TaskMatrix
1.0.0
TaskMatrix はChatGPT と一連の Visual Foundation Model を接続し、チャット中に画像の送受信を可能にします。
私たちの論文を参照してください: Visual ChatGPT: Visual Foundation Models を使用した会話、描画、編集
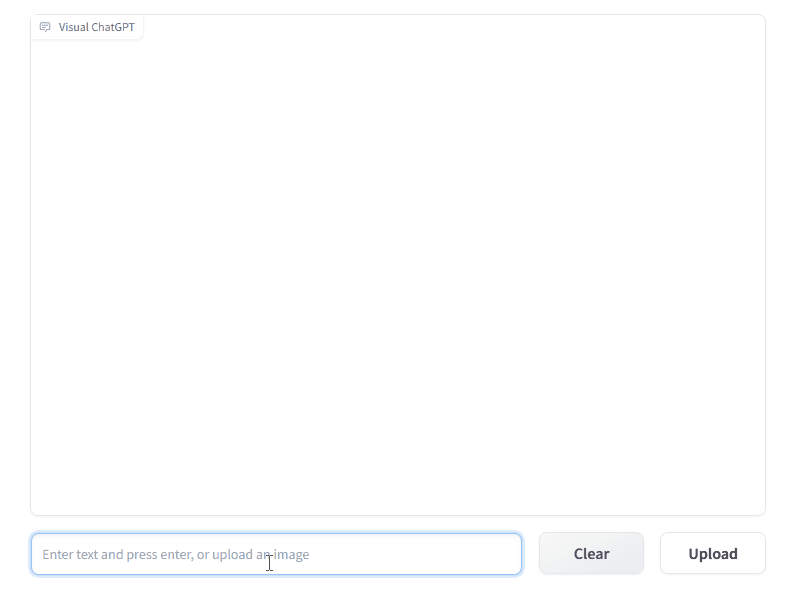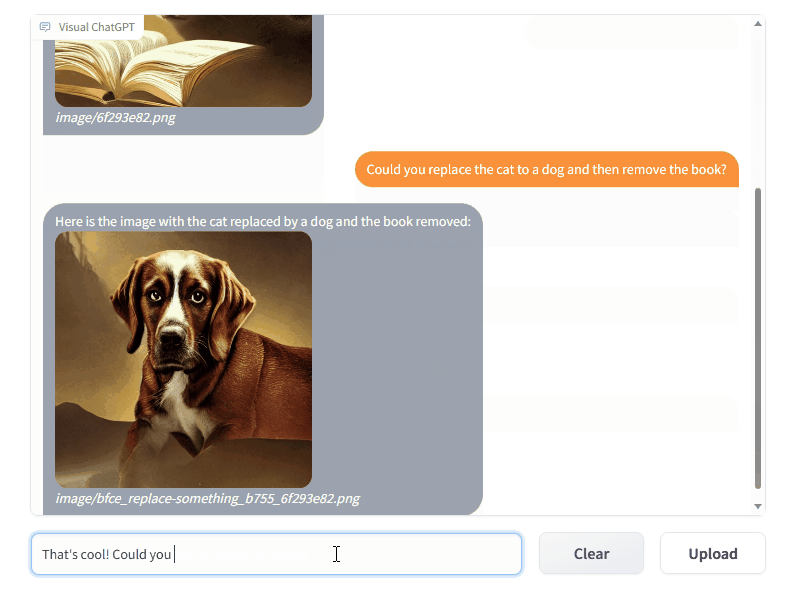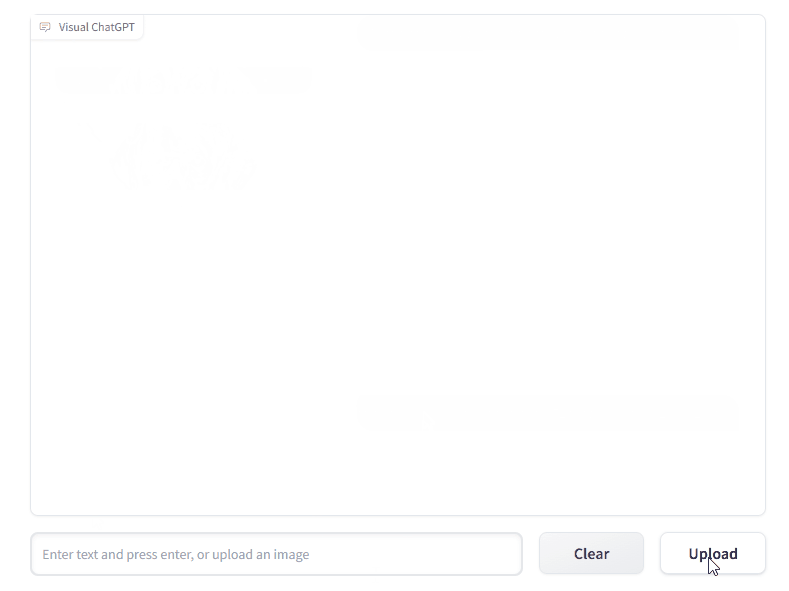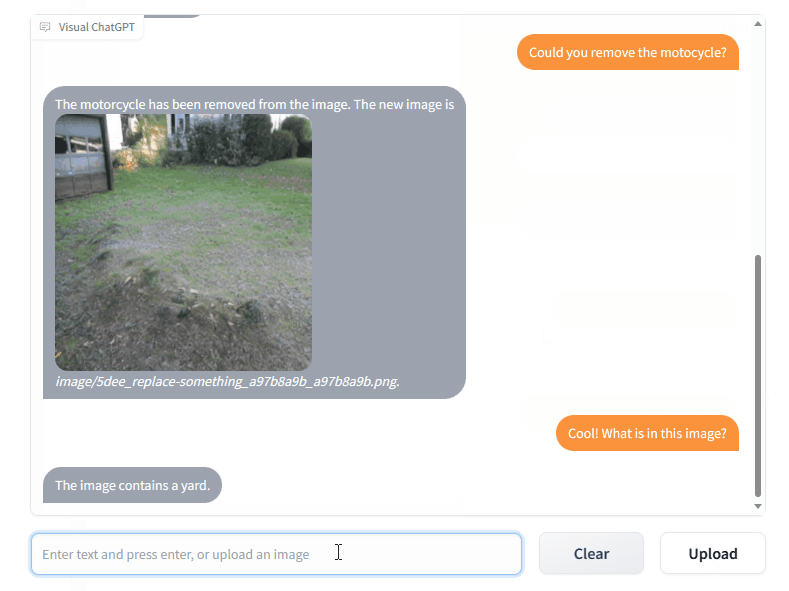
TaskMatrix は GroundingDINO とセグメント何でもサポートするようになりました。 @jordddanの努力に感謝します。画像編集の場合、最初にGroundingDINOを使用して、指定されたテキストにガイドされて境界ボックスを見つけます。次に、 segment-anything使用して関連するマスクを生成し、最後に安定した拡散修復を使用してマスクに基づいて画像を編集します。
