DreamerGPT
1.0.0
 DreamerGPT: 中国語モデル命令の微調整
DreamerGPT: 中国語モデル命令の微調整DreamerGPT は、Xu Hao、Chi Huixuan、Bei Yuanchen、Liu Danyang によって開始された、中国語の大規模言語モデル命令微調整プロジェクトです。
英語版でお読みください。

 1. プロジェクト紹介
1. プロジェクト紹介このプロジェクトの目標は、より垂直な分野のシナリオで中国語の大規模言語モデルの適用を促進することです。
私たちの目標は、大きなモデルをより小さくし、誰もが自分の分野でトレーニングし、心理カウンセラー、コードアシスタント、パーソナルアシスタント、またはあなた自身の言語の家庭教師になることができる専門家アシスタントを支援することです。 DreamerGPT は、可能な限り最高の結果をもたらし、トレーニング コストを最小限に抑え、中国語向けにさらに最適化された言語モデルです。 DreamerGPT プロジェクトは、反復言語モデルのホットスタート トレーニング (LLaMa、BLOOM を含む)、指導トレーニング、強化学習、垂直フィールドの微調整を引き続き開拓し、信頼できるトレーニング データと評価ターゲットを反復し続けます。プロジェクトの人員とリソースが限られているため、現在の V0.1 バージョンは、LLaMa-7B および LLaMa-13B 用の中国語 LLaMa に最適化されており、中国語機能、言語調整、その他の機能が追加されています。現時点では、長い対話機能と論理的推論にまだ欠陥があります。さらなる反復計画については、次のバージョンのアップデートを参照してください。
以下は 8b に基づく量子化デモです (ビデオは高速化されていません)。現在、推論高速化とパフォーマンスの最適化も反復されています。
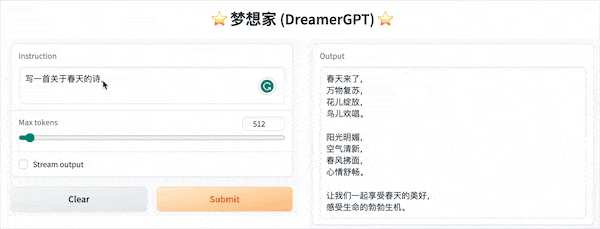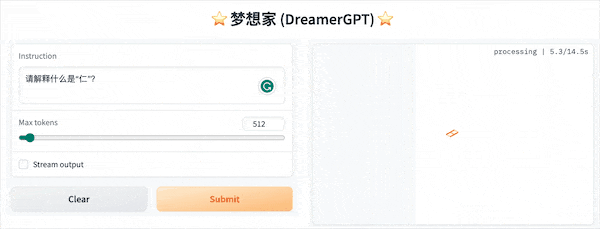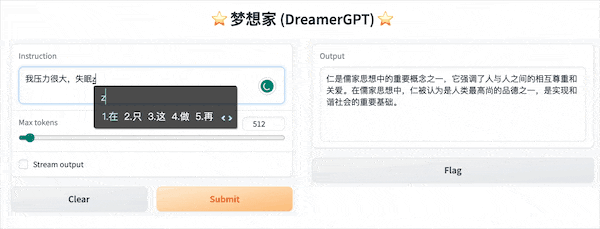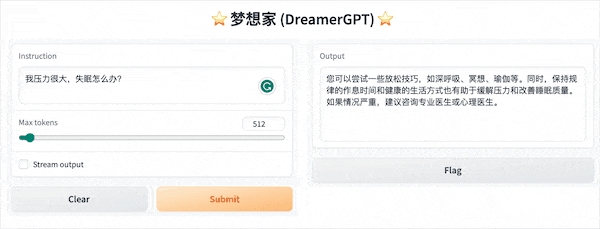
その他のデモ表示:
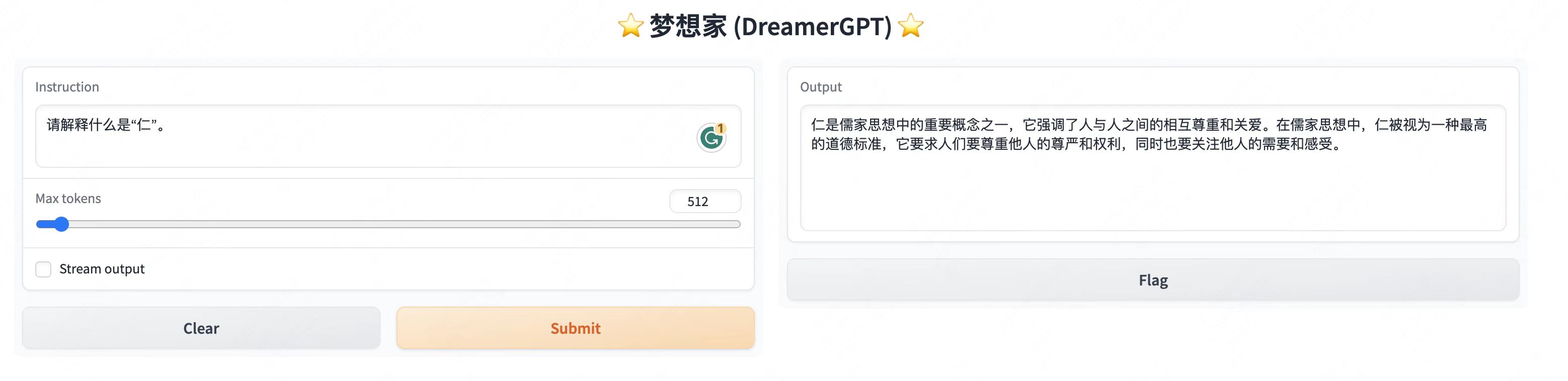

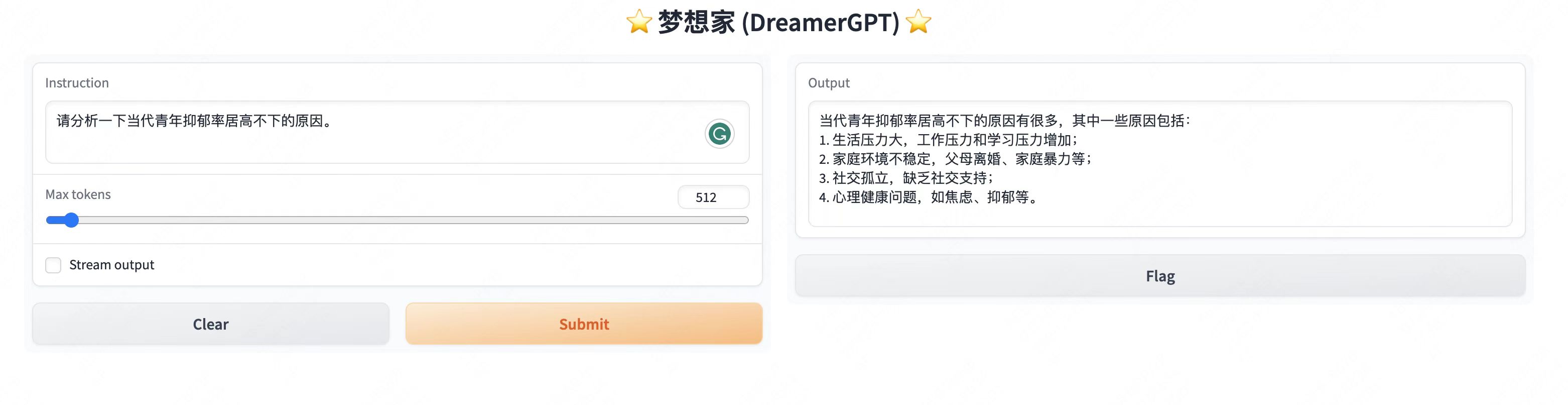
 2. 最新のアップデート
2. 最新のアップデート [2023/06/17] V0.2 バージョンを更新: LLaMa ホタル インクリメンタル トレーニング バージョン、BLOOM-LoRA バージョン (
[2023/06/17] V0.2 バージョンを更新: LLaMa ホタル インクリメンタル トレーニング バージョン、BLOOM-LoRA バージョン ( finetune_bloom.py 、 generate_bloom.py )。
[2023/04/23]正式にオープンソースの中国語コマンド微調整大型モデルDreamer (DreamerGPT) 、現在 V0.1 バージョンのダウンロード体験を提供中
既存のモデル (継続的な増分トレーニング、さらに多くのモデルが更新される):
| 機種名 | トレーニングデータ = | 重量のダウンロード |
|---|---|---|
| V0.2 | --- | --- |
| D13b-3-3 | D13b-2-3 + ホタルトレイン-1 | [ハグフェイス] |
| D7b-5-1 | D7b-4-1 + ホタルトレイン-1 | [ハグフェイス] |
| V0.1 | --- | --- |
| D13b-1-3-1 | Chinese-alpaca-lora-13b-hot start + COIG-part1、COIG-translate + PsyQA-5 | [Googleドライブ] [ハグフェイス] |
| D13b-2-2-2 | Chinese-alpaca-lora-13b-hot start + firefly-train-0 + COIG-part1、COIG-translate | [Googleドライブ] [ハグフェイス] |
| D13b-2-3 | Chinese-alpaca-lora-13b-hot start + firefly-train-0 + COIG-part1、COIG-translate + PsyQA-5 | [Googleドライブ] [ハグフェイス] |
| D7b-4-1 | Chinese-alpaca-lora-7b-hotstart+firefly-train-0 | [Googleドライブ] [ハグフェイス] |
モデル評価のプレビュー
 3. モデルとデータの準備
3. モデルとデータの準備モデル重量のダウンロード:
データは次の json 形式に均一に処理されます。
{
" instruction " : " ... " ,
" input " : " ... " ,
" output " : " ... "
}データのダウンロードと前処理スクリプト:
| データ | タイプ |
|---|---|
| アルパカ-GPT4 | 英語 |
| Firefly (複数のコピーに前処理、フォーマット調整) | 中国語 |
| コイグ | 中国語、コード、中国語、英語 |
| PsyQA (複数のコピーに前処理され、フォーマットが調整されています) | 中国の心理カウンセリング |
| ベル | 中国語 |
| ベーズ | 中国語会話 |
| カプレット (複数のコピーに前処理され、フォーマットが調整されています) | 中国語 |
注: データはオープン ソース コミュニティから取得されており、リンクを通じてアクセスできます。
 4. トレーニングコードとスクリプト
4. トレーニングコードとスクリプトコードとスクリプトの紹介:
finetune.py : ホット スタート/インクリメンタル トレーニング コードを微調整する手順generate.py : 推論/テストコードscripts/ : スクリプトを実行しますscripts/rerun-2-alpaca-13b-2.sh 。各パラメータの説明についてはscripts/README.md参照してください。  5. 使用方法
5. 使用方法詳細および関連する質問については、Alpaca-LoRA を参照してください。
pip install -r requirements.txtウェイトフュージョン (alpaca-lora-13b を例にします):
cd scripts/
bash merge-13b-alpaca.shパラメータの意味 (関連するパスを自分で変更してください):
--base_model 、ラマの元の体重--lora_model 、チャイニーズラマ/アルパカローラの体重--output_dir 、出力フュージョン ウェイトへのパス次のトレーニング プロセスを例として、実行中のスクリプトを示します。
| 始める | f1 | f2 | f3 |
|---|---|---|---|
| Chinese-alpaca-lora-13b-hot start、実験番号: 2 | データ: ホタルトレイン-0 | データ: COIG-part1、COIG-translate | データ: PsyQA-5 |
cd scripts/
# 热启动f1
bash run-2-alpaca-13b-1.sh
# 增量训练f2
bash rerun-2-alpaca-13b-2.sh
bash rerun-2-alpaca-13b-2-2.sh
# 增量训练f3
bash rerun-2-alpaca-13b-3.sh重要なパラメータの説明 (関連するパスは自分で変更してください):
--resume_from_checkpoint '前一次执行的LoRA权重路径'--train_on_inputs Falseを変更してください。--val_set_size 2000データ セット自体が比較的小さい場合は、500、200 など、適切に減らすことができます。推論のために微調整された重みを直接ダウンロードしたい場合は、5.3 を無視して 5.4 に直接進むことができることに注意してください。
たとえば、 rerun-2-alpaca-13b-2.shの微調整された結果を評価したいとします。
1. Web バージョンのインタラクション:
cd scripts/
bash generate-2-alpaca-13b-2.sh2. バッチ推論と結果の保存:
cd scripts/
bash save-generate-2-alpaca-13b-2.sh重要なパラメータの説明 (関連するパスは自分で変更してください):
--is_ui False : Web バージョンかどうか、デフォルトは True です--test_input_path 'xxx.json' : 入力命令パスtest.jsonに保存されます。  6. 評価報告書
6. 評価報告書現在、評価サンプルには 8 種類のテスト タスク (数値倫理と評価対象の Duolun ダイアログ) があり、各カテゴリには 10 個のサンプルがあり、 8 ビットの定量化バージョンは GPT-4/GPT 3.5 を呼び出すインターフェイスに従ってスコア付けされます (非定量化バージョンのスコアは高くなります)、各サンプルは 0 ~ 10 の範囲でスコア付けされます。評価サンプルについては、 test_data/参照してください。
以下是五个类似 ChatGPT 的系统的输出。请以 10 分制为每一项打分,并给出解释以证明您的分数。输出结果格式为:System 分数;System 解释。
Prompt:xxxx。
答案:
System1:xxxx。
System2:xxxx。
System3:xxxx。
System4:xxxx。
System5:xxxx。注: スコアは参考用です (GPT 3.5 と比較して) GPT 4 のスコアはより正確で参考になります。
| テストタスク | 詳細な例 | サンプル数 | D13b-1-3-1 | D13b-2-2-2 | D13b-2-3 | D7b-4-1 | チャットGPT |
|---|---|---|---|---|---|---|---|
| 各項目の合計スコア | --- | 80 | 100 | 100 | 100 | 100 | 100 |
| トリビア | 01qa.json | 10 | 80* | 78 | 78 | 68 | 95 |
| 翻訳する | 02翻訳.json | 10 | 77* | 77* | 77* | 64 | 86 |
| テキストの生成 | 03.json の生成 | 10 | 56 | 65* | 55 | 61 | 91 |
| 感情分析 | 04analyse.json | 10 | 91 | 91 | 91 | 88* | 88* |
| 読解 | 05理解.json | 10 | 74* | 74* | 74* | 76.5 | 96.5 |
| 中国人の特徴 | 06中国語.json | 10 | 69* | 69* | 69* | 43 | 86 |
| コード生成 | 07コード.json | 10 | 62* | 62* | 62* | 57 | 96 |
| 倫理、回答拒否 | 08アライメント.json | 10 | 87* | 87* | 87* | 71 | 95.5 |
| 数学的推論 | (評価対象) | -- | -- | -- | -- | -- | -- |
| 複数回の対話 | (評価対象) | -- | -- | -- | -- | -- | -- |
| テストタスク | 詳細な例 | サンプル数 | D13b-1-3-1 | D13b-2-2-2 | D13b-2-3 | D7b-4-1 | チャットGPT |
|---|---|---|---|---|---|---|---|
| 各項目の合計スコア | --- | 80 | 100 | 100 | 100 | 100 | 100 |
| トリビア | 01qa.json | 10 | 65 | 64 | 63 | 67* | 89 |
| 翻訳する | 02翻訳.json | 10 | 79 | 81 | 82 | 89* | 91 |
| テキストの生成 | 03.json の生成 | 10 | 65 | 73* | 63 | 71 | 92 |
| 感情分析 | 04analyse.json | 10 | 88* | 91 | 88* | 85 | 71 |
| 読解 | 05理解.json | 10 | 75 | 77 | 76 | 85* | 91 |
| 中国人の特徴 | 06中国語.json | 10 | 82* | 83 | 82* | 40 | 68 |
| コード生成 | 07コード.json | 10 | 72 | 74 | 75* | 73 | 96 |
| 倫理、回答拒否 | 08アライメント.json | 10 | 71* | 70 | 67 | 71* | 94 |
| 数学的推論 | (評価対象) | -- | -- | -- | -- | -- | -- |
| 複数回の対話 | (評価対象) | -- | -- | -- | -- | -- | -- |
全体として、このモデルは翻訳、感情分析、読解などにおいて優れたパフォーマンスを発揮します。
2 人が手動で採点し、平均をとりました。
| テストタスク | 詳細な例 | サンプル数 | D13b-1-3-1 | D13b-2-2-2 | D13b-2-3 | D7b-4-1 | チャットGPT |
|---|---|---|---|---|---|---|---|
| 各項目の合計スコア | --- | 80 | 100 | 100 | 100 | 100 | 100 |
| トリビア | 01qa.json | 10 | 83* | 82 | 82 | 69.75 | 96.25 |
| 翻訳する | 02翻訳.json | 10 | 76.5* | 76.5* | 76.5* | 62.5 | 84 |
| テキストの生成 | 03.json の生成 | 10 | 44 | 51.5* | 43 | 47 | 81.5 |
| 感情分析 | 04analyse.json | 10 | 89* | 89* | 89* | 85.5 | 91 |
| 読解 | 05理解.json | 10 | 69* | 69* | 69* | 75.75 | 96 |
| 中国人の特徴 | 06中国語.json | 10 | 55* | 55* | 55* | 37.5 | 87.5 |
| コード生成 | 07コード.json | 10 | 61.5* | 61.5* | 61.5* | 57 | 88.5 |
| 倫理、回答拒否 | 08アライメント.json | 10 | 84* | 84* | 84* | 70 | 95.5 |
| 数値倫理 | (評価対象) | -- | -- | -- | -- | -- | -- |
| 複数回の対話 | (評価対象) | -- | -- | -- | -- | -- | -- |
 7. 次回バージョンアップ内容
7. 次回バージョンアップ内容TODOリスト:
 制限事項、使用制限および免責事項
制限事項、使用制限および免責事項現在のデータと基本モデルに基づいてトレーニングされた SFT モデルには、有効性の点で次のような問題がまだあります。
事実に基づく指示は、事実に反する誤った回答につながる可能性があります。
有害な指示を適切に特定できず、差別的、有害、非倫理的な発言につながる可能性があります。
推論、コーディング、複数ラウンドの対話などを含む一部のシナリオでは、モデルの機能をまだ改善する必要があります。
上記モデルの制限に基づき、本プロジェクトのコンテンツおよび本プロジェクトによって生成される派生作品は学術研究目的にのみ使用することができ、商業目的や社会に害を及ぼす用途には使用してはならないとしています。プロジェクト開発者は、このプロジェクト (データ、モデル、コードなどを含むがこれらに限定されない) の使用によって生じるいかなる損害、損失、または法的責任も負いません。
 引用
引用このプロジェクトのコード、データ、モデルを使用する場合は、このプロジェクトを引用してください。
@misc{DreamerGPT,
author = {Hao Xu, Huixuan Chi, Yuanchen Bei and Danyang Liu},
title = {DreamerGPT: Chinese Instruction-tuning for Large Language Model.},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/DreamerGPT/DreamerGPT}},
}
 お問い合わせ
お問い合わせこのプロジェクトにはまだ不十分な点がたくさんあります。ご提案やご質問をお聞かせください。このプロジェクトを改善するために最善を尽くします。
メール: [email protected]


