llmjudge
1.0.0
オープンエンドのシナリオで LLM を評価するのは難しく、既存のベンチマークには不足があり、経験豊富な実務者はモデル自体の雰囲気をチェックすることを好むというコンセンサスが高まっています。私は信頼する開発者や研究者からの事例評価に頼ってきましたが、Chatbot Arena はそれを補完する優れたものでした。このリポジトリの背後にある動機は、モデルの判定として強力な LLM を使用する方法がますます普及していることです。この方法は、JudgeLM などのモデル、そして最近では MT-Bench などのモデルで数か月前から使用されています。
このスレッドを見たことがあるかもしれませんし、見ていないかもしれません。 Arize AI のツイートの投稿者によると、LLM を審査員として使用する場合、特に数値スコア評価の使用に関してサーバーに注意を払う必要があるとのことです。 LLM は連続範囲の処理が非常に苦手であるようで、 X を1 から 10 まで評価するように指示すると、それがはっきりとわかります。このリポジトリは、この問題のギザギザの最前線を理解し、捉えようとする実験の生きた文書です。最近の研究では、MT-Bench と人間の判断 (Arena Elo) の間に強い相関関係が確立されました。これは、LLM が裁判官になることができることを意味します。では、ここで何が起こっているのでしょうか?
詳細と結果は以下のとおりです。
