Awesome Attention Heads
vey on LLM attention heads
重要
このレポについて。これは、LLM のさまざまな種類のアテンション ヘッドに関する最新の研究を入手するためのプラットフォームです。また、これらの素晴らしい作品をもとにしたアンケートも発表しました。
私たちの成果を引用したい場合は、bibtex エントリ: CITATION.bib を参照してください。
関連論文リストだけを見たい場合は、ここから直接ジャンプしてください。
このリポジトリに貢献したい場合は、ここを参照してください。
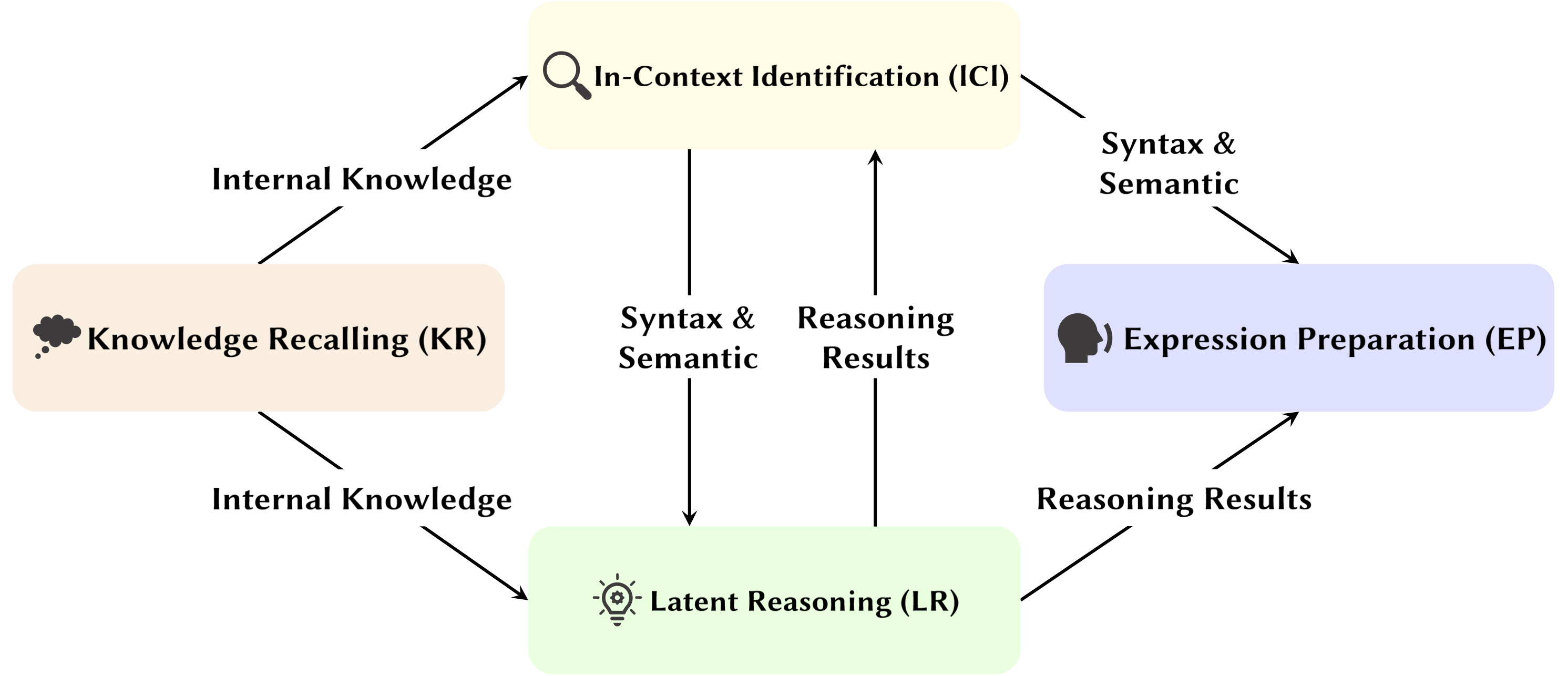
大規模言語モデル (LLM) の開発に伴い、その基礎となるネットワーク構造であるトランスフォーマーが広範囲に研究されています。 Transformer の構造を研究することは、この「ブラック ボックス」についての理解を深め、モデルの解釈可能性を向上させるのに役立ちます。最近、モデルには 2 つの異なる部分が含まれていることを示唆する研究が増えています。1 つは動作、推論、分析に使用される注意メカニズム、もう 1 つは知識の保存のためのフィードフォワード ネットワーク (FFN) です。前者は、モデルの機能的能力を明らかにするために重要であり、アテンション メカニズム内のさまざまな機能を探索する一連の研究につながります。これを私たちはアテンション ヘッド マイニングと名付けました。
この調査では、LLM のアテンションヘッドが推論プロセスにどのように貢献するかについての潜在的なメカニズムを掘り下げます。
ハイライト:
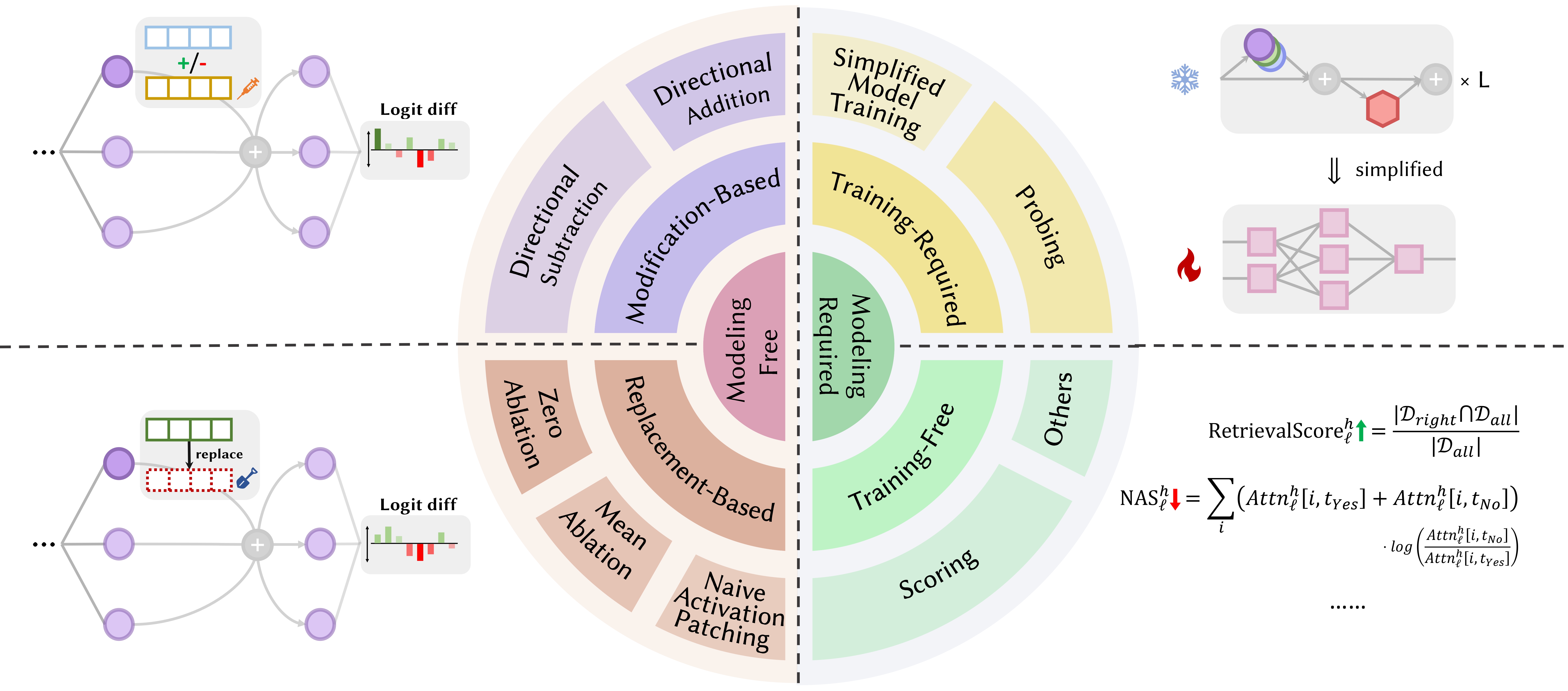
以下の論文は出版日順に並べられています。
2024 年
| 日付 | 論文と概要 | タグ | リンク |
| 2024-11-15 | SEEKR: 大規模言語モデルの継続学習のための選択的注意誘導型知識保持 | ||
| • LLM の継続学習のための選択的注意誘導型知識保持方法である SEEKR を提案し、効率的な蒸留のための重要な注意点に焦点を当てます。 • 継続学習ベンチマーク TRACE および SuperNI で評価。 • SEEKR は、他の方法と比較して、わずか 1% の再生データで同等以上のパフォーマンスを達成しました。 | |||
| 2024-11-06 | トランスフォーマーが命題論理問題をどのように解決するか: メカニズムの分析 | ||
| • 「計画」と「推論」メカニズムに焦点を当て、命題論理問題を解決する変圧器内の特定の注目回路を特定します。 • 推論経路を明らかにするためにアクティベーション パッチを使用して、小型トランスとミストラル-7B を分析しました。 • ルールの場所、事実の処理、論理的推論における意思決定を専門とする、明確な注意頭が見つかりました。 | |||
| 2024-11-01 | アテンション トラッカー: LLM でのプロンプト インジェクション攻撃の検出 | ||
| • 提案されたアテンション トラッカー。識別された重要なヘッドに基づいてプロンプト インジェクション攻撃を検出する、シンプルかつ効果的なトレーニング不要のガードです。 • LLM によって生成されたランダムな文の少数のセットと単純な無視攻撃を組み合わせて、重要なヘッドを特定しました。 • アテンション トラッカーは小規模 LM と大規模 LM の両方で効果的であり、以前のトレーニング不要の検出方法の重大な制限に対処します。 | |||
| 2024-10-28 | アルゴリズムを使わない算術: 言語モデルはヒューリスティックの袋を使って数学を解く | ||
| • 基本的な算術論理に対するモデルの動作のほとんどを説明するモデルのサブセット (回路) を特定し、その機能を検査します。 • アラビア数字と 4 つの基本演算子 (+、−、×、÷) を使用した 2 オペランドの算術プロンプトを使用して、注意パターンを分析しました。 • 加算、減算、除算では、6 つのアテンション ヘッドで高い忠実度 (平均 97%) が得られますが、乗算では 90% の忠実度を超えるには 20 のヘッドが必要です。 | |||
| 2024-10-21 | 議論の役割に対する言語モデルの感度の心理言語学的評価 | ||
| • より一般化された設定で被験者の頭部を観察。 • swap-arguments と replace-argument の条件下でのアテンション パターンを分析しました。 • 役割を区別できるにもかかわらず、問題はこの情報が動詞表現にエンコードされる方法にあるため、モデルは引数の役割情報を正しく使用するのに苦労する可能性があり、その結果役割の感度が低くなります。 | |||
| 2024-10-17 | アクティブ・ドーマント・アテンション・ヘッズ: LLM におけるエクストリーム・トークン現象を機械的に解明する | ||
