gcp_cloud_status_dataset
1.0.0
これは、Google Cloud Service Health (CSH) イベントを含む単純な BigQuery データセットです。
これを使用してイベントをクエリし、関心のあるインシデントをフィルタリングすることができます。
毎分トリガーされます。既存の停止に対する更新がない場合、または新しい停止が検出されない場合、新しい行は挿入されません。
これを Asset Inventory API と併用して、特定の場所/地域のイベントと影響を受ける可能性のある資産を関連付けることもできます。
いずれにせよ、既存のCSHダッシュボードはRSSやJSONなどのさまざまな形式でデータを提供しますが、 jq使用して単純なクエリやフィルターを発行できます。
curl -s https://status.cloud.google.com/incidents.json | jq -r ' .[] | select(.service_name == "Google Compute Engine") 'ただし、使いやすい形式ではありません。
では、生の JSON の代わりに、あなたまたは誰でも使用できる BigQuery テーブルではどうでしょうか...
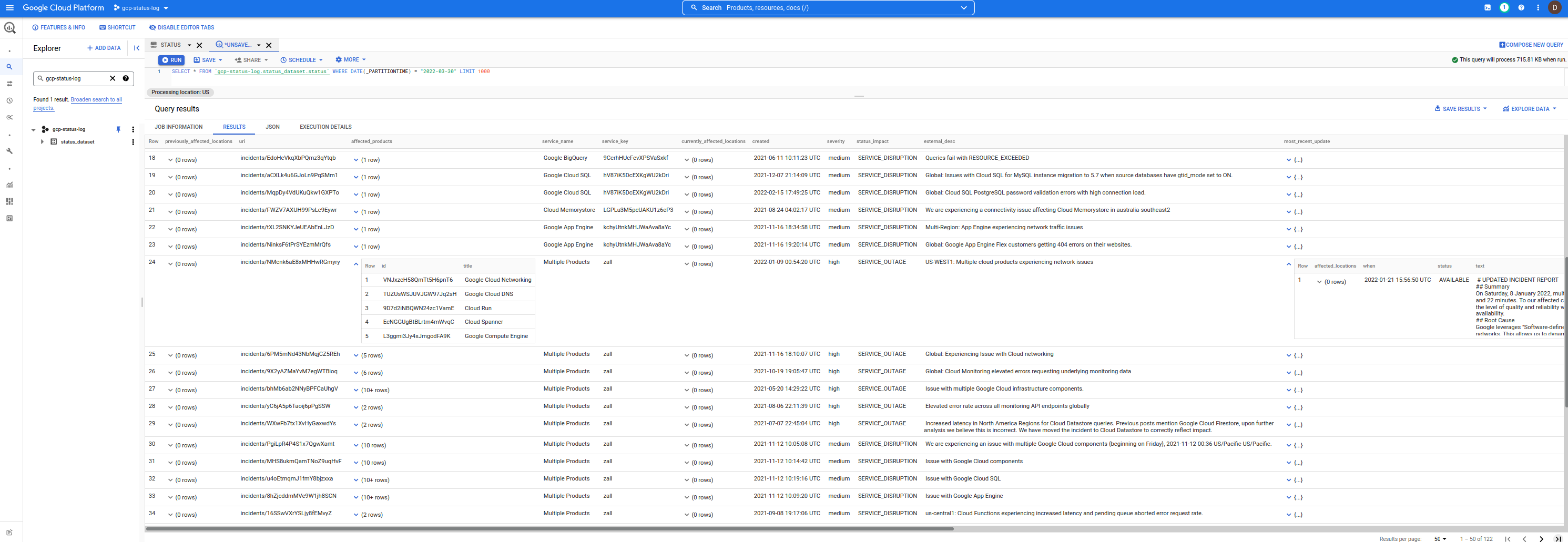
データセットは次のとおりです。
これを使用するには、まず次のプロジェクトを UI gcp-status-logに追加します。それが完了すると、発行するクエリはすべてこのデータセットを使用しますが、独自の使用量に対してプロジェクトに請求されます。 (つまり、私はデータを提供しているだけです...実行したクエリに対して料金が発生します)
注: このリポジトリ、データセット、コードは Google ではサポートされていません。警告のエンプター
bq query --nouse_legacy_sql '
SELECT
DISTINCT(id), service_name,severity,external_desc, begin,`end` , modified
FROM
gcp-status-log.status_dataset.status
WHERE
service_name = "Google Compute Engine"
ORDER BY
modified
'
+----------------------+-----------------------+----------+-----------------------------------------------------------------------------------------------------------------------------+---------------------+---------------------+---------------------+
| id | service_name | severity | external_desc | begin | end | modified |
+----------------------+-----------------------+----------+-----------------------------------------------------------------------------------------------------------------------------+---------------------+---------------------+---------------------+
| pxD6QciVMd9gLQGcREbV | Google Compute Engine | medium | Requests to and from Google Compute Instances in us-west2 may see increase traffic loss when using the instance's public IP | 2021-05-05 02:11:10 | 2021-05-05 04:54:57 | 2021-05-05 04:54:57 |
| LGFBxyLwbh92E47fAzJ5 | Google Compute Engine | medium | Mutliregional Price for E2 Free Tier core is set incorrectly | 2021-08-01 07:00:00 | 2021-08-04 23:18:00 | 2021-08-05 17:35:12 |
| gwKjX9Lukav15SaFPbBF | Google Compute Engine | medium | us-central1, europe-west1, us-west1, asia-east1: Issue with Local SSDs on Google Compute Engine. | 2021-09-01 02:35:00 | 2021-09-03 03:55:00 | 2021-09-07 21:39:46 |
| rjF86FbooET3FDpMV9w1 | Google Compute Engine | medium | Increased VM failure rates in a subset of Google Cloud zones | 2021-09-17 15:00:00 | 2021-09-17 18:25:00 | 2021-09-20 23:33:53 |
| ZoUf49v2qbJ9xRK63kaM | Google Compute Engine | medium | Some Users might have received credit cards deemed invalid email erroneously. | 2021-11-13 07:14:48 | 2021-11-13 08:29:30 | 2021-11-13 08:29:30 |
