンギョ、ジャファル・ウルチ、スティーブン・ジェームス
私たちの重要なアイデアは、粗い方法から細かい方法まで連続アクション空間にズームインする RL エージェントを学習し、各レベルでいくつかの離散アクションによる連続制御のために値ベースの RL エージェントをトレーニングできるようにすることです。
詳細については、プロジェクトのウェブページ https://youngggy.me/cqn/ をご覧ください。
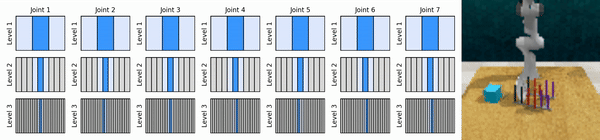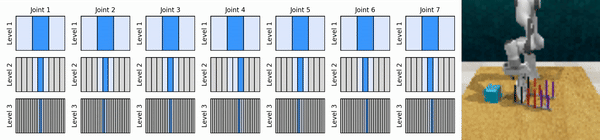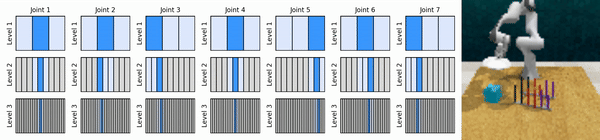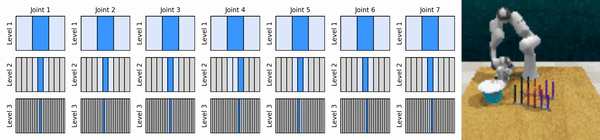
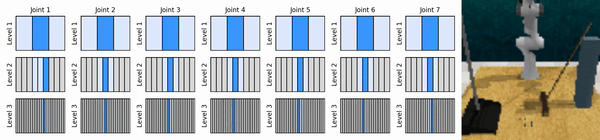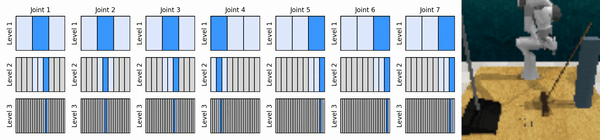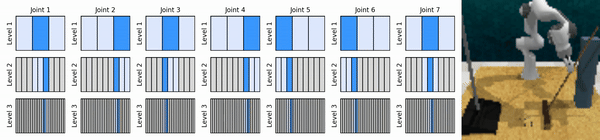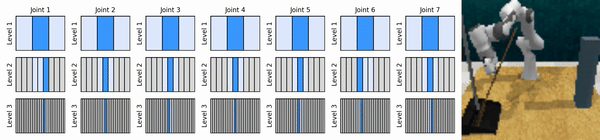
conda 環境をインストールします。
conda env create -f conda_env.yml
conda activate cqn
RLBench と PyRep をインストールします (2024 年 7 月 10 日時点の最新バージョンを使用する必要があります)。 (1) RLBench と PyRep のインストール、(2) ヘッドレス モードの有効化については、元のリポジトリのガイドに従ってください。 (RLBench のインストールについては、RLBench と Robobase の README を参照してください。)
git clone https://github.com/stepjam/RLBench
git clone https://github.com/stepjam/PyRep
# Install PyRep
cd PyRep
git checkout 8f420be8064b1970aae18a9cfbc978dfb15747ef
pip install .
# Install RLBench
cd RLBench
git checkout b80e51feb3694d9959cb8c0408cd385001b01382
pip install .
事前収集デモンストレーション
cd RLBench/rlbench
CUDA_VISIBLE_DEVICES=0 DISPLAY=:0.0 python dataset_generator.py --save_path=/your/own/directory --image_size 84 84 --renderer opengl3 --episodes_per_task 100 --variations 1 --processes 1 --tasks take_lid_off_saucepan --arm_max_velocity 2.0 --arm_max_acceleration 8.0
実験の実行 (CQN):
CUDA_VISIBLE_DEVICES=0 DISPLAY=:0.0 python train_rlbench.py rlbench_task=take_lid_off_saucepan num_demos=100 dataset_root=/your/own/directory
ベースライン実験を実行します (DrQv2+):
CUDA_VISIBLE_DEVICES=0 DISPLAY=:0.0 python train_rlbench_drqv2plus.py rlbench_task=take_lid_off_saucepan num_demos=100 dataset_root=/your/own/directory
実験を実行します。
CUDA_VISIBLE_DEVICES=0 python train_dmc.py dmc_task=cartpole_swingup
警告: CQN は DMC では広範にテストされていません
このリポジトリは DrQ-v2 の公開実装に基づいています
@article{seo2024continuous,
title={Continuous Control with Coarse-to-fine Reinforcement Learning},
author={Seo, Younggyo and Uru{c{c}}, Jafar and James, Stephen},
journal={arXiv preprint arXiv:2407.07787},
year={2024}
}