コストの制約のため、最初はツイートに記載されているスペル/スペルミスのタスクに焦点を当てます。このタスクの定量的な X がこの実験の洞察を汚染するのではないかと少し心配していますが、様子を見ましょう。私はこの現象のより本格的な分析を歓迎しますが、限られた実験であることを考えると、私の結果は割り引いて考える必要があります。
Paul Graham のエッセイから、どちらの名前がより適切であるかわかりませんが、スペルまたはスペルミスのデータセットを生成しました。以前にコンテキスト ウィンドウのプレッシャー テストを行うときにこのデータセットを使用したことがあったため、この選択は主に利便性によるものでした。エッセイから 3,000 語のコンテキストを抽出し、必要なスペルミス率に基づいてランダムな単語にスペルミスを挿入しました。疑似コードでは:
misspell_ratio
words = split context into words
misspell_count = calculate number of words to misspell based on ratio
FOR word = sample(words, misspell_count)
IF length(word) > 3
extract random character
ELSE:
add random character
END FOR
完全なコードはノートブックとしてすぐに入手できます。
生成されたデータセットを考慮して、LLM に、さまざまなスコアリング テンプレートを使用してコンテキスト内のスペルミスの単語の量を評価するよう促します。次の API を使用しています
GPT-4: gpt-4-0125-preview