| SjJ3FN51MAEJy7cZmoss | Google Compute Engine | medium | Global: pubsub.googleapis.com autoscaling not worked as expected | 2021-12-07 09:56:00 | 2021-12-14 00:59:00 | 2021-12-14 19:59:08 |
+----------------------+-----------------------+----------+-----------------------------------------------------------------------------------------------------------------------------+---------------------+---------------------+---------------------+
...これが私の BQ スキルの限界です。あなたが書いた提案されたクエリがある場合は、github の問題にメモを送ってください。
ここで使用されるスキーマは、incidents.schema.json に示されているダッシュボードの JSON 出力で提供される形式とほぼ同じです。
唯一の違いは、上記で提供されたスキーマに従ってすべてのインシデントが単一の JSON にカプセル化されるのとは対照的に、BQ の各行が個別のインシデントであることです。
さらに、このスキーマには 2 つの新しい列があります。
insert_timestamp : これは、行/イベントが挿入されたときのTIMESTAMPです。snapshot_hash : これは、ダウンロードされたときのincident.jsonファイルの Base64 エンコードされたハッシュです。このリポジトリのサンプル スキーマを参照できます。
bq show --format=prettyjson --schema gcp-status-log:status_dataset.status
他の人は、次の組み合わせを使用してすべてを自分でセットアップできます。
Cloud Scheduler -> Cloud Run -> BigQUery以下の設定内容は次のとおりです。
Cloud Scheduler 1 分ごとにCloud Runサービスを安全に呼び出しますCloud Run 、最後に挿入されたJSON CSH ファイルのハッシュを保持するファイルを GCS バケットからダウンロードします。Cloud Run JSON CSH データをダウンロードして解析しますCloud Run CSH イベントをBigQueryに挿入しますもちろん、このスキームは、更新がない場合に同じハッシュ値を保持する JSON CSH ファイルに依存します (たとえば、独自の更新の鮮度タイムスタンプが含まれていません)。
export PROJECT_ID= ` gcloud config get-value core/project `
export PROJECT_NUMBER= ` gcloud projects describe $PROJECT_ID --format= ' value(projectNumber) ' `
gcloud services enable containerregistry.googleapis.com
run.googleapis.com
bigquery.googleapis.com
cloudscheduler.googleapis.com
storage.googleapis.com
# # create the datasets. We are using DAY partitioning
bq mk -d --data_location=US status_dataset
bq mk --table status_dataset.status schema.json
# # create service accounts for cloud run and scheduler
gcloud iam service-accounts create schedulerunner --project= $PROJECT_ID
gcloud iam service-accounts create cloudrunsvc --project= $PROJECT_ID
bq add-iam-policy-binding
--member=serviceAccount:cloudrunsvc@ $PROJECT_ID .iam.gserviceaccount.com
--role=roles/bigquery.admin status_dataset.status
gcloud projects add-iam-policy-binding $PROJECT_ID
--member= " serviceAccount:cloudrunsvc@ $PROJECT_ID .iam.gserviceaccount.com "
--role= " roles/bigquery.jobUser "
# create a gcs bucket to store hash of the incidents json file
# the first value of the hash will force a reload of the incidents.json file
gsutil mb -l us-central1 gs:// $PROJECT_ID -status-hash
echo -n " foo " > /tmp/hash.txt
gsutil cp /tmp/hash.txt gs:// $PROJECT_ID -status-hash/
gsutil iam ch serviceAccount:cloudrunsvc@ $PROJECT_ID .iam.gserviceaccount.com:roles/storage.admin gs:// $PROJECT_ID -status-hash/
