ShapeGPT
1.0.0

プロジェクト ページ • Arxiv Paper • デモ • FAQ • 引用
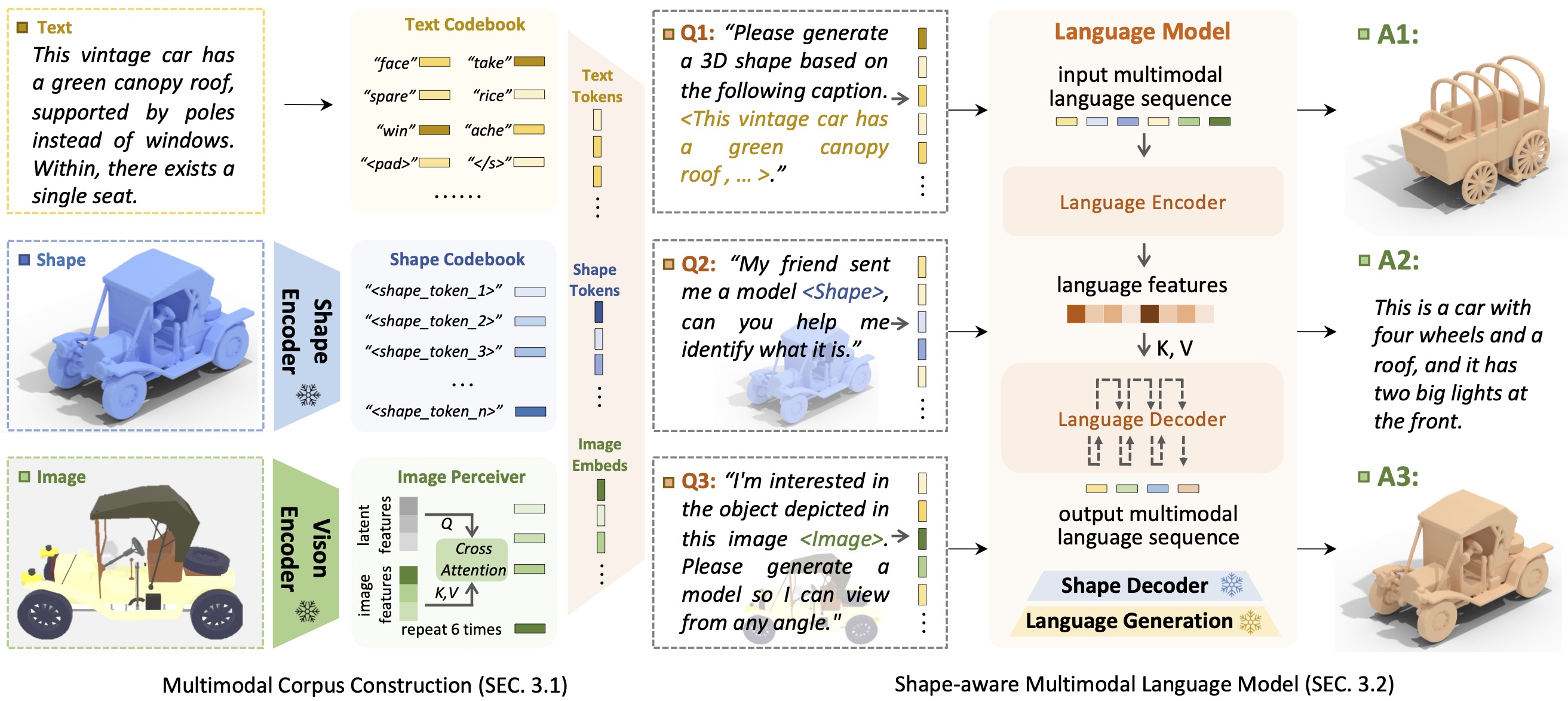
イントロシェイプGPTShapeGPT は、マルチモーダル コーパスを確立し、複数の形状タスクで形状認識型言語モデルを開発するための、統合されたユーザー フレンドリーな形状中心のマルチモーダル言語モデルです。
命令駆動型アプローチによる柔軟性を可能にする大規模言語モデルの出現により、多くの従来の生成タスクに革命が起きましたが、3D データの大規模モデル、特に他のモダリティで 3D 形状を包括的に処理する場合は、まだ研究が進んでいません。命令ベースの形状生成を実現することにより、多用途のマルチモーダル生成形状モデルは、3D 仮想構築やネットワーク支援設計などのさまざまな分野に大きな利益をもたらします。この研究では、強力な事前トレーニング済み言語モデルを活用して複数の形状関連タスクに対処する、形状が組み込まれたマルチモーダル フレームワークである ShapeGPT を紹介します。具体的には、ShapeGPT は単語-文-段落フレームワークを採用して、連続図形を図形単語に離散化し、さらにこれらの単語を組み立てて図形文を作成し、さらに図形をマルチモーダル段落の説明テキストと統合します。この形状言語モデルを学習するには、形状表現、マルチモーダル アライメント、命令ベースの生成を含む 3 段階のトレーニング スキームを使用して、形状言語コードブックを調整し、これらのモダリティ間の複雑な相関関係を学習します。広範な実験により、ShapeGPT が、テキストからシェイプへ、シェイプからテキストへ、シェイプ補完、シェイプ編集などのシェイプ関連タスク全体で同等のパフォーマンスを達成することが実証されています。
私たちのコードや論文が役立つと思われる場合は、以下を引用することを検討してください。
@misc { yin2023shapegpt ,
title = { ShapeGPT: 3D Shape Generation with A Unified Multi-modal Language Model } ,
author = { Fukun Yin and Xin Chen and Chi Zhang and Biao Jiang and Zibo Zhao and Jiayuan Fan and Gang Yu and Taihao Li and Tao Chen } ,
year = { 2023 } ,
eprint = { 2311.17618 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}
T5 モデル、Motion-GPT、Perceiver-IO、SDFusion のおかげで、私たちのコードは部分的にそれらから借用しています。私たちのアプローチは、Unified-IO、Michelangelo、ShapeCrafter、Pix2Vox、および 3DShape2VecSet からインスピレーションを得ています。
このコードは MIT LICENSE に基づいて配布されます。
私たちのコードは PyTorch3D や PyTorch Lightning などの他のライブラリに依存しており、それぞれに従う必要がある独自のライセンスを持つデータセットを使用していることに注意してください。