GPT-3.5: gpt-3.5-turbo-1106
温度 = 0 の場合。
テスト 1. LLM がゼロショット設定で数値範囲を処理するのに苦労していることを確認しましょう。 GPT-3.5 と GPT-4 に対して、スコア 0 からスコア 10 までの数値スコア テンプレートを要求します。
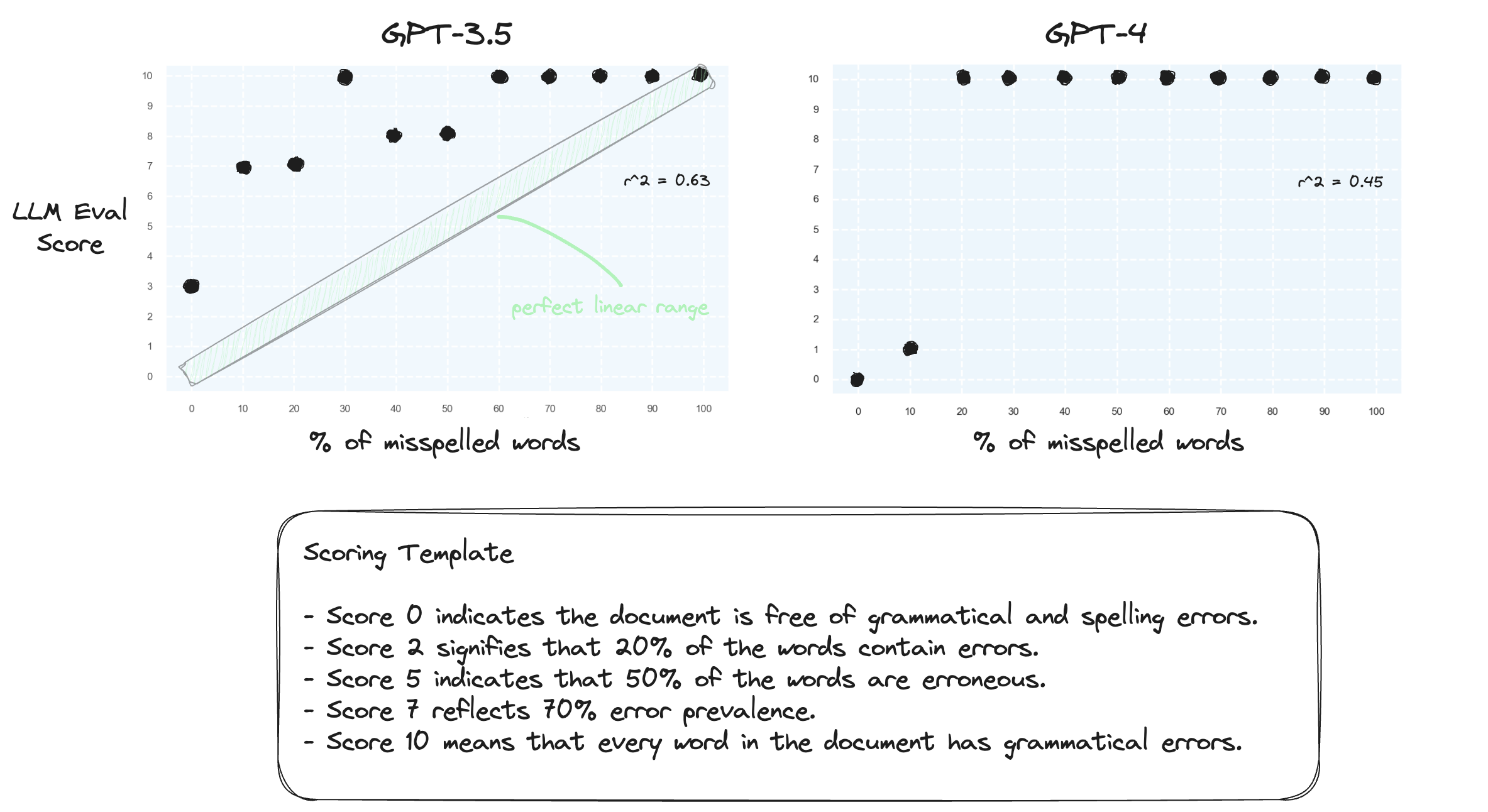
予想通り、両者とも重大な判断ミスをした。
テスト 2.得点範囲を逆にするとどうなるでしょうか?ここで、スコア 10 は、完全に綴られた文書を表します。
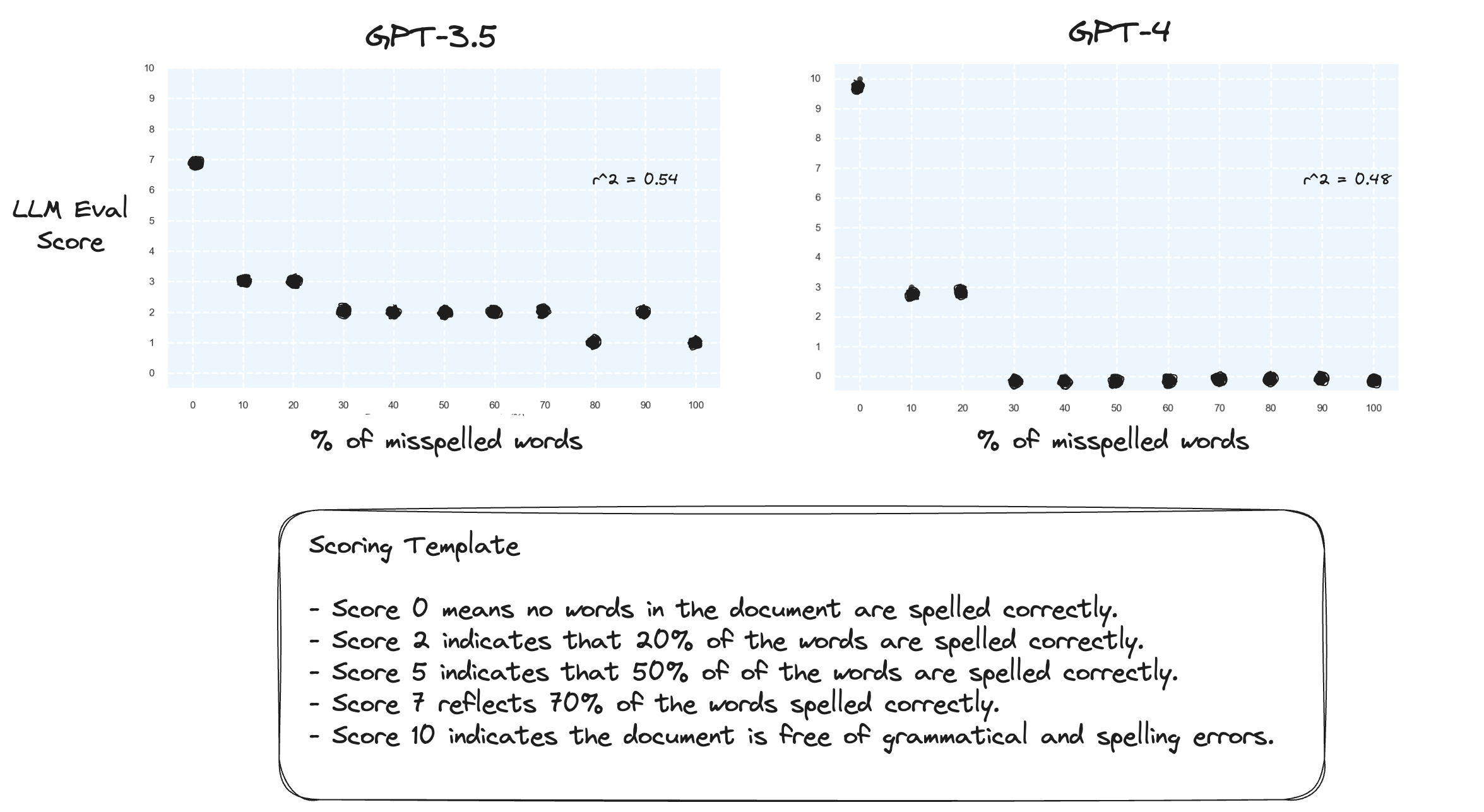
これには大きな違いはないようです。
テスト 3. Arize の仮説を信じるのであれば、採点ルーブリックを避け、代わりに「ラベル付き成績」を使用すれば改善が見られるかもしれません。この場合、5 段階評価スケールに下げることにしました。
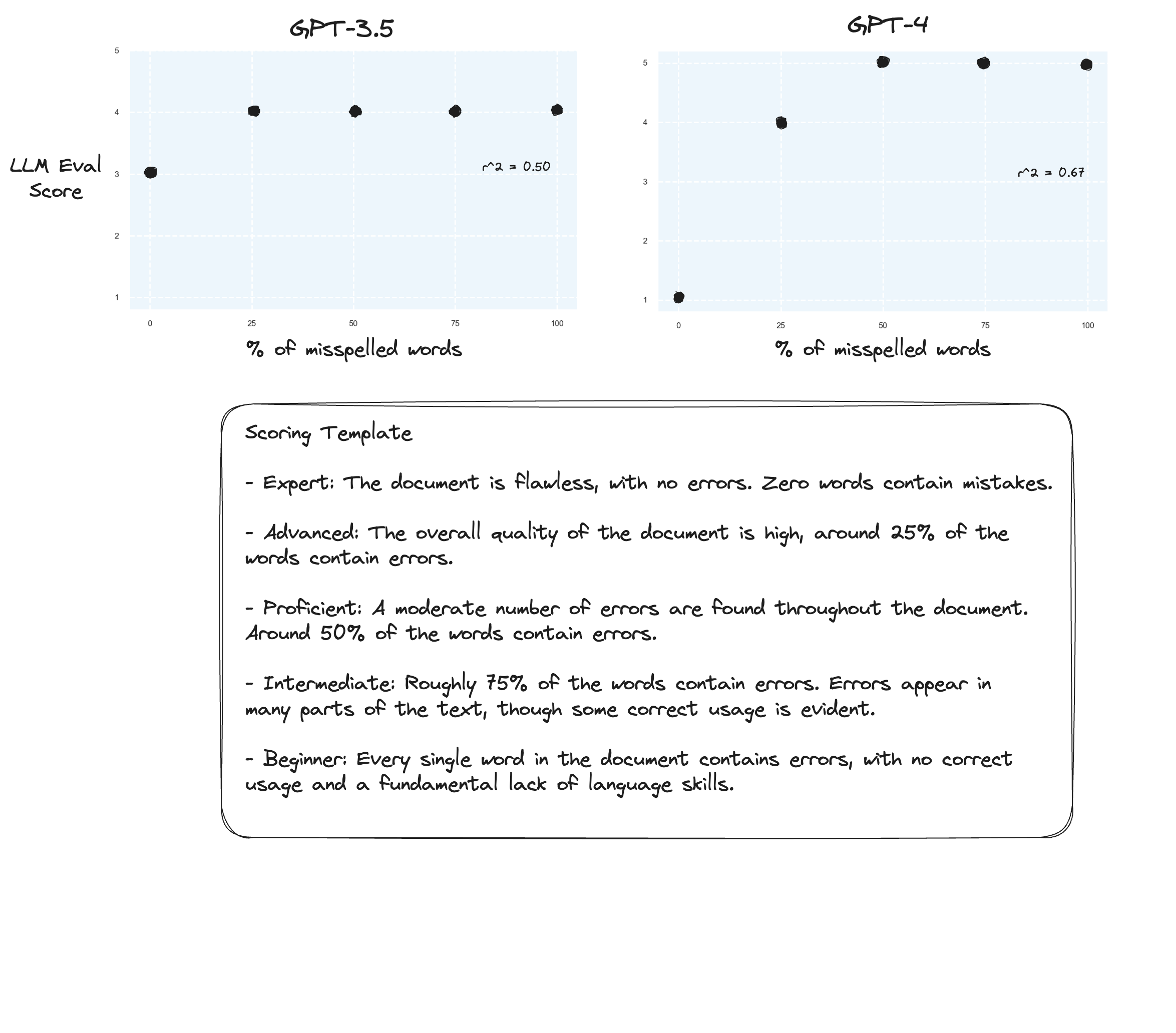
おそらくわずかな改善でしょうか?正直に言うのは難しいです。感動しません。
テスト 4.ゼロショットの思考連鎖はどうですか?

gpt-3.5 は、プロンプトのうち 2 つが意味不明なものになってしまいました。予想どおり、gpt-4 は、徹底的に考えるように促されると改善が見られます。スコアを 10 にするのが非常にためらわれていることに注目してください。
テスト 5.プロメテウスの著者が示唆したとおり。各スコアを独自の説明とマッピングすると、LLM の数値範囲全体にわたって採点する能力が向上する可能性があります。これを CoT と組み合わせると、次の結果が得られます。

