gpt neox
GPT-NeoX 2.0
このリポジトリには、GPU 上で大規模な言語モデルをトレーニングするための EleutherAI のライブラリが記録されています。現在のフレームワークは NVIDIA の Megatron 言語モデルに基づいており、DeepSpeed の技術といくつかの新しい最適化によって強化されています。私たちは、このリポジトリを、大規模な自己回帰言語モデルをトレーニングするためのテクニックを収集し、大規模なトレーニングに関する研究を加速するための一元化されたアクセス可能な場所にすることを目指しています。このライブラリは、オークリッジ国立研究所、CarperAI、Stability AI、Togetter.ai、高麗大学、カーネギー メロン大学、東京大学などの研究者を含め、学術、業界、政府の研究機関で広く使用されています。同様のライブラリの中でも独特の GPT-NeoX は、Slurm、MPI、IBM Job Step Manager 経由の起動など、さまざまなシステムとハードウェアをサポートしており、AWS、CoreWeave、ORNL Summit、ORNL Frontier、LUMI、およびその他。
数十億のパラメーターを使用してモデルを最初からトレーニングするつもりがない場合、これは使用するには間違ったライブラリである可能性があります。一般的な推論のニーズについては、代わりに GPT-NeoX モデルをサポートする Hugging Face transformersライブラリを使用することをお勧めします。
GPT-NeoX は、人気のある Megatron-DeepSpeed ライブラリと同じ機能とテクノロジーの多くを活用していますが、大幅に向上した使いやすさと新しい最適化が施されています。主な機能は次のとおりです。
[2024/9/9] DPO、KTO、報酬モデリングによる好みの学習をサポートするようになりました。
[2024/9/9]機械学習モニタリング プラットフォームである Comet ML との統合をサポートするようになりました
[2024/5/21]パイプライン並列処理で RWKV をサポートするようになりました。 RWKV および RWKV+パイプラインの PR を参照してください。
[2024/3/21]専門家混合 (MoE) をサポートするようになりました
[2024/3/17] AMD MI250X GPU をサポートするようになりました
[2024/3/15]テンソル並列処理で Mamba をサポートしました。 PRを見る
[2023/8/10] AWS S3 でのチェックポイント設定をサポートしました。 s3_path構成オプションを使用してアクティブ化します (詳細については、PR を参照してください)
[2023/9/20] #1035 の時点で、Flash アテンション 0.x および 1.x を非推奨にし、サポートを Flash アテンション 2.x に移行しました。これによって問題が発生するとは思われませんが、最新の GPT-NeoX を使用した古いフラッシュのサポートが必要な特定のユースケースがある場合は、問題を提起してください。
[2023/8/10]今月後半にアップストリームされる math-lm プロジェクトでサポートされる LLaMA 2 と Flash Attend v2 の実験的サポートがあります。
[2023/5/17]いくつかのその他のバグを修正した後、bf16 を完全にサポートするようになりました。
[2023/4/11] Flash アテンションの実装をアップグレードして、Alibi の位置埋め込みをサポートするようになりました。
[2023/3/9]最新の DeepSpeed に基づいて構築されたアップグレード バージョンである GPT-NeoX 2.0.0 をリリースしました。今後も定期的に同期されます。
2023 年 3 月 9 日より前は、GPT-NeoX は古いバージョンの DeepSpeed (0.3.15) をベースとした DeeperSpeed に依存していました。ユーザーが GPT-NeoX と DeeperSpeed の古いバージョンにアクセスできるようにしながら、最新のアップストリーム DeepSpeed バージョンに移行するために、両方のライブラリに 2 つのバージョンのリリースを導入しました。
このコードベースは主に Python 3.8 ~ 3.10 および PyTorch 1.8 ~ 2.0 向けに開発およびテストされています。これは厳密な要件ではなく、他のバージョンやライブラリの組み合わせも機能する可能性があります。
残りの基本的な依存関係をインストールするには、次を実行します。
pip install -r requirements/requirements.txt
pip install -r requirements/requirements-wandb.txt # optional, if logging using WandB
pip install -r requirements/requirements-tensorboard.txt # optional, if logging via tensorboard
pip install -r requirements/requirements-comet.txt # optional, if logging via Cometリポジトリのルートから。
警告
私たちのコードベースは、いくつかの変更を加えた DeepSpeed ライブラリのフォークである DeeperSpeed に依存しています。続行する前に、Anaconda、仮想マシン、またはその他の形式の環境分離を使用することを強くお勧めします。そうしないと、DeepSpeed に依存する他のリポジトリが破損する可能性があります。
JIT 融合カーネル コンパイルを通じて AMD GPU (MI100、MI250X) をサポートするようになりました。必要に応じて、融合されたカーネルが構築され、ロードされます。ジョブの起動中の待機を避けるために、手動プリビルドで次のことを実行することもできます。
python
from megatron . fused_kernels import load
load ()これにより、プラットフォーム固有のコードを変更することなく、さまざまな GPU ベンダー (AMD、NVIDIA) のビルド プロセスが自動的に適応されます。 pytestを使用して融合カーネルをさらにテストするには、 pytest tests/model/test_fused_kernels.pyを使用します。
Flash-Attention を使用するには、 ./requirements/requirements-flashattention.txt -flashattention.txt に追加の依存関係をインストールし、それに応じて構成内のアテンション タイプを設定します (構成を参照)。これにより、Ampere GPU (A100 など) を含む特定の GPU アーキテクチャで通常の処理よりも大幅な高速化が実現できます。詳細については、リポジトリを参照してください。