| • 極端なトークン現象は、事前トレーニング中の相互強化メカニズムと結合した、アテンションヘッドのアクティブ-休止メカニズムから生じることを実証しました。 • Bigram-Backcopy (BB) タスクでトレーニングされた単純なトランスフォーマーを使用して、極端なトークン現象を分析し、それを事前トレーニングされた LLM に拡張します。 • BB タスクによって予測されるエクストリーム トークン現象の静的および動的特性の多くは、事前学習済み LLM での観察と一致します。 | |||
| 2024-10-17 | 大規模言語モデルの安全性におけるアテンションヘッドの役割について | ||
| • モデルの安全性に対する個々のヘッドの貢献を評価するために、複数のヘッドの注意に合わせた新しい指標である安全ヘッド重要スコア (Ships) を提案しました。 • これらの安全注意ヘッドの機能に関する分析を実施し、その特性とメカニズムを調査しました。 • 特定のアテンション ヘッドは安全性にとって重要であり、安全ヘッドは微調整されたモデル全体で重複しており、これらのヘッドのアブレーションによる有用性への影響は最小限に抑えられます。 | |||
| 2024-10-14 | DuoAttend: 取得ヘッドとストリーミング ヘッドを使用した効率的なロングコンテキスト LLM 推論 | ||
| • LLM 内の取得ヘッドとストリーミング ヘッドの発見に基づいて、LLM のロングコンテキスト機能を損なうことなく、LLM のデコードとプリフィルのメモリとレイテンシの両方を削減するフレームワークである DuoAttend を導入しました。 • ショートコンテキストタスクとロングコンテキストタスクの両方における LLM のパフォーマンスとその推論効率に対するフレームワークの影響をテストします。 • DuoAttention は、フル KV キャッシュを取得ヘッドのみに適用することで、ロングコンテキスト アプリケーションのデコードと事前入力の両方でメモリ使用量と遅延を大幅に削減します。 | |||
| 2024-10-14 | 微調整された LLM の安全性をロックダウンする | ||
| • LLM 内のセーフティ ヘッドの発見に基づいて、さまざまなリスク レベルおよび攻撃シナリオにわたって微調整された大規模言語モデルの安全性を維持するための斬新で効率的な方法である SafetyLock を導入しました。 • モデルの安全性と推論効率を強化する際の SafetyLock の有効性を評価します。 • SafetyLock は、セーフティ ヘッドに介入ベクトルを適用することで、推論中にモデルの内部アクティベーションを無害化する方向に変更し、応答への影響を最小限に抑えながら正確な安全調整を実現します。 | |||
| 2024-10-11 | 同じだけど違う: 多言語言語モデリングにおける構造の類似点と相違点 | ||
| • 言語固有の形態学的プロセスを必要とするタスクを実行する際に、多言語モデルが依存する特定のコンポーネントについて詳細な調査を実施しました。 • 英語と中国語でタスクを実行する場合の内部モデル コンポーネントの機能の違いを調査します。 • コピーヘッドはどちらの言語でも同様に高いアクティブ化頻度を持ちますが、過去形ヘッドは英語でのみ頻繁にアクティブ化されます。 | |||
| 2024-10-08 | ぐるぐるウィーゴー!ロータリー位置エンコーディングはなぜ役立つのでしょうか? | ||
| • RoPE が機械レベルでどのように使用されているかを理解するために、トレーニングされた Gemma 7B モデルの内部の詳細な分析を提供しました。 • クエリとキーにおけるさまざまな頻度の使用法を理解しました。 • RoPE の最高周波数は特別な「位置」アテンション ヘッド (対角ヘッド、前のトークン ヘッド) を構築するために Gemma 7B によって巧みに使用され、低周波数はアポストロフィ ヘッドによって使用されることがわかりました。 | |||
| 2024-10-06 | 大規模言語モデルにおけるコンテキスト内学習推論回路の再考 | ||
| • ICL の推論プロセスを特徴付けるために、包括的な 3 ステップの推論回路を提案しました。 • ICL を 3 つのステージ (要約、セマンティクス マージ、機能の取得とコピー) に分割し、ICL とその運用メカニズムで各ステージが果たす役割を分析します。 • 誘導ヘッドの前に、フォアランナー トークン ヘッドがまずデモンストレーションとラベルのセマンティクス間の互換性に基づいて、フォアランナー トークンのデモンストレーション テキスト表現を対応するラベル トークンに選択的にマージすることがわかりました。 | |||
| 2024-10-01 | 回路トレースに適用されたスパース アテンション分解 | ||
| • スパース アテンション分解を導入し、アテンション ヘッド マトリックスで SVD を使用して GPT-2 モデルの通信パスを追跡します。 • 間接オブジェクト識別 (IOI) タスク用の GPT-2 Small の回路トレースに適用されます。 • アテンションヘッド間のまばらで機能的に重要な通信信号を特定し、解釈可能性を向上させます。 | |||
