Darwin
1.0.0
組織: ニューサウスウェールズ大学(UNSW) AI4Science & GreenDynamics AI
Darwin は、科学文献やデータセットに基づく LLaMA モデルの事前トレーニングと微調整に特化したオープンソース プロジェクトです。材料科学、化学、物理学に重点を置いた科学分野向けに特別に設計されたダーウィンは、構造化科学知識と非構造化科学知識を統合して、科学研究における言語モデルの有効性を高めます。
使用およびライセンスに関する通知: Darwin はライセンスを取得しており、研究用途のみを目的としています。データセットは CC BY NC 4.0 に基づいてライセンスされており、非営利使用が許可されています。このデータセットを使用してトレーニングされたモデルは、研究目的以外には使用しないでください。重量差も CC BY NC 4.0 ライセンスに基づいています
[2024.11.20]
主な成果
モデルのパフォーマンスに関する洞察
データ戦略と洞察
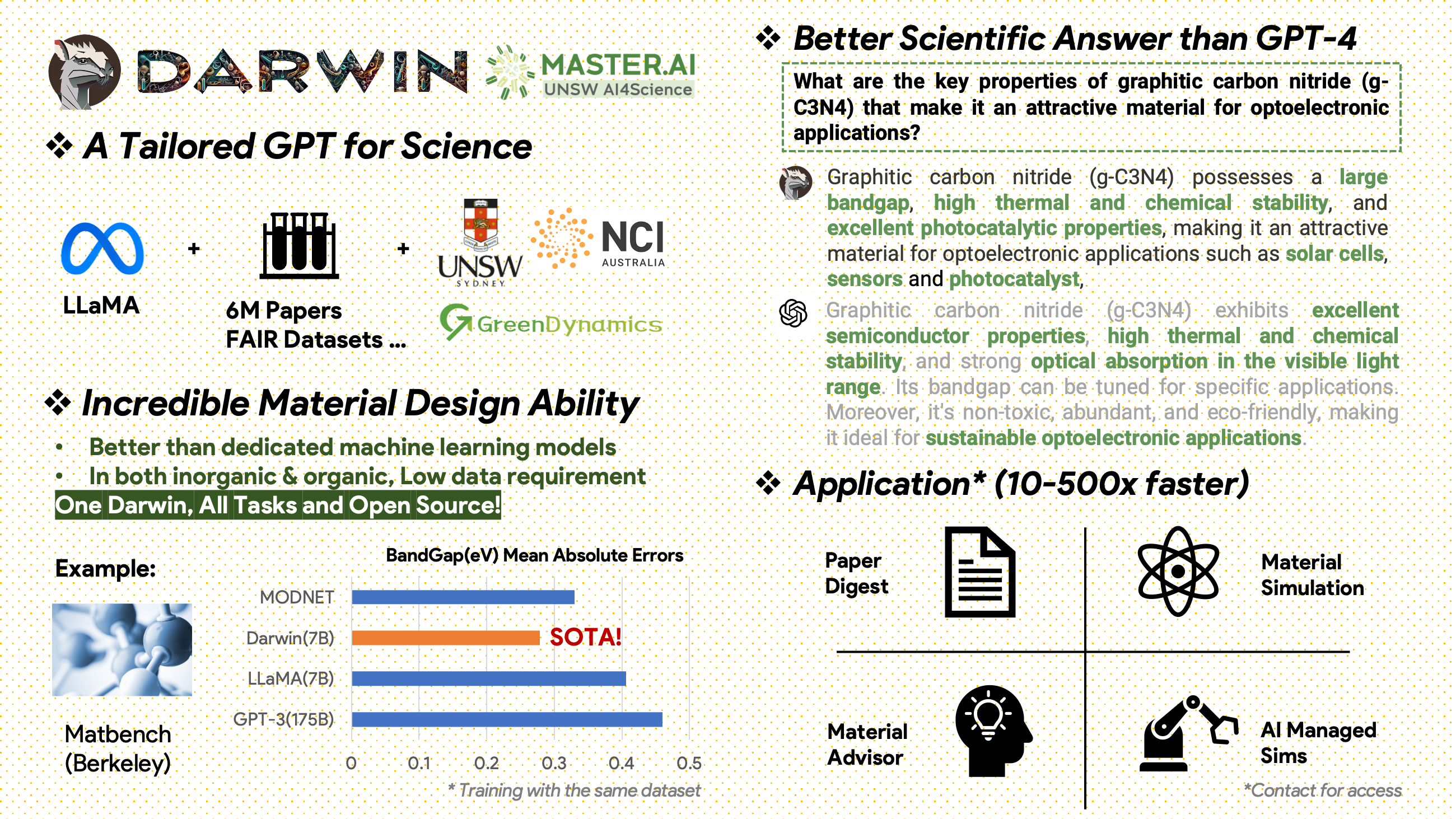
[2024.02.15] Materials Projects による MatBench の SOTA: DARWIN は、実験的なバンドギャップ予測タスクおよび金属分類タスクにおける SOTA モデルであり、微調整された GPT3.5 および専用の ML モデルよりも優れています。 https://matbench.materialsproject.org/Leaderboards%20Per-Task/matbench_v0.1_matbench_expt_gap/
☆ [2023.09.15]Google Colab バージョンが利用可能になりました: Google Colab で DARWIN をお試しください: inference.ipynb
Darwin は 7B LLaMA モデルに基づいており、さまざまな科学 FAIR データセットおよび文献コーパスから Darwin Scientific struction Generator (SIG) によって生成された 100,000 を超える命令に従うデータ ポイントでトレーニングされます。ダーウィンは、モデルの応答の事実の正しさに焦点を当てることで、科学的発見に大規模言語モデル (LLM) を活用することに向けて大きく前進しました。人間による予備評価では、ダーウィン 7B は科学的な Q&A では GPT-4 を上回り、化学問題 (gptChem など) の解決では微調整された GPT-3 を上回っていることが示されています。
私たちは、より高度な科学分野の実験のために Darwin を積極的に開発しており、より複雑な科学タスク (パーソナル コンピューターのプライベート 研究アシスタントなど) を解決するために Darwin と LangChain を統合しています。
Darwin はまだ開発中であるため、多くの制限に対処する必要があることに注意してください。最も重要なことは、安全性を最大限に高めるためにダーウィンをまだ微調整していないことです。モデルの安全性と倫理的考慮事項を改善するために、懸念のある行動を報告することをユーザーに推奨します。
デモリンク
まず要件をインストールします。
pip install -r requirements.txtDarwin-7B ウェイトのチェックポイントを onedrive からダウンロードします。モデルをダウンロードしたら、デモを試すことができます。
python inference.py < your path to darwin-7b >推論には、Darwin 7B に対して少なくとも 10GB の GPU メモリが必要であることに注意してください。
さまざまなデータセットを使用して Darwin-7b をさらに微調整するために、4 つの A100 80G GPU を搭載したマシンで動作するコマンドを以下に示します。
torchrun --nproc_per_node=8 --master_port=1212 train.py
--model_name_or_path < your path to darwin-7b >
--data_path < your path to dataset >
--bf16 True
--output_dir < your output dir >
--num_train_epochs 3
--per_device_train_batch_size 1
--per_device_eval_batch_size 1
--gradient_accumulation_steps 1
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 500
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 1
--fsdp " full_shard auto_wrap "
--fsdp_transformer_layer_cls_to_wrap ' LlamaDecoderLayer '
--tf32 False私たちのデータは 2 つの主要なソースから取得されています。
材料科学、化学、物理学に関する 600 万件の論文を含む未加工文献コーパスが 2000 年以降に出版されました。出版社には、ACS、RSC、Springer Nature、Wiley、Elsevier が含まれます。彼らのサポートに感謝します。
FAIR データセット - 16 の FAIR データセットからデータを収集しました。
私たちは科学的な指示を生成するために Darwin-SIG を開発しました。文献全文の長文(平均約 5000 ワード)を記憶し、科学文献のキーワード( Web of Science API から)に基づいて質疑応答(Q&A)データを生成できます。
注: GPT3.5 または GPT-4 を生成に使用することもできますが、これらのオプションはコストがかかる可能性があります。
発行者との契約により、トレーニング データセットを共有できないことにご注意ください。
このプロジェクトは以下の方々による共同作業です。
UNSW & GreenDynamics: Tong Xie、Shaozhou Wang
UNSW: イムラン・ラザク、コディ・ファン
USYD & DARE センター: クララ・グラツィアン
GreenDynamics: Yuwei Wan、Yixuan Liu
UNSW Engineering の Bram Hoex と Wenjie Zhang がすべてにアドバイスをしました。
このリポジトリのデータまたはコードを仕事で使用する場合は、それに応じて引用してください。
DAWRIN の基礎的な大規模言語モデルと半自己指示による微調整
@misc{xie2023darwin,
title={DARWIN Series: Domain Specific Large Language Models for Natural Science},
author={Tong Xie and Yuwei Wan and Wei Huang and Zhenyu Yin and Yixuan Liu and Shaozhou Wang and Qingyuan Linghu and Chunyu Kit and Clara Grazian and Wenjie Zhang and Imran Razzak and Bram Hoex},
year={2023},
eprint={2308.13565},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
マテリアルディスカバリ用に微調整された GPT-3 と LLaMA (シングルタスクトレーニング)
@article{xie2023large,
title={Large Language Models as Master Key: Unlocking the Secrets of Materials Science},
author={Xie, Tong and Wan, Yuwei and Zhou, Yufei and Huang, Wei and Liu, Yixuan and Linghu, Qingyuan and Wang, Shaozhou and Kit, Chunyu and Grazian, Clara and Zhang, Wenjie and others},
journal={Available at SSRN 4534137},
year={2023}
}
このプロジェクトは、次のオープンソース プロジェクトを参照しています。
NCI Australia の HPC サポートに心より感謝いたします。
私たちは Darwin の開発チームを継続的に拡大しています。 AI を使用して科学研究を推進するこのエキサイティングな旅に参加してください。
PhD または PostDoc のポジションについては、詳細について [email protected] または [email protected] までお問い合わせください。
他のポジションについては、www.greendynamics.com.au をご覧ください。


