AMRICA
1.0.0
AMRICA (AMR Inspector for Cross- language Alignments) は、二言語のコンテキストと単言語のアノテーター間合意の両方について、AMR を調整して視覚的に表現するためのシンプルなツールです (Banarescu、2013)。これは、AMR アノテーター間合意を識別するための Smatch システム (Cai、2012) に基づいており、これを拡張しています。
AMRICA を使用して、自分で編集またはコンパイルした手動アラインメントを視覚化することもできます (共通フラグを参照)。
github から Python ソースをダウンロードします。
pipがあることを前提としています。依存関係をインストールするには (下記のgraphviz 依存関係がすでにあると仮定して)、次を実行するだけです。
pip install argparse_config networkx==1.8 pygraphviz pynlpl
pygraphviz動作するには、graphviz が必要です。 Linux では、 graphviz libgraphviz-dev pkg-configインストールする必要がある場合があります。さらに、バイリンガル アライメント データを準備するには、GIZA++ と場合によっては JAMR が必要になります。
./disagree.py -i sample.amr -o sample_out_dir/
このコマンドはsample.amr内の AMR (空行で区切られている) を読み取り、graphviz ビジュアライゼーションを、 sample_out_dir/にある .png ファイルに置きます。
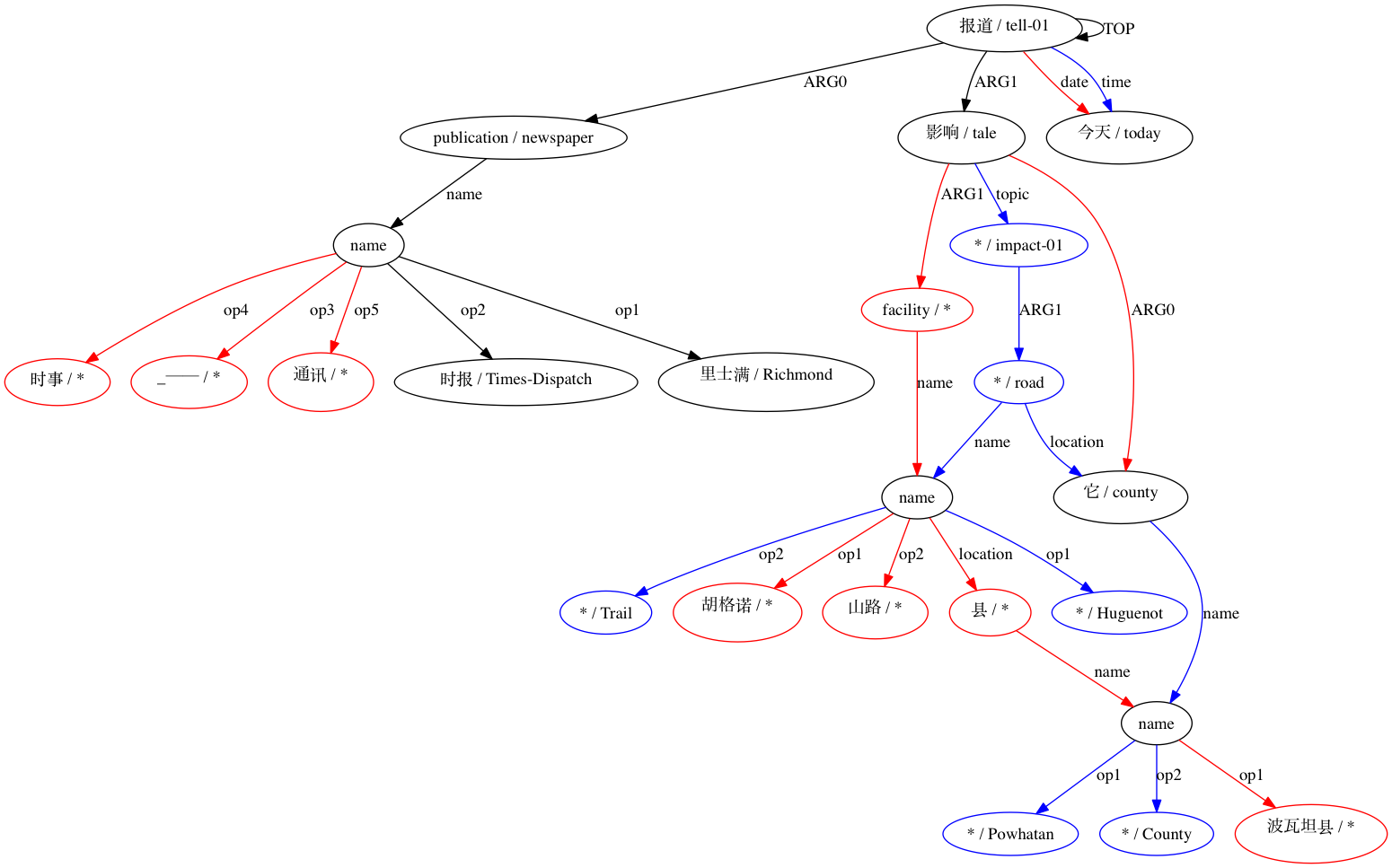
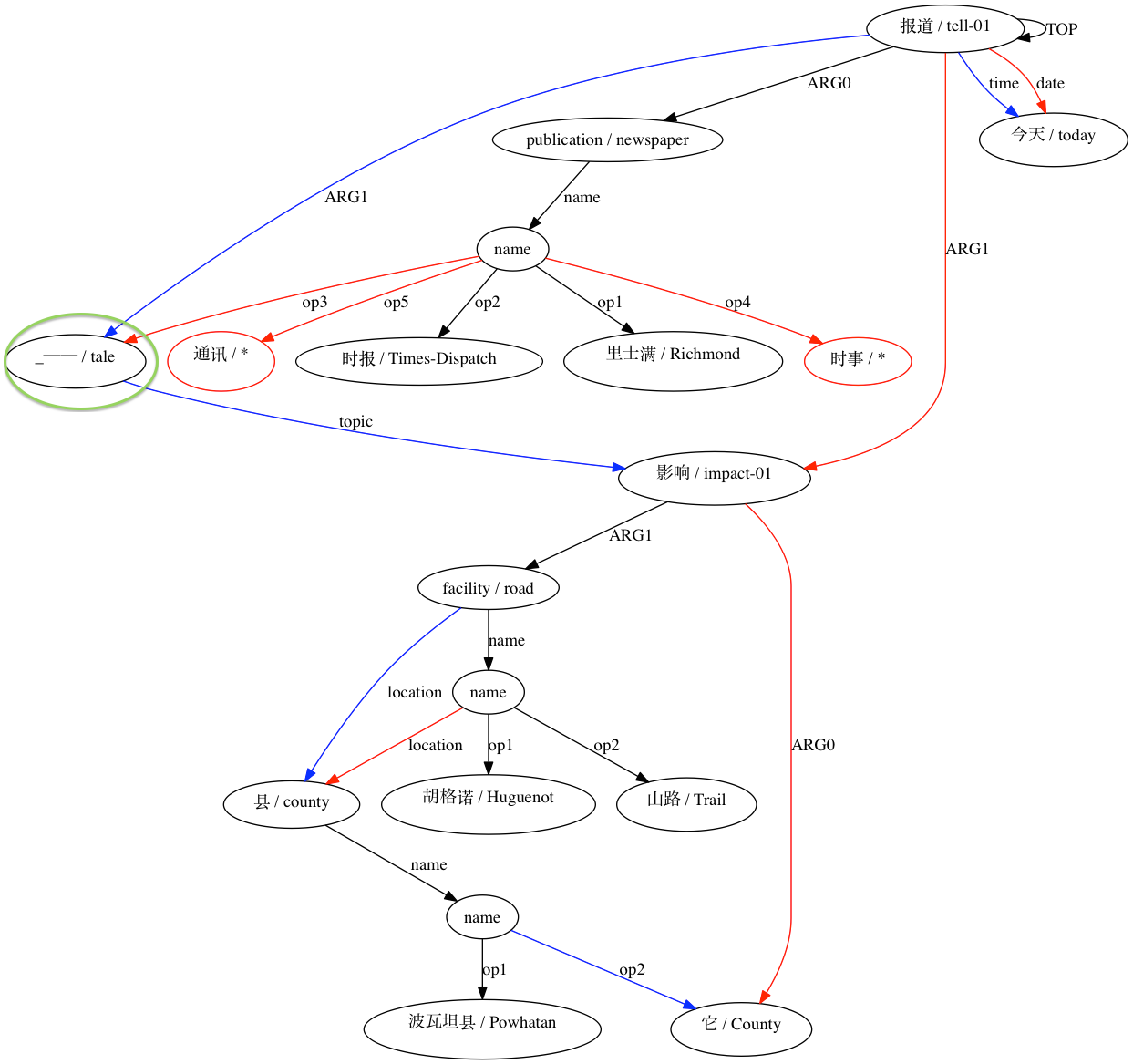
Smatch アライメントの視覚化を生成するには、トークン化された文を含む各::tokまたは::sntフィールド、文 ID を含む::idフィールド、およびアノテーター ID を含む::annotatorまたは::annoフィールドを含む AMR 入力ファイルが必要です。特定の文の注釈は順番にリストされ、最初の注釈が視覚化のゴールド スタンダードとみなされます。