| 2024-09-09 | 誘導ヘッドの公開: トランスフォーマーにおける証明可能なトレーニング ダイナミクスと特徴学習 | ||
| • この論文では、一般化された誘導ヘッド メカニズムを紹介し、変圧器コンポーネントがどのように連携して n グラム マルコフ連鎖上でインコンテキスト学習 (ICL) を実行するかを説明します。 • 勾配フローを使用した 2 アテンション層トランスフォーマーを分析して、マルコフ連鎖のトークンを予測します。 • 勾配流が収束し、学習された機能ベースの誘導ヘッド機構を通じて ICL が可能になります。 | |||
| 2024-08-16 | 自己回帰言語モデルにおける三段論的推論の機械的解釈 | ||
| • この研究は、LM における三段論的推論の機械的解釈を導入し、内容に依存しない推論回路を特定します。 • 注意頭における信念バイアス汚染を推論および調査するための回路の発見。 • 三段論法スキーム間で移行可能な必要な推論回路を特定しましたが、事前に訓練された世界知識による汚染の影響を受けやすいです。 | |||
| 2024-08-01 | モデル編集による大規模言語モデルの意味の一貫性の強化: 解釈可能性指向のアプローチ | ||
| • アテンションヘッドに焦点を当てた費用対効果の高いモデル編集アプローチを導入し、大規模なパラメータ変更を行わずに LLM のセマンティック一貫性を強化します。 • アテンションヘッドを分析し、バイアスを注入し、NLU および NLG データセットでテストしました。 • 追加タスク全体にわたる強力な一般化により、セマンティックの一貫性とタスクのパフォーマンスにおいて顕著な改善を達成しました。 | |||
| 2024-07-31 | 負の注意スコア調整による大規模言語モデルの負のバイアスの修正 | ||
| • 言語モデルにおける否定的なバイアスを定量化して修正するために、Negative Attendance Score (NAS) を導入しました。 • ネガティブに偏った注意力を特定し、微調整のためにネガティブ注意スコア アライメント (NASA) を提案しました。 • NASA は、二分決定タスクの一般化を維持しながら、適合率と再現率のギャップを効果的に削減しました。 | |||
| 2024-07-29 | 機械的解釈による言語モデルの脆弱性の検出と理解 | ||
| • LLM の脆弱性、特に敵対的攻撃を検出して理解するために、機械的解釈可能性 (MI) を使用する方法を導入します。 • 3 文字の頭字語を予測する際の脆弱性について GPT-2 Small を分析します。 • タスクに関連するモデル内の特定の脆弱性を適切に特定し、説明します。 | |||
| 2024-07-22 | RazorAttention: 取得ヘッドによる効率的な KV キャッシュ圧縮 | ||
| • 重要なトークン情報を保存するために取得ヘッドと補償トークンを使用する、トレーニング不要の KV キャッシュ圧縮技術である RazorAttend を導入しました。 • 効率性のために大規模言語モデル (LLM) で RazorAttend を評価しました。 • 目立ったパフォーマンスへの影響を与えることなく、KV キャッシュ サイズの 70% 以上の削減を達成しました。 | |||
| 2024-07-21 | 答えて、組み立てて、エース: トランスフォーマーが多肢選択式の質問にどのように答えるかを理解する | ||
| • この論文では、正しい MCQA の答えを予測する隠れた状態を特定するために、語彙の投影とアクティベーション パッチを導入しています。 • トランスフォーマーでの回答選択を担当する主要なアテンションヘッドとレイヤーを特定しました。 • 中間層のアテンション ヘッドは、正確な答えの予測に不可欠であり、まばらなヘッドのセットが独自の役割を果たします。 | |||
| 2024-07-09 | インコンテキスト学習におけるパターンマッチングに不可欠なメカニズムとしての誘導ヘッド | ||
| • この記事では、インコンテキスト学習 (ICL) におけるパターン マッチングに誘導ヘッドが重要であると特定しています。 • 抽象パターン認識および NLP タスクに関して Llama-3-8B および InternLM2-20B を評価しました。 • アブレーション誘導ヘッドにより ICL のパフォーマンスが最大約 32% 低下し、パターン認識がランダムに近くなります。 | |||
| 2024-07-02 | 比較ニューロン分析による大規模言語モデルの算術メカニズムの解釈 | ||
| • 比較ニューロン分析 (CNA) を導入して、大規模な言語モデルのアテンション ヘッドに算術メカニズムをマップします。 • 算術能力の分析、算術タスクのモデル枝刈り、性別による偏見を減らすためのモデル編集。 • 演算を担当する特定のニューロンを特定し、ターゲットを絞ったニューロン操作によりパフォーマンスの向上とバイアスの軽減を可能にします。 | |||
| 2024-07-01 | 言語を越えた情報検索のための大規模言語モデルの操作 | ||