NeoX と Deep(er)Speed は、複数の異なるノードでのトレーニングをサポートしており、さまざまなランチャーを使用してマルチノード ジョブを調整するオプションがあります。
一般に、次の形式でアクセス可能な場所に「ホストファイル」が必要です。
node1_ip slots=8
node2_ip slots=8ここで、最初の列にはセットアップ内の各ノードの IP アドレスが含まれ、スロットの数はノードがアクセスできる GPU の数です。構成では、 "hostfile": "/path/to/hostfile"を使用してホストファイルへのパスを渡す必要があります。あるいは、ホストファイルへのパスを環境変数DLTS_HOSTFILEに指定することもできます。
pdshはデフォルトのランチャーであり、 pdsh使用している場合は、(pdsh が環境にインストールされていることを確認する以外に) 設定ファイルで{"launcher": "pdsh"}を設定するだけです。
MPI を使用する場合は、MPI ライブラリ (DeepSpeed/GPT-NeoX は現在mvapich 、 openmpi 、 mpich 、 impiサポートしていますが、 openmpiが最も一般的に使用され、テストされています) を指定し、構成ファイルでdeepspeed_mpiフラグを渡す必要があります。
{
"launcher" : " openmpi " ,
"deepspeed_mpi" : true
}環境が適切にセットアップされ、正しい構成ファイルがあれば、通常の Python スクリプトのようにdeepy.py使用して、(たとえば) 次のコマンドでトレーニング ジョブを開始できます。
python3 deepy.py train.py /path/to/configs/my_model.yml
Slurm を使用する場合は、もう少し複雑な場合があります。 MPI と同様に、次の内容を構成に追加する必要があります。
{
"launcher" : " slurm " ,
"deepspeed_slurm" : true
} Slurm クラスター内の計算ノードに ssh アクセスできない場合は{"no_ssh_check": true}を追加する必要があります。
上記のデフォルトの起動オプションでは不十分な場合が多くあります。
このような場合、ユースケースをサポートするために DeepSpeed マルチノード ランナー ユーティリティを変更する必要があります。これらの機能強化は、大まかに次の 2 つのカテゴリに分類されます。
この場合、新しいマルチノード ランナー クラスをdeepspeed/launcher/multinode_runner.pyに追加し、GPT-NeoX の構成オプションとして公開する必要があります。 Summit JSRun でこれをどのように行ったかの例は、それぞれこの DeeperSpeed コミットとこの GPT-NeoX コミットにあります。
最適化やデバッグのために MPI/Slurm 実行コマンドを変更したいケースが数多くあります (たとえば、Slurm srun CPU バインディングを変更したり、MPI ログにランクをタグ付けしたりするなど)。この場合、マルチノード ランナー クラスのget_cmdメソッドで実行コマンドを変更する必要があります (OpenMPI の場合は mpirun_cmd など)。安定性クラスターに Slurm と OpenMPI を使用して、最適化されランクタグ付きの実行コマンドを提供するためにこれを行った方法の例は、この DeeperSpeed ブランチにあります。
一般に、単一の固定ホストファイルを持つことはできないため、ジョブの開始時にホストファイルを動的に生成するスクリプトが必要です。 Slurm とノードごとに 8 つの GPU を使用してホストファイルを動的に生成するスクリプトの例は次のとおりです。
#! /bin/bash
GPUS_PER_NODE=8
mkdir -p /sample/path/to/hostfiles
# need to add the current slurm jobid to hostfile name so that we don't add to previous hostfile
hostfile=/sample/path/to/hostfiles/hosts_ $SLURM_JOBID
# be extra sure we aren't appending to a previous hostfile
rm $hostfile & > /dev/null
# loop over the node names
for i in ` scontrol show hostnames $SLURM_NODELIST `
do
# add a line to the hostfile
echo $i slots= $GPUS_PER_NODE >> $hostfile
done $SLURM_JOBIDと$SLURM_NODELIST Slurm が作成する環境変数です。ジョブ作成時に設定される利用可能な Slurm 環境変数の完全なリストについては、sbatch のドキュメントを参照してください。
次に、GPT-NeoX ジョブを開始するための sbatch スクリプトを作成できます。ノードごとに 8 つの GPU を備えた Slurm ベースのクラスター上の最低限の sbatch スクリプトは次のようになります。
#! /bin/bash
# SBATCH --job-name="neox"
# SBATCH --partition=your-partition
# SBATCH --nodes=1
# SBATCH --ntasks-per-node=8
# SBATCH --gres=gpu:8
# Some potentially useful distributed environment variables
export HOSTNAMES= ` scontrol show hostnames " $SLURM_JOB_NODELIST " `
export MASTER_ADDR= $( scontrol show hostnames " $SLURM_JOB_NODELIST " | head -n 1 )
export MASTER_PORT=12802
export COUNT_NODE= ` scontrol show hostnames " $SLURM_JOB_NODELIST " | wc -l `
# Your hostfile creation script from above
./write_hostfile.sh
# Tell DeepSpeed where to find our generated hostfile via DLTS_HOSTFILE
export DLTS_HOSTFILE=/sample/path/to/hostfiles/hosts_ $SLURM_JOBID