python visual_chatgpt.py --load "Text2Box_cuda:0,Segmenting_cuda:0,Inpainting_cuda:0,ImageCaptioning_cuda:0"を実行します。find xxx in the imageまたはsegment xxx in the imageと言います。 xxxオブジェクトです。 TaskMatrix は検出またはセグメンテーションの結果を返します。TaskMatrix が中国語をサポートできるようになりました。 @Wang-Xiaodong1899の尽力に感謝します。
TaskMatrix でテンプレートのアイデアを提案します。
template_model = Trueを持つクラスを追加するだけです。 InfinityOutPaintingクラスのテンプレート例を提供してくれた@Shengmingyingと@thebestannieに感謝します (次の gif を参照)
python visual_chatgpt.py --load "Inpainting_cuda:0,ImageCaptioning_cuda:0,VisualQuestionAnswering_cuda:0"を実行します。extend the image to 2048x1024とします。InfinityOutPaintingテンプレートを作成するだけで、TaskMatrix は追加のトレーニングを必要とせずに、既存のImageCaptioning 、 Inpainting 、およびVisualQuestionAnswering基盤モデルと連携して画像を任意のサイズにシームレスに拡張できます。TaskMatrix にはコミュニティの努力が必要です。新しい興味深い機能を追加するためにあなたの貢献をお待ちしています。

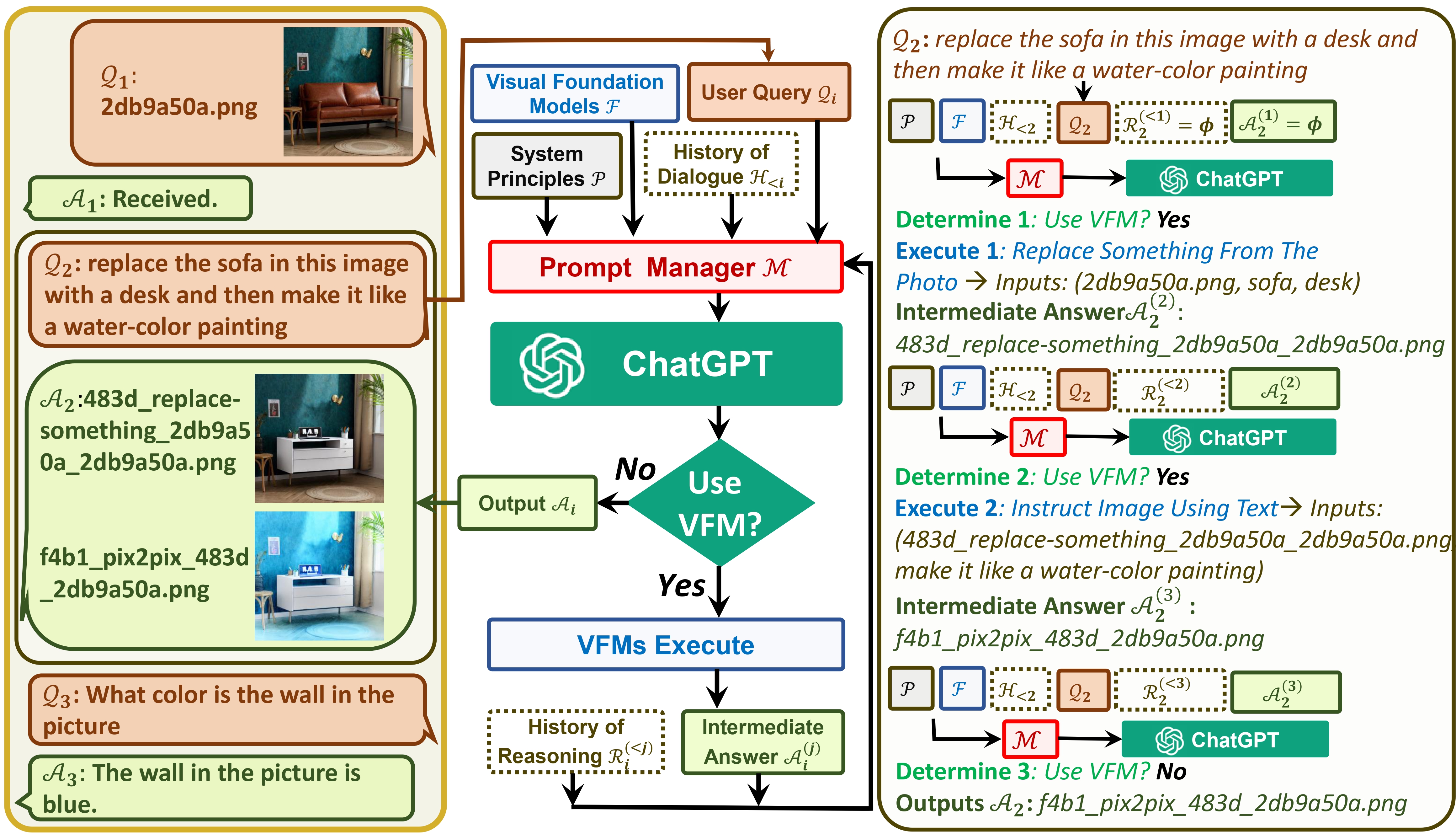
一方では、 ChatGPT (または LLM) は、幅広いトピックについて幅広く多様な理解を提供する一般的なインターフェイスとして機能します。一方、基盤モデルは、特定のドメインに関する深い知識を提供することで、ドメインの専門家として機能します。一般的な知識と深い知識の両方を活用して、さまざまなタスクを処理できるAIの構築を目指します。