| • アクティベーション ステアリング多言語検索 (ASMR) を導入し、ステアリング アクティベーションを使用して LLM をガイドし、言語を超えた情報検索を改善します。 • 精度と言語の一貫性に影響を与える LLM のアテンションヘッドを特定し、ステアリングアクティベーションを適用しました。 • ASMR は、XOR-TyDi QA や MKQA などの CLIR ベンチマークで最先端のパフォーマンスを達成しました。 | |||
| 2024-06-25 | トランスフォーマーが勾配降下法で因果構造を学習する方法 | ||
| • トランスフォーマーが勾配ベースのトレーニング アルゴリズムを通じて因果構造を学習する方法について説明しました。 • 因果構造を持つランダムシーケンスと呼ばれるタスクにおける 2 層トランスフォーマーのパフォーマンスを分析しました。 • 単純化された 2 層変換器の勾配降下法は、最初の注目層の潜在因果グラフをエンコードすることによってこのタスクを解決することを学習します。特殊なケースとして、シーケンスがコンテキスト内のマルコフ連鎖から生成される場合、変換器は誘導ヘッドの開発を学習します。 | |||
| 2024-06-21 | MoA: 大規模言語モデルの自動圧縮のためのまばらな注意の混合 | ||
| • この論文では、さまざまなヘッドおよびレイヤーに個別のスパース アテンション構成を調整し、メモリ、スループット、および精度とレイテンシのトレードオフを最適化する Mixture of tention (MoA) を紹介します。 • MoA はモデルをプロファイリングし、アテンション設定を調査し、LLM 圧縮を改善します。 • MoA により、実効コンテキスト長が 3.9 倍増加し、GPU メモリ使用量が 1.2 ~ 1.4 倍削減されます。 | |||
| 2024-06-19 | 大規模な言語モデルにおける忠実な思考連鎖推論の難しさについて | ||
| • LLM における思考連鎖 (CoT) 推論の忠実性を向上させるために、コンテキスト内学習、微調整、およびアクティベーション編集のための新しい戦略を導入しました。 • これらの戦略を複数のベンチマークでテストし、その有効性を評価しました。 • CoT の忠実性の向上には限定的な成功しか見出されず、LLM で真に忠実な推論を達成する際の課題が浮き彫りになった。 | |||
| 2024-06-04 | イテレーションヘッド: 思考連鎖のメカニズムの研究 | ||
| • 思考連鎖 (CoT) タスクのトランスフォーマーで反復推論を可能にする特殊なアテンション ヘッドである「反復ヘッド」を導入します。 • 注意メカニズムの分析、CoT 出現の追跡、およびタスク間の CoT スキルの伝達可能性のテスト。 • イテレーションヘッドは CoT 推論を効果的にサポートし、モデルの解釈可能性とタスクのパフォーマンスを向上させます。 | |||
| 2024-06-03 | LoFiT: LLM 表現のローカライズされた微調整 | ||
| • Localized Fine-tuning on LLM Representations (LoFiT) を導入します。これは、特定のタスクの重要な注目ヘッドを特定し、特定されたヘッドの表現に介入するタスク固有のオフセット ベクトルを学習するための 2 段階のフレームワークです。 • 真実性と推論に関する下流の精度を向上させるために、重要な注意の対象となるまばらなセットを特定しました。 • LoFiT は、LLM のアテンション ヘッド全体の 10% にのみ介入したにもかかわらず、TruthfulQA、CLUTRR、および MQuAKE で他の表現介入手法を上回り、PEFT 手法と同等のパフォーマンスを達成しました。 | |||
| 2024-05-28 | 事前学習済みトランスフォーマーの知識回路 | ||
| • トランスフォーマーに「知識回路」を導入し、アテンション ヘッド、リレーション ヘッド、および MLP 間の相互作用を通じて特定の知識がどのようにエンコードされるかを明らかにしました。 • GPT-2 と TinyLLAMA を分析して知識回路を特定しました。知識編集技術を評価しました。 • 知識回路が幻覚や文脈内学習などのモデル行動にどのように寄与するかを実証しました。 | |||
| 2024-05-23 | トランスフォーマーにおける文脈内学習を人間のエピソード記憶に結びつける | ||
| • Transformer モデルのコンテキスト内学習を人間のエピソード記憶にリンクし、誘導ヘッドとコンテキスト維持および検索 (CMR) モデルの間の類似点を強調します。 • アテンションヘッドにおける CMR のような動作を実証するための、Transformer ベースの LLM の分析。 • CMR のような頭が中間層に出現し、人間の記憶バイアスを反映します。 | |||
| 2024-05-07 | GPT-2 はどのように頭字語を予測しますか?機械的な解釈による回路の抽出と理解 | ||