# # you may also need to allow your users access to the dataset https://cloud.google.com/bigquery/docs/dataset-access-controls
# # build and deploy the cloud run image
docker build -t gcr.io/ $PROJECT_ID /gstatus .
docker push gcr.io/ $PROJECT_ID /gstatus
gcloud run deploy gcp-status --image gcr.io/ $PROJECT_ID /gstatus
--service-account cloudrunsvc@ $PROJECT_ID .iam.gserviceaccount.com
--set-env-vars " BQ_PROJECTID= $PROJECT_ID " --no-allow-unauthenticated
export RUN_URL= ` gcloud run services describe gcp-status --region=us-central1 --format= " value(status.address.url) " `
# # allow cloud scheduler to call cloud run
gcloud run services add-iam-policy-binding gcp-status --region=us-central1
--member=serviceAccount:schedulerunner@ $PROJECT_ID .iam.gserviceaccount.com --role=roles/run.invoker
# # deploy cloud scheduler
gcloud scheduler jobs create http status-scheduler- $region --http-method=GET --schedule " */5 * * * * "
--attempt-deadline=420s --time-zone= " Pacific/Tahiti " --location=us-central1
--oidc-service-account-email=schedulerunner@ $PROJECT_ID .iam.gserviceaccount.com
--oidc-token-audience= $RUN_URL --uri= $RUN_URL[5分待ちます]
また、bq イベントと資産インベントリ データを組み合わせて、イベントがサービスに影響を与えているかどうかを絞り込むことができます。
たとえば、GCE インスタンスに影響を与えるイベントがus-central1-aにあることがわかっている場合は、潜在的なアセットのリストを制限する検索クエリを発行できます。
$ gcloud organizations list
DISPLAY_NAME ID DIRECTORY_CUSTOMER_ID
esodemoapp2.com 673202286123 C023zwabc
$ gcloud asset search-all-resources --scope= ' organizations/673202286123 '
--query= " location:us-central1-a "
--asset-types= " compute.googleapis.com/Instance " --format= " value(name) "
//compute.googleapis.com/projects/in-perimeter-gcs/zones/us-central1-a/instances/in-perimeter
//compute.googleapis.com/projects/ingress-vpcsc/zones/us-central1-a/instances/ingress
//compute.googleapis.com/projects/fabled-ray-104117/zones/us-central1-a/instances/instance-1
//compute.googleapis.com/projects/fabled-ray-104117/zones/us-central1-a/instances/nginx-vm-1
//compute.googleapis.com/projects/clamav-241815/zones/us-central1-a/instances/instance-1
//compute.googleapis.com/projects/fabled-ray-104117/zones/us-central1-a/instances/windows-1
以下を使用して、世界中の IAM ロールと権限をクエリすることもできます。
ソース イベントは JSON であるため、JSON データ型の BQ ネイティブ サポートを使用して各イベントを BQ にロードすることもできます。
これは TODO であり、サンプル ワークフローは次のようになります。
export PROJECT_ID= ` gcloud config get-value core/project `
export PROJECT_NUMBER= ` gcloud projects describe $PROJECT_ID --format= ' value(projectNumber) ' `
bq mk --table status_dataset.json_dataset events:JSON
curl -o incidents.json -s https://status.cloud.google.com/incidents.json
cat incidents.json | jq -c ' .[] | . ' | sed ' s/"/""/g ' | awk ' { print """$0"""} ' - > items.json