# Launch training
python3 deepy.py train.py /sample/path/to/your/configs/my_model.yml
その後、 sbatch my_sbatch_script.shを使用してトレーニングの実行を開始できます。
NeoX をコンテナーで実行したい場合は、Dockerfile および docker-compose 構成も提供します。
コンテナーを実行するための要件は、適切な GPU ドライバー、Docker の最新のインストール、および nvidia-container-toolkit のインストールです。インストールが適切かどうかをテストするには、次の「サンプル ワークロード」を使用できます。
docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi
これが実行される場合は、環境内の NEOX_DATA_PATH と NEOX_CHECKPOINT_PATH をエクスポートして、データ ディレクトリとチェックポイントの保存とロード用のディレクトリを指定する必要があります。
export NEOX_DATA_PATH=/mnt/sda/data/enwiki8 #or wherever your data is stored on your system
export NEOX_CHECKPOINT_PATH=/mnt/sda/checkpoints
そして、gpt-neox ディレクトリからイメージをビルドし、コンテナ内でシェルを実行できます。
docker compose run gpt-neox bash
ビルド後は、次のことができるようになります。
mchorse@537851ed67de:~$ echo $(pwd)
/home/mchorse
mchorse@537851ed67de:~$ ls -al
total 48
drwxr-xr-x 1 mchorse mchorse 4096 Jan 8 05:33 .
drwxr-xr-x 1 root root 4096 Jan 8 04:09 ..
-rw-r--r-- 1 mchorse mchorse 220 Feb 25 2020 .bash_logout
-rw-r--r-- 1 mchorse mchorse 3972 Jan 8 04:09 .bashrc
drwxr-xr-x 4 mchorse mchorse 4096 Jan 8 05:35 .cache
drwx------ 3 mchorse mchorse 4096 Jan 8 05:33 .nv
-rw-r--r-- 1 mchorse mchorse 807 Feb 25 2020 .profile
drwxr-xr-x 2 root root 4096 Jan 8 04:09 .ssh
drwxrwxr-x 8 mchorse mchorse 4096 Jan 8 05:35 chk
drwxrwxrwx 6 root root 4096 Jan 7 17:02 data
drwxr-xr-x 11 mchorse mchorse 4096 Jan 8 03:52 gpt-neox
長時間実行されるジョブの場合は、次のように実行する必要があります。
docker compose up -d
コンテナをデタッチモードで実行し、別のターミナルセッションで次を実行します。
docker compose exec gpt-neox bash
その後、コンテナ内から必要なジョブを実行できます。
長時間または分離モードで実行する場合の懸念事項には、次のようなものがあります。
dockerhub から事前に構築されたコンテナー イメージを実行したい場合は、代わりに-f docker-compose-dockerhub.ymlを使用して docker compose コマンドを実行できます。
docker compose run -f docker-compose-dockerhub.yml gpt-neox bash
すべての機能は、 deepspeedランチャーのラッパーであるdeepy.pyを使用して起動する必要があります。
現在、次の 3 つの主要な機能を提供しています。
train.pyはモデルのトレーニングと微調整に使用されます。eval.pyは、言語モデル評価ハーネスを使用してトレーニングされたモデルを評価するために使用されます。generate.pyは、トレーニングされたモデルからテキストをサンプリングするために使用されます。これは次のコマンドで起動できます。
./deepy.py [script.py] [./path/to/config_1.yml] [./path/to/config_2.yml] ... [./path/to/config_n.yml]たとえば、トレーニングを開始するには、次のコマンドを実行できます。
./deepy.py train.py ./configs/20B.yml ./configs/local_cluster.yml各エントリ ポイントの詳細については、「トレーニングと微調整」、「推論と評価」をそれぞれ参照してください。
GPT-NeoX パラメーターは、deepy.py ランチャーに渡される YAML 構成ファイルで定義されます。構成には、さまざまな機能とモデル サイズを示すサンプル .yml ファイルがいくつか用意されています。
これらのファイルは通常は完全ですが、最適ではありません。たとえば、特定の GPU 構成に応じて、並列化の度合いを増減するためのpipe-parallel-size 、 model-parallel-size 、バッチ サイズを変更するためのtrain_micro_batch_size_per_gpuまたはgradient-accumulation-stepsなどの一部の設定を変更する必要がある場合があります。関連設定、またはオプティマイザーの状態がワーカー間で並列化される方法を変更するzero_optimization dict。
利用可能な機能とその構成方法の詳細なガイドについては、構成 README を参照してください。考えられるすべての引数のドキュメントについては、configs/neox_arguments.md を参照してください。
GPT-NeoX には、MoE 用の複数のエキスパート実装が含まれています。これらを選択するには、 megablocksのmoe_type (デフォルト) またはdeepspeedを指定します。
どちらも、テンソル エキスパート データ並列処理をサポートする DeepSpeed MoE 並列処理フレームワークに基づいています。どちらも、トークンドロップとドロップレスを切り替えることができます (デフォルトであり、これが Megablocks の設計目的です)。シンクホーンルーティングも近日公開予定!