| • アテンションヘッドを使用して複数トークンの頭字語を予測するための GPT-2 に関する最初の機械的解釈可能性研究。 • 頭字語の予測を担当する 8 つのアテンション ヘッドの回路を特定し、解釈しました。 • これら 8 つの見出し (全体の約 5%) に頭字語予測機能が集中していることが実証されました。 | |||
| 2024-05-02 | 算術計算における大規模言語モデルの解釈と改善 | ||
| • 「identify-analyze-finetune」パイプラインに従って、数学的タスクを通じて LLM の内部メカニズムの詳細な調査を導入します。 • 加算、減算、乗算、除算など、2 つのオペランドを含む算術タスクを実行するモデルの機能を分析しました。 • LLM には、計算プロセス中にオペランドと演算子に焦点を当てる上で極めて重要な役割を果たすアテンション ヘッドのごく一部 (< 5%) が関与することが多いことがわかりました。 | |||
| 2024-05-02 | 誘導ヘッドには何が必要ですか?文脈内学習回路とその形成に関する機構的研究 | ||
| • 変圧器における誘導ヘッド (IH) の形成を研究するために、光遺伝学にヒントを得た因果関係のフレームワークを導入しました。 • 合成データを使用して変圧器における IH の発生を分析し、IH 形成の原因となる 3 つの基礎的なサブ回路を特定しました。 • これらのサブ回路が相互作用して、モデル損失の相変化と同時に IH 形成を促進することを発見。 | |||
| 2024-04-24 | 検索ヘッドが長期コンテキストの事実を機械的に説明する | ||
| • 長いコンテキストにわたる情報の取得を担当するトランスフォーマー モデル内の「検索ヘッド」を特定しました。 • 思考連鎖推論における検索ヘッドの役割の分析を含む、さまざまなモデルにわたる検索ヘッドの体系的な調査。 • 回収ヘッドを剪定すると幻覚が起こりますが、非回収ヘッドを剪定しても回収能力には影響しません。 | |||
| 2024-03-27 | 非線形推論時間介入: LLM の信頼性の向上 | ||
| • 非線形推論時間介入 (NL-ITI) を導入し、微調整を行わずにマルチトークンのプローブと介入によって LLM の真実性を強化しました。 • TruthfulQA を含む多肢選択データセットで NL-ITI を評価しました。 • TruthfulQA ではベースライン ITI と比較して MC1 精度が 16% 相対的に向上しました。 | |||
| 2024-02-28 | 段階的に考える方法: 思考連鎖推論の機構的理解 | ||
| • 神経機能コンポーネントの観点から、LLM における CoT 媒介推論の詳細な分析を提供しました。 • 意思決定、コピー、帰納的推論を必要とする一定数のサブタスクの構成としての架空推論に関する CoT ベースの推論を分析し、それらのメカニズムを個別に分析します。 • アテンションヘッドは、存在論的に関連する (または否定的に関連する) トークン間で情報の移動を実行し、その結果、これらのトークンのペアが明確に識別可能な表現になることがわかりました。 | |||
| 2024-02-28 | 首を切り落とせば対立は終わる: 言語モデルにおける知識の対立を解釈し軽減するメカニズム | ||
| • PH3 メソッドを導入して競合するアテンションヘッドを除去し、パラメーターを更新せずに言語モデル内の知識の競合を軽減します。 • 内部メモリと外部コンテキストに対する LM の依存を制御するために PH3 を適用し、オープンドメインの QA タスクでその有効性をテストしました。 • PH3 により、内部メモリ使用量が 44.0%、外部コンテキスト使用量が 38.5% 改善されました。 | |||
| 2024-02-27 | 情報フロー ルート: 言語モデルを大規模に自動的に解釈する | ||
| • 言語モデルのグラフベースの解釈に属性を使用する「情報フロー ルート」を導入し、アクティベーション パッチを回避します。 • Llama 2 を使った実験。さまざまなドメインやタスクにわたって主要な注意の対象と行動パターンを特定します。 • 特殊なモデルコンポーネントを明らかにしました。同じ品詞のトークンの処理など、アテンションヘッドの一貫した役割を特定しました。 | |||
| 2024-02-20 | コンテキスト内学習を理解するための意味誘導ヘッドを特定する | ||
| • 文脈内学習能力と相関する大規模言語モデル (LLM) の「意味誘導ヘッド」を特定し、研究します。 • 構文上の依存関係とナレッジ グラフの関係をエンコードするための分析されたアテンション ヘッド。 • 特定のアテンションヘッドは、LLM のコンテキスト内学習を理解するために重要な、関連するトークンを思い出すことによって出力ロジットを強化します。 | |||
| 2024-02-16 | 統計的帰納法ヘッドの進化: 文脈内学習マルコフ連鎖 | ||