bq load --source_format=CSV status_dataset.json_dataset items.json
bq show status_dataset.json_dataset
$ bq show status_dataset.json_dataset
Last modified Schema Total Rows Total Bytes Expiration Time Partitioning Clustered Fields Labels
----------------- ----------------- ------------ ------------- ------------ ------------------- ------------------ --------
08 Apr 09:39:48 | - events: json 125 822184 次に、クエリを行うために、各フィールドを直接参照できます。
$ bq query --nouse_legacy_sql '
SELECT events["id"] as id, events["number"] as number, events["begin"] as begin
FROM `status_dataset.json_dataset`
LIMIT 10
'
+------------------------+------------------------+-----------------------------+
| id | number | begin |
+------------------------+------------------------+-----------------------------+
| " ukkfXQc8CEeFZbSTYQi7 " | " 14166479295409213890 " | " 2022-03-31T19:15:00+00:00 " |
| " RmPhfQT9RDGwWLCXS2sC " | " 3617221773064871579 " | " 2022-03-31T18:07:00+00:00 " |
| " B1hD4KAtcxiyAWkcANfV " | " 17742360388109155603 " | " 2022-03-31T15:30:00+00:00 " |
| " 4rRjbE16mteQwUeXPZwi " | " 8134027662519725646 " | " 2022-03-29T21:00:00+00:00 " |
| " 2j8xsJMSyDhmgfJriGeR " | " 5259740469836333814 " | " 2022-03-28T22:30:00+00:00 " |
| " MtMwhU6SXrpBeg5peXqY " | " 17330021626924647123 " | " 2022-03-25T07:00:00+00:00 " |
| " R9vAbtGnhzo6n48SnqTj " | " 2948654908633925955 " | " 2022-03-22T22:30:00+00:00 " |
| " aA3kbJm5nwvVTKnYbrWM " | " 551739384385711524 " | " 2022-03-18T22:20:00+00:00 " |
| " LuGcJVjNTeC5Sb9pSJ9o " | " 5384612291846020564 " | " 2022-03-08T18:07:00+00:00 " |
| " Hko5cWSXxGSsxfiSpg4n " | " 6491961050454270833 " | " 2022-02-22T05:45:00+00:00 " |
+------------------------+------------------------+-----------------------------+
Cloud Run への対応する変更には、CSV 形式のロードの作成が含まれます( 4/8/22以降、CSV レガシー ローダーがサポートされているため)
var rlines [] string
for _ , event := range events {
event . InsertTimestamp = now
event . SnapshotHash = sha256Value
strEvent , err := json . Marshal ( event )
if err != nil {
fmt . Printf ( "Error Marshal Event %v" , err )
http . Error ( w , err . Error (), http . StatusInternalServerError )
return
}
// for JSON Datatype
// https://cloud.google.com/bigquery/docs/reference/standard-sql/json-data
line := strings . Replace ( string ( strEvent ), " " " , " " " " , - 1 )
line = fmt . Sprintf ( " " %s " " , line )
rlines = append ( rlines , line )
}
dataString := strings . Join ( rlines , " n " )
rolesSource := bigquery . NewReaderSource ( strings . NewReader ( dataString ))
rolesSource . SourceFormat = bigquery . CSVとにかく、JSON データ型は単なる TODO であり、現時点で必要かどうかはわかりません
なぜ私はスケジューラに再びタヒチの時間を選んだのでしょうか?
ぜひ、ご自身の目でご覧ください。