基本的な完全な構成の例については、configs/125M-dmoe.yml (メガブロック ドロップレスの場合) または configs/125M-moe.yml を参照してください。
MoE 関連の設定引数のほとんどには、接頭辞moeが付いています。いくつかの一般的な構成パラメータとそのデフォルトは次のとおりです。
moe_type: megablocks
moe_num_experts: 1 # 1 disables MoE. 8 is a reasonable value.
moe_loss_coeff: 0.1
expert_interval: 2 # See details below
enable_expert_tensor_parallelism: false # See details below
moe_expert_parallel_size: 1 # See details below
moe_token_dropping: false
DeepSpeed は、次のようにさらに構成できます。
moe_top_k: 1
moe_min_capacity: 4
moe_train_capacity_factor: 1.0 # Setting to 1.0
moe_eval_capacity_factor: 1.0 # Setting to 1.0
最初のものも含め、 expert_intervalトランスフォーマ レイヤごとに 1 つの MoE レイヤが存在するため、合計 12 レイヤになります。
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11
専門家は次の層に属します。
0, 2, 4, 6, 8, 10
デフォルトでは、エキスパート データ並列処理を使用するため、利用可能なテンソル並列処理 ( model_parallel_size ) がエキスパート ルーティングに使用されます。たとえば、次のような場合です。
expert_parallel_size: 4
model_parallel_size: 2 # aka tensor parallelism
32 GPU の場合、動作は次のようになります。
expert_parallel_size == model_parallel_sizeであることを確認してください。 enable_expert_tensor_parallelismを設定すると、tensor-expert-data (TED) 並列処理が有効になります。上記を解釈する方法は次のようになります。
expert_parallel_size == 1またはmodel_parallel_size == 1を確保してください。したがって、DP は (MP * EP) で割り切れる必要があることに注意してください。詳細については、TED の論文を参照してください。
パイプライン並列処理はまだサポートされていません。近日中にサポートされる予定です。
Pile のほとんどのコンポーネントや Pile トレイン セット自体を含む、事前構成されたデータセットがいくつか用意されており、 prepare_data.pyエントリ ポイントを使用した簡単なトークン化が可能です。
たとえば、GPT2 Tokenizer を使用して enwik8 データセットをダウンロードしてトークン化し、 ./dataに保存するには、次のように実行します。
python prepare_data.py -d ./data
または、GPT-NeoX-20B トークナイザーを含むパイルの単一シャード ( pile_subset ) ( ./20B_checkpoints/20B_tokenizer.jsonに保存していると仮定します):
python prepare_data.py -d ./data -t HFTokenizer --vocab-file ./20B_checkpoints/20B_tokenizer.json pile_subset
トークン化されたデータは 2 つのファイルに保存されます: [data-dir]/[dataset-name]/[dataset-name]_text_document.binおよび[data-dir]/[dataset-name]/[dataset-name]_text_document.idx 。これらの両方のファイルが共有するプレフィックスを、 data-pathフィールドの下のトレーニング構成ファイルに追加する必要があります。例えば:
" data-path " : " ./data/enwik8/enwik8_text_document " , カスタム データを使用したトレーニング用に独自のデータセットを準備するには、辞書のリスト内の各項目が別個のドキュメントとなる 1 つの大きな jsonl 形式のファイルとしてデータセットをフォーマットします。ドキュメントのテキストは、1 つの JSON キー、つまり"text"の下にグループ化する必要があります。他のフィールドに格納されている補助データは使用されません。
次に、必ず GPT2 トークナイザー語彙をダウンロードし、次のリンクからファイルをマージしてください。
または、20B トークナイザーを使用します (必要な Vocab ファイルは 1 つだけです)。
(あるいは、 Tokenizer.from_pretrained()コマンドを使用して、Hugging Face のトークナイザー ライブラリによってロードできるトークナイザー ファイルを提供することもできます)
tools/datasets/preprocess_data.pyを使用してデータを事前トークン化できるようになりました。その引数については以下で詳しく説明します。
usage: preprocess_data.py [-h] --input INPUT [--jsonl-keys JSONL_KEYS [JSONL_KEYS ...]] [--num-docs NUM_DOCS] --tokenizer-type {HFGPT2Tokenizer,HFTokenizer,GPT2BPETokenizer,CharLevelTokenizer} [--vocab-file VOCAB_FILE] [--merge-file MERGE_FILE] [--append-eod] [--ftfy] --output-prefix OUTPUT_PREFIX
[--dataset-impl {lazy,cached,mmap}] [--workers WORKERS] [--log-interval LOG_INTERVAL]
optional arguments:
-h, --help show this help message and exit
input data:
--input INPUT Path to input jsonl files or lmd archive(s) - if using multiple archives, put them in a comma separated list
--jsonl-keys JSONL_KEYS [JSONL_KEYS ...]
space separate listed of keys to extract from jsonl. Default: text
--num-docs NUM_DOCS Optional: Number of documents in the input data (if known) for an accurate progress bar.
tokenizer:
--tokenizer-type {HFGPT2Tokenizer,HFTokenizer,GPT2BPETokenizer,CharLevelTokenizer}
What type of tokenizer to use.