アノテーター間の合意なしに文ごとに 1 つのアノテーションのみを視覚化したい場合は、1 つのアノテーターのみを含む AMR ファイルを使用できます。この場合、アノテーターとセンテンス ID フィールドはオプションです。結果のグラフはすべて黒になります。
バイリンガル アライメントの場合は、2 つの AMR ファイルから開始します。1 つはターゲット アノテーションを含み、もう 1 つはソース アノテーションを同じ順序で含み、各アノテーションに::tokと::idフィールドがあります。どちらかの側に JAMR アラインメントが必要な場合は、それらを::alignmentsフィールドに含めます。
文のアライメントは、ソース-ターゲットとターゲット-ソースの 2 つの GIZA++ アライメント .NBEST ファイルの形式である必要があります。これらを生成するには、GIZA++ 構成ファイル内の --nbestalignments フラグを使用して、希望の nbest カウントに設定します。
フラグはコマンドラインまたは構成ファイルで設定できます。構成ファイルの場所は、コマンド ラインで-c CONF_FILEを使用して設定できます。
--conf_fileに加えて、単言語テキストと二言語テキストの両方に適用されるフラグが他にもいくつかあります。 --outdir DIRのみが必須で、イメージ ファイルを書き込むディレクトリを指定します。
オプションの共有フラグは次のとおりです。
--verbose文を整列させながら出力します。--no-verbose詳細なデフォルト設定をオーバーライドします。--json FILE.jsonは、アライメント グラフを .json ファイルに書き込みます。--num_restarts N Smatch が実行するランダムな再起動の回数を指定します。--align_out FILE.csv使用して、アライメントをファイルに書き込みます。--align_in FILE.csvして、Smatch を実行する代わりにディスクからアライメントを読み取ります。--layout使用して、レイアウト パラメーターをgraphvizに変更します。アライメント .csv ファイルは、各グラフ一致セットが空行で区切られ、セット内の各行にコメントまたはアライメントを示す行が含まれる形式です。例えば:
3 它 - 1 it
2 多长 - -1
-1 - 2 take
タブで区切られたフィールドは、テスト ノード インデックス (Smatch によって処理される)、テスト ノード ラベル、ゴールド ノード インデックス、およびゴールド ノード ラベルです。
単一言語の配置には、追加のフラグ--infile FILE.amrが 1 つ必要ですFILE.amrは AMR ファイルの場所に設定されます。
以下は構成ファイルの例です。
[default]
infile: data/events_amr.txt
outdir: data/events_png/
json: data/events.json
verbose
二言語対応では、さらに必要なフラグがあります。
--src_amr FILE 。--tgt_amr FILE 。--align_tgt2src FILE.A3.NBESTターゲットとソースを調整する GIZA++ .NBEST ファイル (ターゲットを vcb1 とする)、 --nbestalignments Nで生成--align_src2tgt FILE.A3.NBESTソースとターゲットを位置合わせする GIZA++ .NBEST ファイル (ソースは vcb1)、 --nbestalignments Nで生成--nbestalignments Nが >1 に設定されている場合は、 --num_aligned_in_fileで指定する必要があります。上位だけを数えたい場合--num_align_readも設定します。
--nbestalignments 、最終的なアライメントの実行時にのみ生成されるため、使用するのが難しいフラグです。私自身、デフォルトの GIZA++ 設定でのみ動作させることができました。
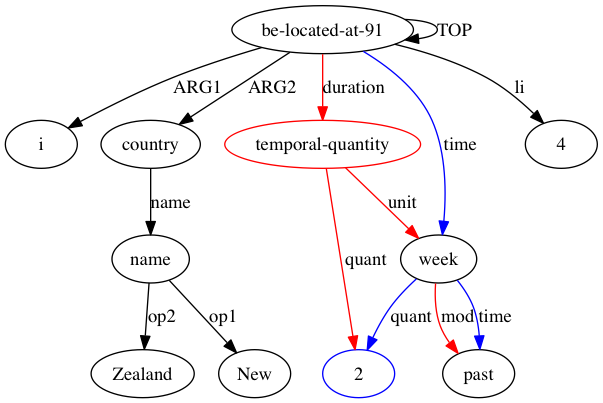