| • マルコフ連鎖シーケンス モデリング タスクを導入して、インコンテキスト学習 (ICL) 機能が変圧器でどのように発生し、「統計的誘導ヘッド」を形成するかを分析します。 • マルコフ連鎖タスクに関する変圧器の多段階トレーニングの実証的および理論的調査。 • トランス層の相互作用の影響を受ける、ユニグラム予測からバイグラム予測への相転移を示します。 | |||
| 2024-02-11 | 事実の要約: LLM における事実の想起の背後にある付加的なメカニズム | ||
| • 事実想起における「相加的モチーフ」を特定し、説明します。LLM は、事実を想起するために建設的に干渉する複数の独立したメカニズムを使用します。 • アテンションヘッドを分析するための直接ロジット帰属を拡張し、混合ヘッドの動作を解明しました。 • LLM における事実の想起は、複数の独立して不十分な寄与の合計から生じることを実証しました。 | |||
| 2024-02-05 | 大規模な言語モデルはコンテキスト内でどのように学習するのでしょうか?クエリとインコンテキスト ヘッドのキー マトリックスはメトリック学習の 2 つの塔です | ||
| • インコンテキスト ヘッドのクエリ マトリックスとキー マトリックスがメトリック学習の「2 つのタワー」として機能するという概念を導入し、ラベル特徴間の類似性計算を容易にします。 • 分析されたコンテキスト内学習メカニズム。 ICLにとって重要な特定の注意点を特定しました。 • これらのヘッドの 1% のみに介入することにより、ICL 精度が 87.6% から 24.4% に低下しました。 | |||
| 2024-01-23 | コンテキスト内の言語学習: アーキテクチャとアルゴリズム | ||
| • 特殊な Transformer アテンション ヘッドである「n グラム ヘッド」の導入により、入力条件付きトークン予測を通じてコンテキスト内言語学習 (ICLL) が強化されます。 • ランダムな有限オートマトンから正規言語でニューラル モデルを評価。 • ハードワイヤリング N-gram ヘッドにより、SlimPajama データセットの複雑さが 6.7% 改善されました。 | |||
| 2024-01-16 | コンテキスト内分類タスクにおけるデータ依存性と突然学習のメカニズムの基礎 | ||
| • この論文は、注意のみのネットワークにおける誘導ヘッドの突然の形成を介したコンテキスト内学習 (ICL) のメカニズムの基礎をモデル化しています。 • 簡素化された入力データと 2 層のアテンションベースのネットワークを使用して ICL タスクをシミュレートします。 • 誘導ヘッドの形成により、入れ子状の非線形性を通じて ICL への突然の移行が引き起こされます。 | |||
| 2024-01-16 | Transformer 言語モデルのタスク間での回路コンポーネントの再利用 | ||
| • この論文は、GPT-2 の特定の回路がさまざまなタスクにわたって一般化できることを実証し、そのような回路がタスク固有であるという概念に疑問を投げかけます。 • Colored Objects タスクの Indirect Object Identification (IOI) タスクからの回路の再利用を調べます。 • 4 つのアテンション ヘッドを調整すると、色付きオブジェクト タスクの精度が 49.6% から 93.7% に向上しました。 | |||
| 2024-01-16 | Successor Heads: 繰り返し発生する、解釈可能な注目のヘッド・イン・ザ・ワイルド | ||
| • この論文では、日数や数値などの自然な順序でトークンを増加させる LLM のアテンション ヘッドである「サクセサー ヘッド」を紹介しています。 • GPT-2 や Llama-2 など、さまざまなモデル サイズやアーキテクチャにわたる後継ヘッドの形成を分析します。 • 後継ヘッドは 31M から 12B パラメータの範囲のモデルにあり、抽象的で繰り返しの数値表現を明らかにします。 | |||
| 2024-01-16 | 大規模言語モデルの関数ベクトル | ||
| • この記事では、自己回帰変換モデル内のタスクのコンパクトな因果表現である「関数ベクトル (FV)」を紹介します。 • FV は、さまざまなインコンテキスト学習 (ICL) タスク、モデル、レイヤーにわたってテストされました。 • FV を合計して、新しい複雑なタスクをトリガーするベクトルを作成し、内部ベクトル構成を示すことができます。 | |||
| 日付 | 論文と概要 | タグ | リンク |
| 2023-12-23 | 事実調査: ニューロンレベルでの事実の想起をリバースエンジニアリングする試み | ||
| • Pythia 2.8B の初期の MLP 層が分散回路を使用して事実の再現をどのようにエンコードするかを、重ね合わせとマルチトークンの埋め込みに焦点を当てて調査しました。 • MLP レイヤーでの事実の検索を調査し、非トークン化とハッシュ メカニズムに関する仮説をテストしました。 • 事実の想起は、容易に解釈できる内部メカニズムを持たずに、分散ルックアップ テーブルのように機能します。 | |||