--vocab-file VOCAB_FILE
Path to the vocab file
--merge-file MERGE_FILE
Path to the BPE merge file (if necessary).
--append-eod Append an <eod> token to the end of a document.
--ftfy Use ftfy to clean text
output data:
--output-prefix OUTPUT_PREFIX
Path to binary output file without suffix
--dataset-impl {lazy,cached,mmap}
Dataset implementation to use. Default: mmap
runtime:
--workers WORKERS Number of worker processes to launch
--log-interval LOG_INTERVAL
Interval between progress updates
例えば:
python tools/datasets/preprocess_data.py
--input ./data/mydataset.jsonl.zst
--output-prefix ./data/mydataset
--vocab ./data/gpt2-vocab.json
--merge-file gpt2-merges.txt
--dataset-impl mmap
--tokenizer-type GPT2BPETokenizer
--append-eod次に、構成ファイルに次の設定を追加してトレーニングを実行します。
" data-path " : " data/mydataset_text_document " ,トレーニングは、DeepSpeed のランチャーのラッパーであるdeepy.pyを使用して起動されます。これは、多くの GPU/ノード間で同じスクリプトを並行して起動します。
一般的な使用パターンは次のとおりです。
python ./deepy.py train.py [path/to/config1.yml] [path/to/config2.yml] ...任意の数の構成を渡すことができ、実行時にすべてマージされます。
オプションで構成プレフィックスを渡すこともできます。これにより、すべての構成が同じフォルダー内にあると想定され、そのプレフィックスがパスに追加されます。
例えば:
python ./deepy.py train.py -d configs 125M.yml local_setup.ymlこれにより、GPU ごとに 1 つのプロセスを持つすべてのノードにtrain.pyスクリプトがデプロイされます。ワーカー ノードと GPU の数は/job/hostfileファイルで指定されます (パラメーターのドキュメントを参照)。または、単一ノード セットアップで実行している場合は、単にnum_gpus引数として渡すこともできます。
これは厳密には必要ではありませんが、モデル パラメータを 1 つの設定ファイル (例: configs/125M.yml ) で定義し、データ パス パラメータを別の設定ファイル (例: configs/local_setup.yml ) で定義すると便利です。
GPT-NeoX-20B は、Pile でトレーニングされた 200 億パラメーターの自己回帰言語モデルです。 GPT-NeoX-20B の技術的な詳細については、関連する論文を参照してください。このモデルの構成ファイルは、 ./configs/20B.ymlで入手できるほか、以下のダウンロード リンクにも含まれています。
スリムな重み - (オプティマイザ状態なし、推論または微調整用、39 GB)
コマンド ラインから20B_checkpointsという名前のフォルダーにダウンロードするには、次のコマンドを使用します。
wget --cut-dirs=5 -nH -r --no-parent --reject " index.html* " https://the-eye.eu/public/AI/models/GPT-NeoX-20B/slim_weights/ -P 20B_checkpointsフルウェイト - (オプティマイザ状態を含む、268GB)
コマンド ラインから20B_checkpointsという名前のフォルダーにダウンロードするには、次のコマンドを使用します。
wget --cut-dirs=5 -nH -r --no-parent --reject " index.html* " https://the-eye.eu/public/AI/models/GPT-NeoX-20B/full_weights/ -P 20B_checkpointsあるいは、BitTorrent クライアントを使用して重みをダウンロードすることもできます。トレント ファイルはここからダウンロードできます: スリム ウェイト、フル ウェイト。
さらに、トレーニング全体を通じて 1,000 ステップごとに 1 つずつ、150 のチェックポイントが保存されています。私たちはこれらを大規模に提供する最適な方法を見つけることに取り組んでいますが、それまでの間、部分的にトレーニングされたチェックポイントの使用に興味がある人は、アクセスを手配するために [email protected] にメールを送信してください。
Pythia Scaling Suite は、大規模な言語モデルの解釈可能性とトレーニング ダイナミクスに関する研究を促進することを目的として、Pile でトレーニングされた 7,000 万パラメーターから 12B パラメーターにわたるモデルのスイートです。プロジェクトの詳細とモデルへのリンクは、論文内およびプロジェクトの GitHub にあります。
Polyglot プロジェクトは、強力な事前トレーニング済み非英語言語モデルをトレーニングして、機械学習の主要な大国以外の研究者がこのテクノロジーを利用できるようにする取り組みです。 EleutherAI は、1.3B、3.8B、および 5.8B パラメータの韓国語モデルをトレーニングしてリリースしました。そのうち最大のものは、韓国語タスクに関して他の公開されているすべての言語モデルを上回ります。プロジェクトの詳細とモデルへのリンクは、こちらでご覧いただけます。
ほとんどの用途では、推論に最適化された Hugging Face Transformers ライブラリを介して、GPT-NeoX ライブラリを使用してトレーニングされたモデルをデプロイすることをお勧めします。
事前トレーニング済みモデルからの 3 種類の生成をサポートしています。
3 種類のテキスト生成はすべて、 configs/text_generation.ymlに適切な値を設定して、 python ./deepy.py generate.py -d configs 125M.yml local_setup.yml text_generation.ymlを介して起動できます。
GPT-NeoX は、言語モデル評価ハーネスを通じてダウンストリーム タスクの評価をサポートします。
評価ハーネスでトレーニング済みモデルを評価するには、次を実行するだけです。
python ./deepy.py eval.py -d configs your_configs.yml --eval_tasks task1 task2 ... tasknここで、 --eval_tasksは、評価タスクの後にスペースが続くリストです (例: --eval_tasks lambada hellaswag piqa sciq 。利用可能なすべてのタスクの詳細については、lm-evaluation-harness リポジトリを参照してください。
GPT-NeoX はトレーニングのみを目的として高度に最適化されており、GPT-NeoX モデルのチェックポイントは、そのままでは他の深層学習ライブラリと互換性がありません。モデルを簡単にロードしてエンド ユーザーと共有できるようにするため、また、他のさまざまなフレームワークにさらにエクスポートするために、GPT-NeoX は、Hugging Face Transformers 形式へのチェックポイント変換をサポートしています。
NeoX は、AliBi 位置埋め込みを含むさまざまなアーキテクチャ構成をサポートしていますが、これらの構成のすべてが、Hugging Face Transformers 内でサポートされている構成にきれいにマッピングされるわけではありません。
NeoX は、互換性のあるモデルの次のアーキテクチャへのエクスポートをサポートしています。
これらのハグ フェイス トランスフォーマー アーキテクチャのいずれにも適切に適合しないモデルをトレーニングするには、エクスポートされたモデル用のカスタム モデリング コードを作成する必要があります。
GPT-NeoX ライブラリ チェックポイントを Hugging Face 読み込み可能な形式に変換するには、次のコマンドを実行します。
python ./tools/ckpts/convert_neox_to_hf.py --input_dir /path/to/model/global_stepXXX --config_file your_config.yml --output_dir hf_model/save/location --precision {auto,fp16,bf16,fp32} --architecture {neox,mistral,llama}次に、モデルを Hugging Face Hub にアップロードするには、次のコマンドを実行します。
huggingface-cli login
python ./tools/ckpts/upload.pyHF ハブ ユーザー トークンを含む、要求された情報を入力します。
NeoX は、事前トレーニングされたモデルのチェックポイントをライブラリ内でトレーニングできる形式に変換するためのいくつかのユーティリティを提供します。
次のモデルまたはモデル ファミリを GPT-NeoX にロードできます。
2 つの異なるチェックポイント形式を GPT-NeoX と互換性のある形式に変換するための 2 つのユーティリティが提供されています。
Meta AI によって配布された Llama 1 または Llama 2 チェックポイントを元のファイル形式 (ここまたはここからダウンロード可能) から GPT-NeoX ライブラリに変換するには、次のコマンドを実行します。
python tools/ckpts/convert_raw_llama_weights_to_neox.py --input_dir /path/to/model/parent/dir/7B --model_size 7B --output_dir /path/to/save/ckpt --num_output_shards <TENSOR_PARALLEL_SIZE> (--pipeline_parallel if pipeline-parallel-size >= 1)
Hugging Face モデルを NeoX 読み込み可能なモデルに変換するには、 tools/ckpts/convert_hf_to_sequential.pyを実行します。その他のオプションについては、そのファイル内のドキュメントを参照してください。
ログをローカルに保存するだけでなく、Weights & Biases、TensorBoard、Comet という 2 つの一般的な実験モニタリング フレームワークの組み込みサポートも提供しています。
実験を記録する Weights & Biases は、機械学習モニタリング プラットフォームです。 wandb を使用して gpt-neox 実験を監視するには:
wandb login実行することで実行できます。実行は自動的に記録されます。./requirements/requirements-wandb.txtにあり、そこからインストールできます。構成例は./configs/local_setup_wandb.ymlにあります。wandb_group実行グループに名前を付けることができ、 wandb_team実行を組織またはチーム アカウントに割り当てることができます。構成例は./configs/local_setup_wandb.ymlにあります。 tensorboard-dirフィールドを介して TensorBoard の使用をサポートします。 TensorBoard モニタリングに必要な依存関係は、 ./requirements/requirements-tensorboard.txtで見つかり、そこからインストールできます。