AMRICA は Smatch のバリエーションであるため、Smatch を理解することから始める必要があります。 Smatch は、アノテーター間の一致を測定するために、同じ文の 2 つの AMR 表現の変数ノード間の一致を識別しようとします。マッチングは、Smatch スコアを最大化するように選択する必要があります。Smatch スコアは、両方のグラフに表示される各エッジにポイントを割り当て、3 つのカテゴリに分類されます。各カテゴリは、次の「時間はかかりませんでした」という注釈で示されています。
(t / take-10
:ARG0 (i / it)
:ARG1 (l2 / long
:polarity -))
(instance, t, take-10)など(ARG0, t, i)などの変数-変数エッジ(polarity, l2, -)などの可変定数エッジSmatch スコアを最大化するマッチングを見つける問題は NP 完全であるため、Smatch は山登りアルゴリズムを使用して最適解を近似します。可能であれば、各ノードをそのラベルを共有するノードと照合し、小さい方のグラフ (以下、ターゲット) 内の残りのノードをランダムに照合することによってシードを行います。次に、Smatch は、2 つのターゲット ノードのマッチングを切り替えるか、マッチングをソース ノードから一致しないソース ノードに移動することにより、スコアを最も高めるアクションを見つけるステップを実行します。どのステップもすぐに Smatch スコアを増加できなくなるまで、このステップが繰り返されます。
局所最適化を回避するために、Smatch は通常 5 回再起動します。
AMRICA の内部動作に関する技術的な詳細については、NAACL デモ ペーパーを読む方が役立つかもしれません。
AMRICA は、すべての定数ノードを定数のラベルのインスタンスである変数ノードに置き換えることから始まります。これは、変数だけでなく定数ノードも整列できるようにするために必要です。したがって、AMRICA スコアに追加されるポイントは、変数間のエッジとインスタンス ラベルの一致によってのみ得られます。