| 2023-11-07 | 解釈可能なシーケンスの継続に向けて: 大規模言語モデルにおける共有回路の分析 | ||
| • 同様のシーケンス継続タスク用の共有回路の存在を実証しました。 • アラビア数字、数字、月の増加シーケンスを含む、同様のシーケンス継続タスクの回路を分析および比較しました。 • 意味的に関連するシーケンスは、類似した役割を持つ共有回路サブグラフと、類似した機能を持つモデル間での類似したサブ回路の検索に依存します。 | |||
| 2023-10-23 | 大規模言語モデルにおける感情の線形表現 | ||
| • この論文は、大規模言語モデル (LLM) の感情表現を捉える活性化空間の直線方向を特定します。 • 彼らはこの感情の方向性を分離し、Stanford Sentiment Treebank などのタスクでテストしました。 • このセンチメントの方向性を除去すると、分類精度が 76% 低下し、その重要性が強調されます。 | |||
| 2023-10-06 | コピー抑制: アテンションヘッドを包括的に理解する | ||
| • この論文では、GPT-2 スモール アテンション ヘッド (L10H7) におけるコピー抑制の概念を紹介しています。これにより、単純なトークンのコピーが削減され、モデルのキャリブレーションが強化されます。 • この論文は、コピー抑制のメカニズムと自己修復におけるその役割を調査し、説明しています。 • GPT-2 Small における L10H7 の影響の 76.9% が説明されており、アテンション ヘッドの役割の最も包括的な説明となっています。 | |||
| 2023-09-22 | 推論時間介入: 言語モデルから真実の答えを引き出す | ||
| • 一部のアテンション ヘッドでモデルのアクティベーションを調整することにより、LLM の真実性を強化する推論時間介入 (ITI) を導入しました。 • TruthfulQA ベンチマークでの LLaMA モデルのパフォーマンスが向上しました。 • ITI は、Alpaca モデルの真実性を 32.5% から 65.1% に高めました。 | |||
| 2023-09-22 | トランスフォーマーの誕生: 記憶の視点 | ||
| • この論文は、重み行列の連想記憶とその勾配駆動学習に焦点を当て、変換器に関する記憶ベースの観点を示しています。 • 合成データを使用した単純化されたトランスフォーマー モデルでのトレーニング ダイナミクスの実証分析。 • 急速なグローバルバイグラム学習と、コンテキスト内バイグラムの「誘導ヘッド」の遅い出現の発見。 | |||
| 2023-09-13 | 損失の突然の低下: MLM における構文の習得、相転移、および単純性バイアス | ||
| • マスク言語モデル (MLM) で自然に出現するプロパティとしての構文的注意構造 (SAS) と、構文習得におけるその役割を特定します。 • トレーニング中に SAS を分析し、それを操作して文法能力に対する因果関係を研究します。 • SAS は文法の開発に必要ですが、これを一時的に抑制するとモデルのパフォーマンスが向上します。 | |||
| 2023-07-18 | 回路解析の解釈可能性は拡張可能ですか?チンチラの多肢選択能力の証拠 | ||
| • 多肢選択式質問応答を理解するために、70B チンチラ言語モデルに適用されたスケーラブルな回路解析。 • ロジット アトリビューション、アテンション パターンの視覚化、および主要なアテンション ヘッドを特定して分類するためのアクティベーション パッチ。 • アテンション ヘッドの「列挙型の N 番目の項目」機能を確認しました (部分的な説明にすぎません)。 | |||
| 2023-02-02 | 野生での解釈可能性: GPT-2 small の間接物体識別回路 | ||
| • この論文では、GPT-2 small が 7 つのクラスにグループ化された 28 個のアテンション ヘッドを含む大規模な回路を使用して間接オブジェクト識別 (IOI) を実行する方法について詳細に説明しています。 • 彼らは、因果関係のある介入と予測を使用して、GPT-2 Small の IOI タスクをリバース エンジニアリングしました。 • この研究は、大規模な言語モデルの機械的な解釈可能性が実現可能であることを示しています。 | |||
| 日付 | 論文と概要 | タグ | リンク |
| 2022-03-08 | コンテキスト内学習および誘導ヘッド | ||
| • この論文では、Transformer モデルの「誘導ヘッド」を特定しています。これにより、シーケンス内のパターンを認識してコピーすることで、コンテキスト内の学習が可能になります。 • さまざまな Transformer モデルのさまざまなレイヤーにわたる注意パターンと誘導ヘッドを分析します。 • Transformer がコンテキスト内の学習タスクを一般化して効果的に実行できるようにするには、誘導ヘッドが重要であることがわかりました。 | |||
| 2021-12-22 | 変圧器回路の数学的枠組み | ||