Comet は機械学習モニタリング プラットフォームです。 Comet を使用して gpt-neox 実験を監視するには:
comet loginを実行するか、 export COMET_API_KEY=<your-key-here>を渡すことで、実行時に API キーをリンクします。pip install -r requirements/requirements-comet.txtを介して、 comet_mlと依存関係ライブラリをインストールします。use_comet: Trueで Comet を有効にします。 comet_workspaceとcomet_projectを使用して、データが記録される場所をカスタマイズすることもできます。 Comet を有効にした完全な設定例はconfigs/local_setup_comet.ymlで提供されます。MPI ベースの DeepSpeed ランチャーで使用するホストファイルを提供する必要がある場合は、ホストファイルを指すように環境変数DLTS_HOSTFILEを設定できます。
Nsight Systems、PyTorch Profiler、および PyTorch Memory Profiling を使用したプロファイリングをサポートしています。
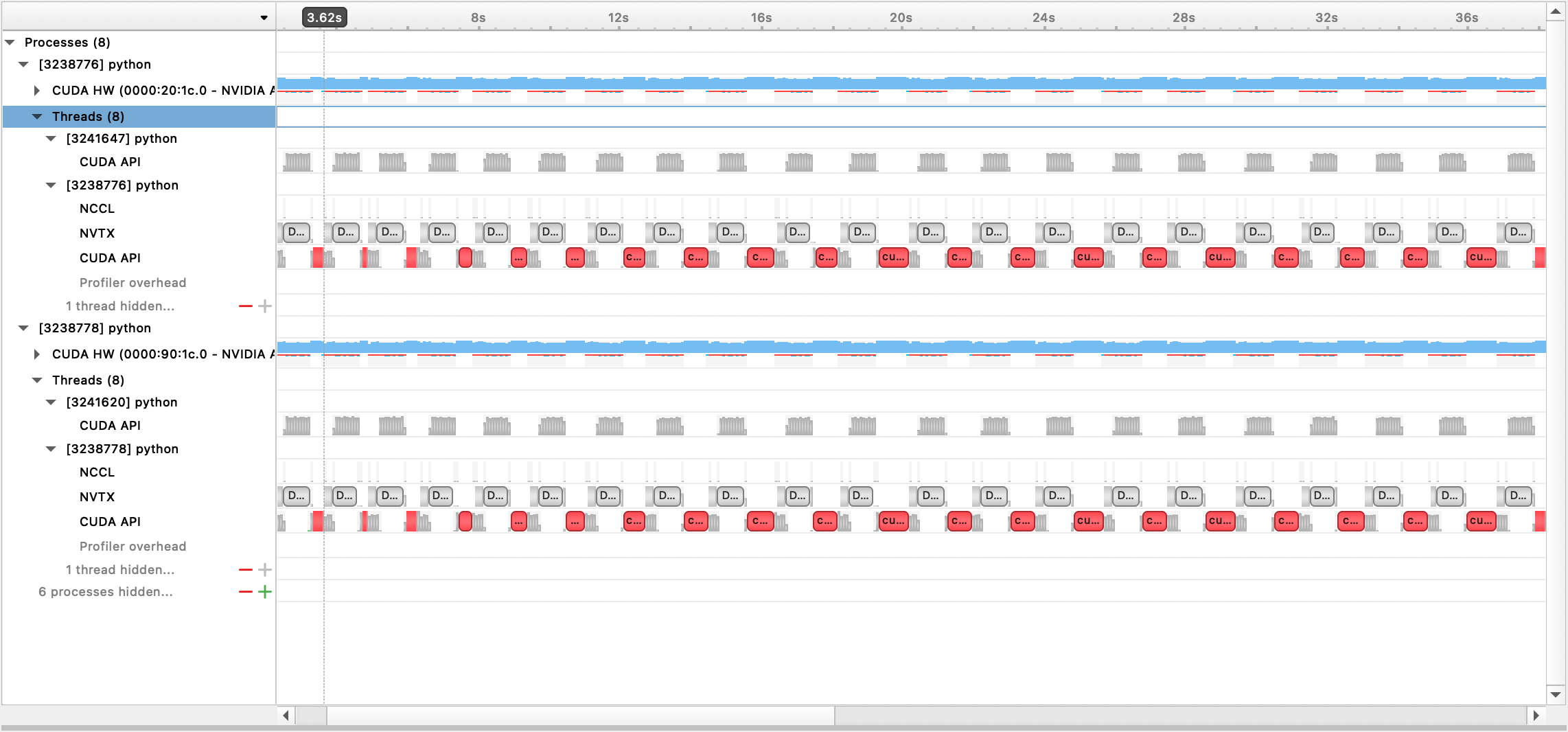
Nsight Systems プロファイリングを使用するには、構成オプションprofile 、 profile_step_start 、およびprofile_step_stopを設定します (引数の使用法についてはここを、サンプル構成についてはここを参照してください)。
nsys メトリクスを設定するには、以下を使用してトレーニングを開始します。
nsys profile -s none -t nvtx,cuda -o <path/to/profiling/output> --force-overwrite true
--capture-range=cudaProfilerApi --capture-range-end=stop python $TRAIN_PATH/deepy.py
$TRAIN_PATH/train.py --conf_dir configs <config files>
生成された出力ファイルは、Nsight Systems GUI で表示できます。
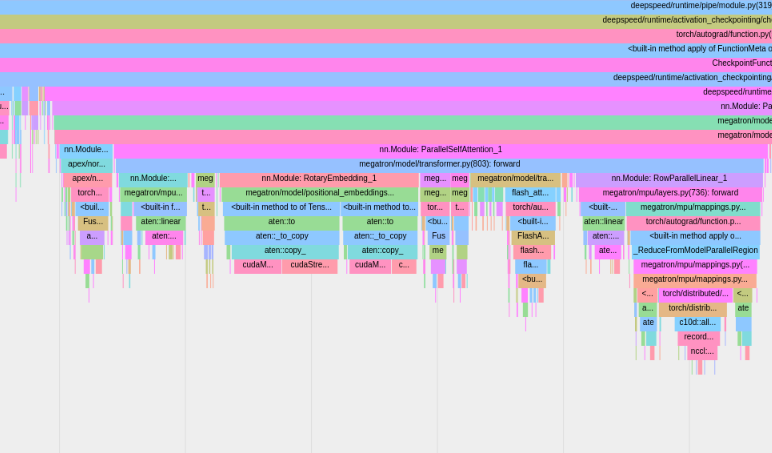
組み込みの PyTorch プロファイラーを使用するには、構成オプションprofile 、 profile_step_start 、およびprofile_step_stopを設定します (引数の使用法についてはここを、サンプル構成についてはここを参照してください)。
PyTorch プロファイラは、 tensorboardログ ディレクトリにトレースを保存します。ここの手順に従って、TensorBoard 内でこれらのトレースを表示できます。
PyTorch メモリ プロファイリングを使用するには、設定オプションmemory_profilingおよびmemory_profiling_pathを設定します(引数の使用法についてはここを、サンプル構成についてはここを参照してください)。
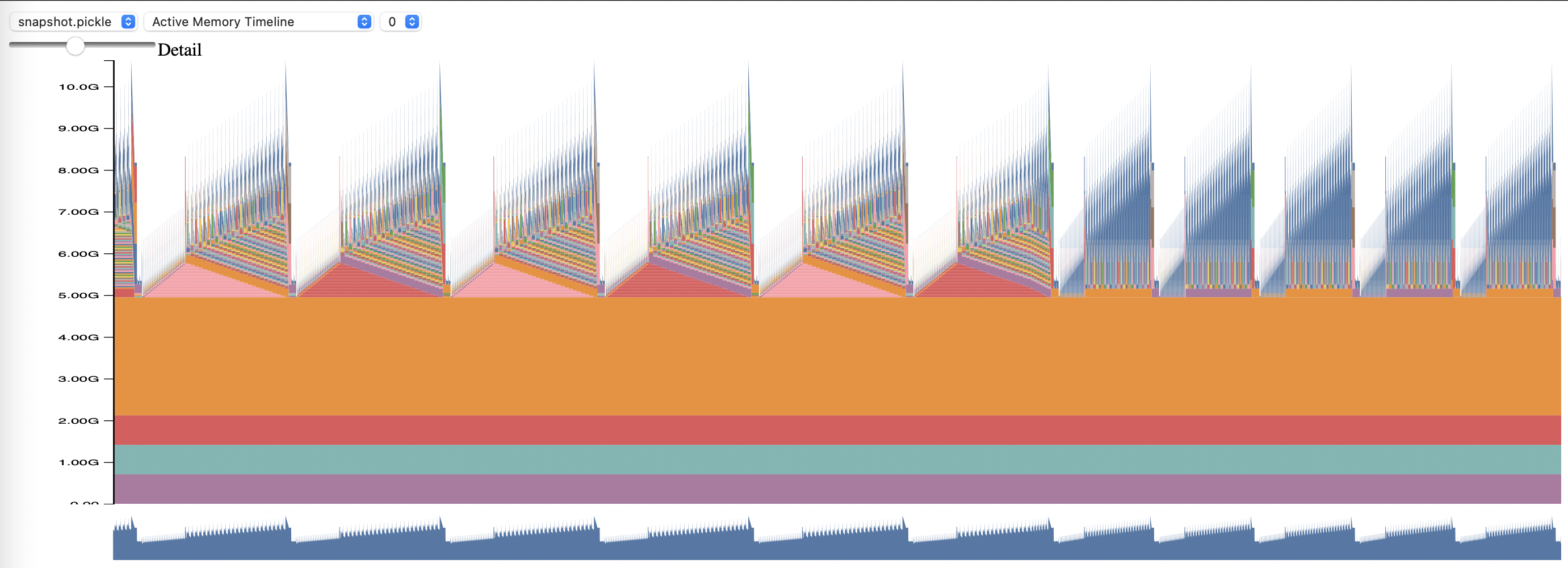
生成されたプロファイルをmemory_viz.pyスクリプトで表示します。以下を使用して実行します:
python _memory_viz.py trace_plot <generated_profile> -o trace.html
GPT-NeoX ライブラリは、学術研究者や業界の研究者によって広く採用され、多くの HPC システムに移植されました。
このライブラリが研究に役立つと思われた場合は、ぜひご連絡ください。ぜひリストに加えていただければ幸いです。
EleutherAI とその協力者は、次の出版物でこれを使用しています。
他の研究グループによる次の出版物では、このライブラリが使用されています。