Smatch は、小さいグラフ内のすべてのノードを大きいグラフ内のノードと照合しようとしますが、AMRICA は、修正された Smatch スコア、つまり AMRICA スコアを増加させないマッチングを削除します。
AMRICA は、線形の graphviz グラフから画像ファイルを生成します。ノードまたはエッジがゴールド データにのみ表示される場合、それは赤になります。そのノードまたはエッジがテスト データにのみ表示される場合は、青色になります。最終的な位置合わせでノードまたはエッジが一致する場合、それは黒になります。
AMRICA では、完全に一致するインスタンス ラベルごとに 1 ポイントを追加するのではなく、一致するラベルの尤度スコアに基づいてポイントを追加します。ターゲット ラベル セット Lt、ソース ラベル セット Ls、ターゲット センテンス Wt、ソース センテンス Ws、およびアライメント aLt,Ls[i] マッピング Lt[ i] をラベル Ls[aLt,Ls[i]] に適用すると、次のルールで定義される尤度から計算されます。
一般に、バイリンガル AMRICA が良好なパフォーマンスを発揮するには、モノリンガル AMRICA よりも多くのランダムな再起動が必要になるようです。この再起動回数は、 --num_restartsフラグを使用して変更できます。
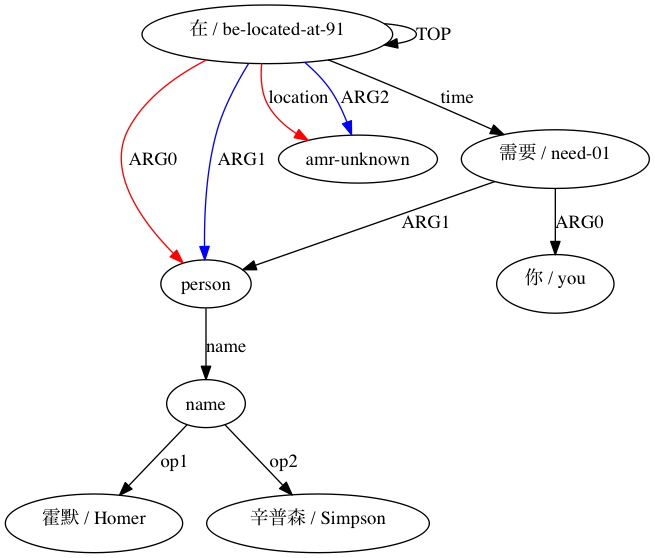
Smatch のような近似 (ここでは 20 個のランダムな初期化を使用) を使用すると、生のアライメント データから一致する可能性の高いものを選択する (スマート初期化) よりも精度がどの程度向上するかを観察できます。 (Xue 2014) によって構造的に互換性があると宣言されたペアリングの場合。
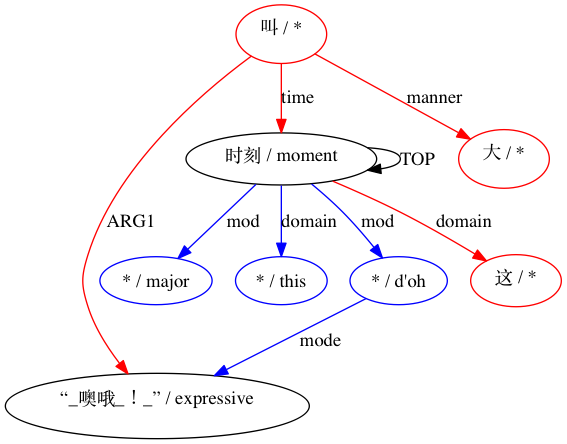
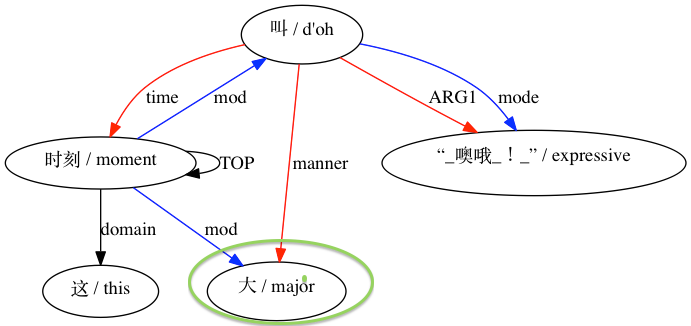
互換性がないとみなされるペアリングの場合:
このソフトウェアは、賞 1349902 および 0530118 に基づき、部分的に国立科学財団 (USA) の支援を受けて開発されました。エジンバラ大学は、登録番号 SC005336 でスコットランドに登録されている慈善団体です。