gpt-4 の継続的な改善。境界スコア 0 と 10 を割り当てることは依然として非常に消極的です。
テスト 6. MT ベンチについて詳しく読んだ後、個別のスコアリングではなくペアごとの比較を使用する、別のアプローチをテストすることにしました。さて、通常、これには O(n * log N) の比較が必要ですが、順序はすでに分かっているので、最も困難なケースだけをテストしようと考えました。つまり、0% のスペルミスと 10% のスペルミス、10% と 20% の比較などです。合計 10 件の比較。ゼロショット CoT も使用していることに注目してください。
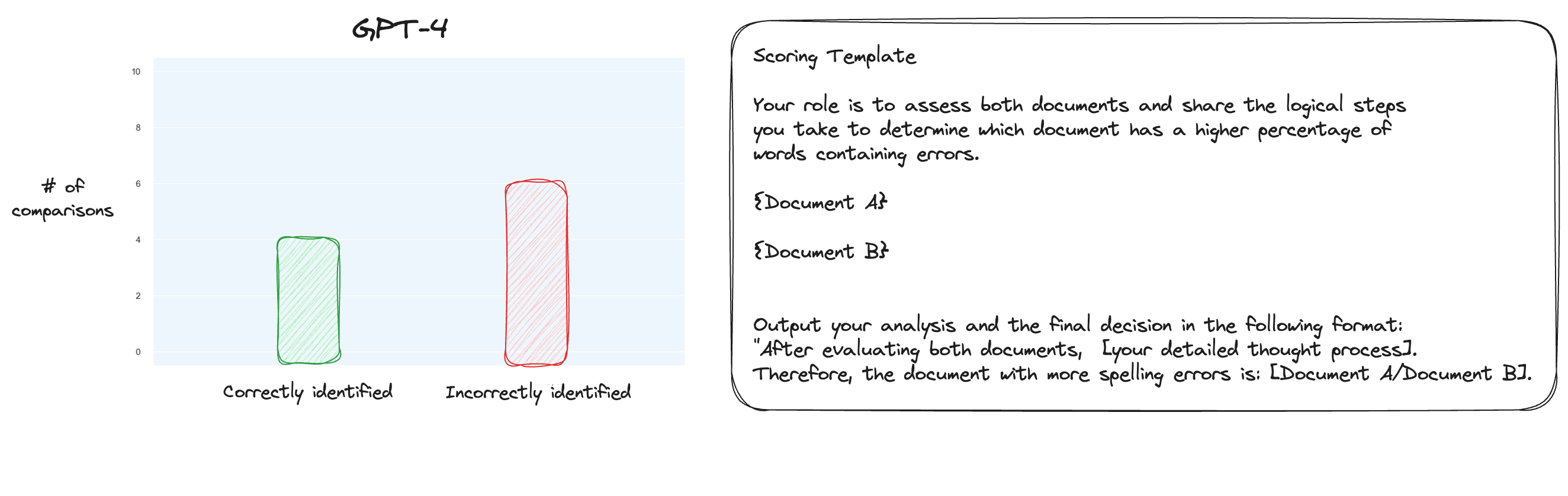
私の仮説は、コンテキスト ウィンドウ内の 2 つのテキストを比較するシナリオでは GPT-4 が優れているだろうというものでしたが、私は間違っていました。驚いたことに、これではまったく状況が改善されませんでした。確かに、これは考えられるすべての比較の中で最も難しいものですが、それでも全体としては簡単な作業です。おそらく、このタスクの定量的な側面は、LLM にとって本質的に非常に難しいものなのかもしれません。うーん、もっと良いプロキシ タスクを見つける必要があるかもしれません...
(31/1)私は MT-Bench の内部を調べてきましたが、MT-Bench が単純に GPT-4 に出力を 1 ~ 10 のスケールでスコア付けするように要求していることに気づき、非常に驚きました。ベースラインとのペアごとの比較などの代替グレーディング オプションも提供されますが、推奨されるオプションは数値オプションです。判断のプロンプトも予想外に単純です。
公平な裁判官として、以下に表示されるユーザーの質問に対する AI アシスタントの応答の質を評価してください。評価では、応答の有用性、関連性、正確性、深さ、創造性、詳細レベルなどの要素を考慮する必要があります。短い説明を入力して評価を開始します。できるだけ客観的になってください。説明を行った後、[評価] の形式に厳密に従って、1 から 10 のスケールで回答を評価する必要があります。たとえば、「評価: 5」です。 [質問] {question} [アシスタントの回答の開始] {answer} [アシスタントの回答の終了]
MT-Bench での判定がこれだけだと信じるのであれば、スペルミスタスクを代理タスクとして使用することに疑問を感じ始めます...
(2/2)私は GPT-4 に個別のスコアリングではなく、ペアごとの比較を通じてスペルミスのテキストを判断させることに熱心です。これは MT ベンチの代替判断方法の 1 つであり (ただし、独立したスコアリングを推奨しています)、このタスクにはこの方が適しているのではないかと思います。 CoT + 完全なマッピングの結果は間違いなく改善されていますが、まだやるべきことはあると思います。もちろん、ペアワイズ スコアリングの欠点は、(実際には) 完全なランキングを確立するために大幅に多くの API 呼び出しが必要になることです。