# clone the repo
git clone https://github.com/microsoft/TaskMatrix.git
# Go to directory
cd visual-chatgpt
# create a new environment
conda create -n visgpt python=3.8
# activate the new environment
conda activate visgpt
# prepare the basic environments
pip install -r requirements.txt
pip install git+https://github.com/IDEA-Research/GroundingDINO.git
pip install git+https://github.com/facebookresearch/segment-anything.git
# prepare your private OpenAI key (for Linux)
export OPENAI_API_KEY={Your_Private_Openai_Key}
# prepare your private OpenAI key (for Windows)
set OPENAI_API_KEY={Your_Private_Openai_Key}
# Start TaskMatrix !
# You can specify the GPU/CPU assignment by "--load", the parameter indicates which
# Visual Foundation Model to use and where it will be loaded to
# The model and device are separated by underline '_', the different models are separated by comma ','
# The available Visual Foundation Models can be found in the following table
# For example, if you want to load ImageCaptioning to cpu and Text2Image to cuda:0
# You can use: "ImageCaptioning_cpu,Text2Image_cuda:0"
# Advice for CPU Users
python visual_chatgpt.py --load ImageCaptioning_cpu,Text2Image_cpu
# Advice for 1 Tesla T4 15GB (Google Colab)
python visual_chatgpt.py --load "ImageCaptioning_cuda:0,Text2Image_cuda:0"
# Advice for 4 Tesla V100 32GB
python visual_chatgpt.py --load "Text2Box_cuda:0,Segmenting_cuda:0,
Inpainting_cuda:0,ImageCaptioning_cuda:0,
Text2Image_cuda:1,Image2Canny_cpu,CannyText2Image_cuda:1,
Image2Depth_cpu,DepthText2Image_cuda:1,VisualQuestionAnswering_cuda:2,
InstructPix2Pix_cuda:2,Image2Scribble_cpu,ScribbleText2Image_cuda:2,
SegText2Image_cuda:2,Image2Pose_cpu,PoseText2Image_cuda:2,
Image2Hed_cpu,HedText2Image_cuda:3,Image2Normal_cpu,
NormalText2Image_cuda:3,Image2Line_cpu,LineText2Image_cuda:3"
ここでは、各ビジュアル基盤モデルの GPU メモリ使用量をリストします。好みのモデルを指定できます。
| 基礎モデル | GPU メモリ (MB) |
|---|---|
| 画像編集 | 3981 |
| InstructPix2Pix | 2827 |
| テキスト2画像 | 3385 |
| 画像キャプション | 1209 |
| 画像2キャニー | 0 |
| CannyText2Image | 3531 |
| 画像2ライン | 0 |
| ラインテキスト2画像 | 3529 |
| 画像2頭 | 0 |
| HedText2Image | 3529 |
| 画像2落書き | 0 |
| 落書きテキスト 2 イメージ | 3531 |
| 画像2ポーズ | 0 |
| ポーズテキスト2画像 | 3529 |
| 映像2セグ | 919 |
| セグメントテキスト 2 イメージ | 3529 |
| 画像2奥行き | 0 |
| 深さテキスト 2 イメージ | 3531 |
| 画像2通常 | 0 |
| NormalText2Image | 3529 |
| 視覚的な質問への回答 | 1495年 |
次のプロジェクトのオープンソースに感謝します。
ハグチェーン LangChain 安定拡散制御Net InstructPix2Pix CLIPSeg BLIP
TaskMatrix の使用に関するヘルプや問題が必要な場合は、GitHub の問題を送信してください。
その他の連絡については、Chenfei WU ([email protected]) または Nan DUAN ([email protected]) までお問い合わせください。
商標 このプロジェクトには、プロジェクト、製品、またはサービスの商標またはロゴが含まれている場合があります。 Microsoft の商標またはロゴの許可された使用には、Microsoft の商標およびブランド ガイドラインが適用され、それに従わなければなりません。このプロジェクトの修正バージョンで Microsoft の商標またはロゴを使用することは、混乱を引き起こしたり、Microsoft のスポンサーであることを暗示したりしてはなりません。第三者の商標またはロゴの使用には、それらの第三者のポリシーが適用されます。
このリポジトリで推奨されるモデルは単なる例であり、Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models で公開された論文によるタスク自動化の概念とベンチマークを調査する科学的研究に使用されています。ユーザーは、研究のニーズに応じて、このリポジトリ内のモデルを置き換えることができます。本リポジトリの推奨モデルを使用する場合は、それぞれのモデルのライセンスに準拠する必要があります。 Microsoft は、このリポジトリの使用に起因する第三者の権利の侵害に対して責任を負わないものとします。ユーザーは、このリポジトリから生じるあらゆる請求に関連するすべての損害、費用、および弁護士費用から Microsoft を弁護し、補償し、免責することに同意します。このリポジトリがあなたの権利を侵害していると思われる場合は、プロジェクト所有者の電子メールに通知してください。