| • アテンションヘッドを独立した追加コンポーネントとして理解することに重点を置き、小さなアテンション専用トランスフォーマーをリバースエンジニアリングするための数学的フレームワークを導入します。 • 情報の移動と構成におけるアテンションヘッドの役割を特定するために、ゼロ層、1 層、および 2 層のトランスフォーマーを分析しました。 • 2 層変圧器でのコンテキスト学習に不可欠な「誘導ヘッド」を発見しました。 | |||
| 2021-05-18 | ヘッズ仮説: BERT における多頭注意の理解に向けた統一的な統計的アプローチ | ||
| • この論文は、重要なトークンに選択的に焦点を当てることによってアテンション メカニズムの計算の複雑さを軽減する、「スパース アテンション」と呼ばれる新しい方法を提案しています。 • この方法は、機械翻訳およびテキスト分類タスクに関して評価されました。 • 疎な注意モデルは、計算コストを大幅に削減しながら、密な注意と同等の精度を達成します。 | |||
| 2021-04-01 | BERT のアテンションヘッドは Constituency の文法を学習しましたか? | ||
| • この研究では、BERT および RoBERTa アテンション ヘッドの構成文法を分析するための構文距離法を導入しています。 • SMS および NLI タスクの微調整の前後で、構成文法が抽出および分析されました。 • NLI タスクは構成文法誘導能力を高めますが、SMS タスクは上位層でその能力を低下させます。 | |||
| 2019-11-27 | BERT のアテンション ヘッドは構文の依存関係を追跡しますか? | ||
| • この論文は、依存関係を抽出するためにアテンションの重みを使用して、BERT の個々のアテンション ヘッドが構文上の依存関係を捕捉するかどうかを調査します。 • 最大アテンション重みと最大スパニング ツリーを使用して BERT のアテンション ヘッドを分析し、ユニバーサル依存関係ツリーと比較しました。 • 一部のアテンション ヘッドは、ベースラインよりも特定の構文依存関係をより適切に追跡しますが、全体的な解析を大幅に適切に実行するヘッドはありません。 | |||
| 2019-11-01 | 適応的にまばらな変圧器 | ||
| •Alpha-Entmaxを使用して適応的にスパース変圧器を導入して、注意ヘッドに柔軟でコンテキスト依存性のスパース性を可能にしました。 •機械翻訳データセットに適用して、解釈可能性とヘッドの多様性を評価します。 •精度を損なうことなく、多様な注意分布と解釈可能性の向上を達成しました。 | |||
| 2019-08-01 | バートは何を見ていますか?バートの注意の分析 | ||
| •このペーパーでは、Bertの注意メカニズムを分析する方法を紹介し、構文や共同体などの言語構造に合わせたパターンを明らかにします。 •注意ヘッドの分析、構文およびコアフェファーシャルパターンの識別、および注意ベースのプロービング分類器の開発。 •Bertの注意ヘッドは、特に直接的なオブジェクトやコアファレンスの識別などのタスクで、かなりの構文情報をキャプチャします。 | |||
| 2019-07-01 | マルチヘッドの自己告発の分析:専門のヘッドは重い持ち上げを行い、残りは剪定することができます | ||
| •このペーパーでは、重大なパフォーマンスの損失なしに、それほど重要でないヘッドを選択的に除去する多目的自己関節のための新しい剪定方法を導入します。 •個々の注意ヘッドの分析、専門的な役割の識別、およびトランスモデルでの剪定方法の適用。 •エンコーダーの48頭のヘッドのうち38個が0.15 BLEUスコアドロップしかドロップしませんでした。 | |||
| 2018-11-01 | トランスベースの機械翻訳におけるエンコーダー表現の分析 | ||
| •このペーパーでは、自己関節ヘッドによって学んだ構文情報とセマンティック情報に焦点を当てた、変圧器エンコーダー層の内部表現を分析します。 •調査タスクの調査、依存関係抽出、および転送学習シナリオ。 •下層層は構文をキャプチャしますが、より高いレイヤーはより多くのセマンティック情報をエンコードします。 | |||
| 2016-03-21 | シーケンスからシーケンス学習にコピーメカニズムを組み込む | ||
| •コピーメカニズムをシーケンスからシーケンスモデルに導入して、入力トークンの直接コピーを可能にし、まれな単語の取り扱いを改善します。 •機械の翻訳および要約タスクに適用されます。 •標準のシーケンスからシーケンスモデルと比較して、特にまれな単語翻訳で、翻訳の精度が大幅に改善されました。 | |||
問題テンプレート:
Title: [paper's title]
Head: [head name1] (, [head name2] ...)
Published: [arXiv / ACL / ICLR / NIPS / ...]
Summary:
- Innovation:
- Tasks:
- Significant Result:


