datalens
1.0.0
これは、LLM を使用して、ユーザー定義の基準に基づいて非構造化ジョブ データをランク付けする個人的な実験です。従来の求人検索プラットフォームは厳格なフィルタリング システムに依存していますが、多くのユーザーにはそのような具体的な基準がありません。 Datalens を使用すると、より自然な方法で好みを定義し、関連性に基づいて各求人情報を評価できます。
一部の基準は他の基準よりも重要である可能性があるため、「必須基準」は通常の基準の 2 倍の重みが付けられます。
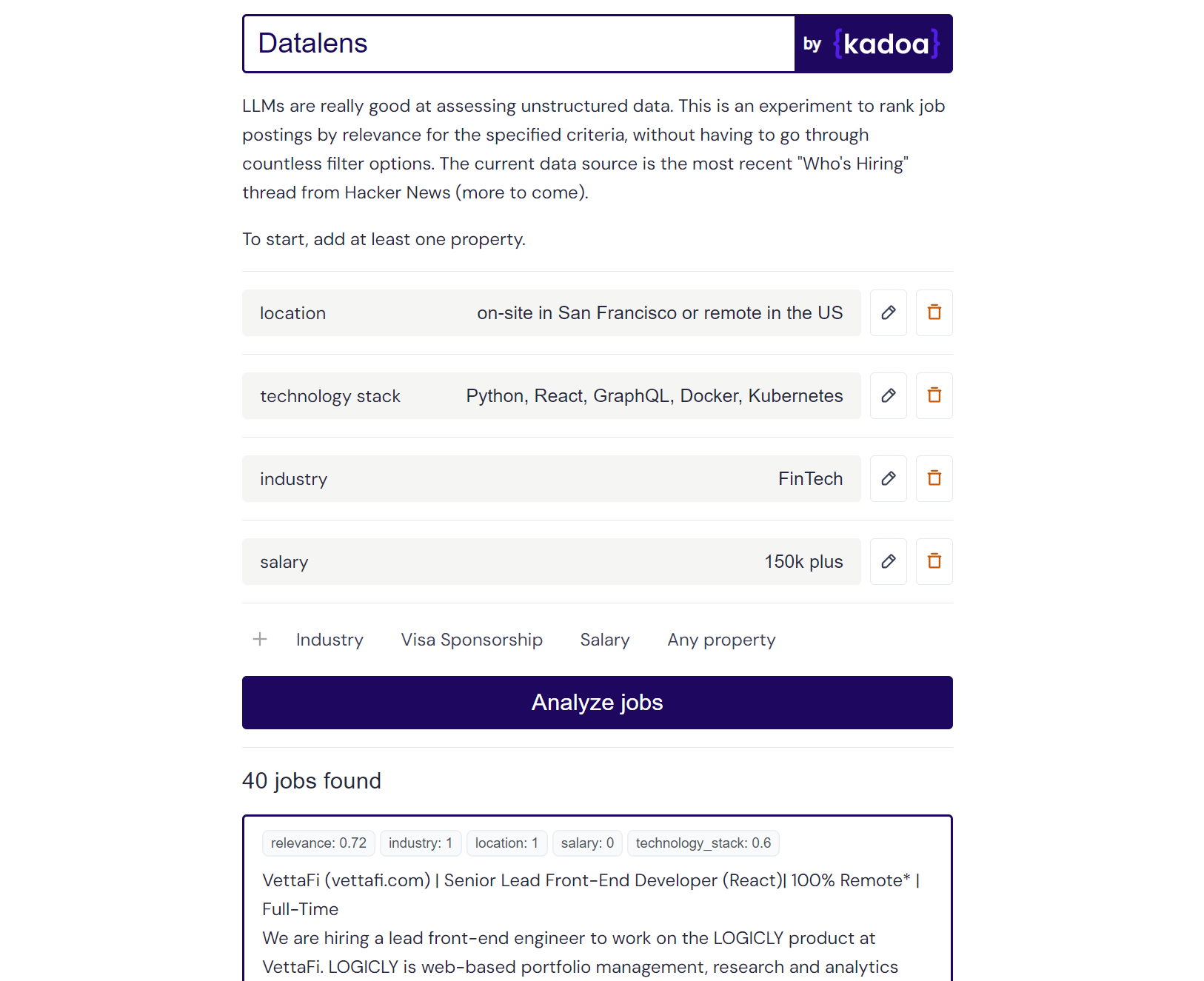
クロード 2 の結果の例:
Here are the scores for the provided job posting:
{
"location": 1.0,
"technology_stack": 0.8,
"industry": 0.0,
"salary": 0.0
}
Explanation:
- Location is a perfect match (1.0) as the role is in San Francisco which meets the "on-site in San Francisco or remote in the US" criteria.
- Technology stack is a partial match (0.8) as Python, React, and Kubernetes are listed which meet some but not all of the specified technologies.
- Industry is no match (0.0) as the company is in the creative/AI space.
- Salary is no match (0.0) as the posting does not mention the salary range. However, the full compensation is variable. Assigned a score of 0.6.
任意のジョブ データ ソースを追加できます。 Hacker News の最新の「Who's Hiring」スレッドを使用して事前設定しましたが、独自のソースを追加することもできます。
sources_config.json を更新して、新しいジョブ ソースを追加します。例:
{
"name": "SourceName",
"endpoint": "API_ENDPOINT",
"handler": "handler_function_name",
"headers": {
"x-api-key": "YOUR_API_KEY"
}
}
私は独自のツール Kadoa を使用して会社のページから求人データを取得しましたが、他の従来のスクレイピング方法を使用することもできます。
これらの企業からすべての求人情報を取得するための既製のパブリック エンドポイントをいくつか示します (毎日更新)。
{
"name": "Anduril",
"endpoint": "https://services.kadoa.com/jobs/pages/64e74d936addab49669d6319?format=json",
"handler": "fetch_kadoa_data",
"headers": {
"x-api-key": "00000000-0000-0000-0000-000000000000"
}
},
{
"name": "Tesla",
"endpoint": "https://services.kadoa.com/jobs/pages/64eb63f6b91574b2149c0cae?format=json",
"handler": "fetch_kadoa_data",
"headers": {
"x-api-key": "00000000-0000-0000-0000-000000000000"
}
},
{
"name": "SpaceX",
"endpoint": "https://services.kadoa.com/jobs/pages/64eb5f1b7350bf774df35f7f?format=json",
"handler": "fetch_kadoa_data",
"headers": {
"x-api-key": "00000000-0000-0000-0000-000000000000"
}
}
他の会社を追加する必要があるかどうか教えてください。また、Kadoa への試用アクセスも喜んで提供します。
関連性スコアリングは、0 ~ 1 の間の詳細なスコアを返すgpt-4-0613で最も効果的に機能します。 claude-2 にアクセスできる場合は、 claude-2も非常にうまく機能します。 gpt-3.5-turbo-0613も使用できますが、条件に対して 0 または 1 のバイナリ スコアが返されることが多く、部分一致と完全一致を区別するニュアンスが不足しています。
コスト上の理由から、デフォルトのモデルはgpt-3.5-turbo-0613です。 use_claudeをuse_openaiに置き換えることで、GPT から Claude に切り替えることができます。
このスクリプトを継続的に実行すると、API の使用率が高くなる可能性があるため、責任を持って使用してください。各 GPT 通話のコストを記録しています。
アプリを実行するには、次のものが必要です。
.env.example ファイルをコピーして必要事項を入力します。
Flask サーバーを実行します。
cd server
cp .env.example .env
pip install -r requirements.txt
py main
クライアント ディレクトリに移動し、ノードの依存関係をインストールします。
cd client
npm install
Next.js クライアントを実行します。
cd client
npm run dev


