GPT_subtitles
1.0.0
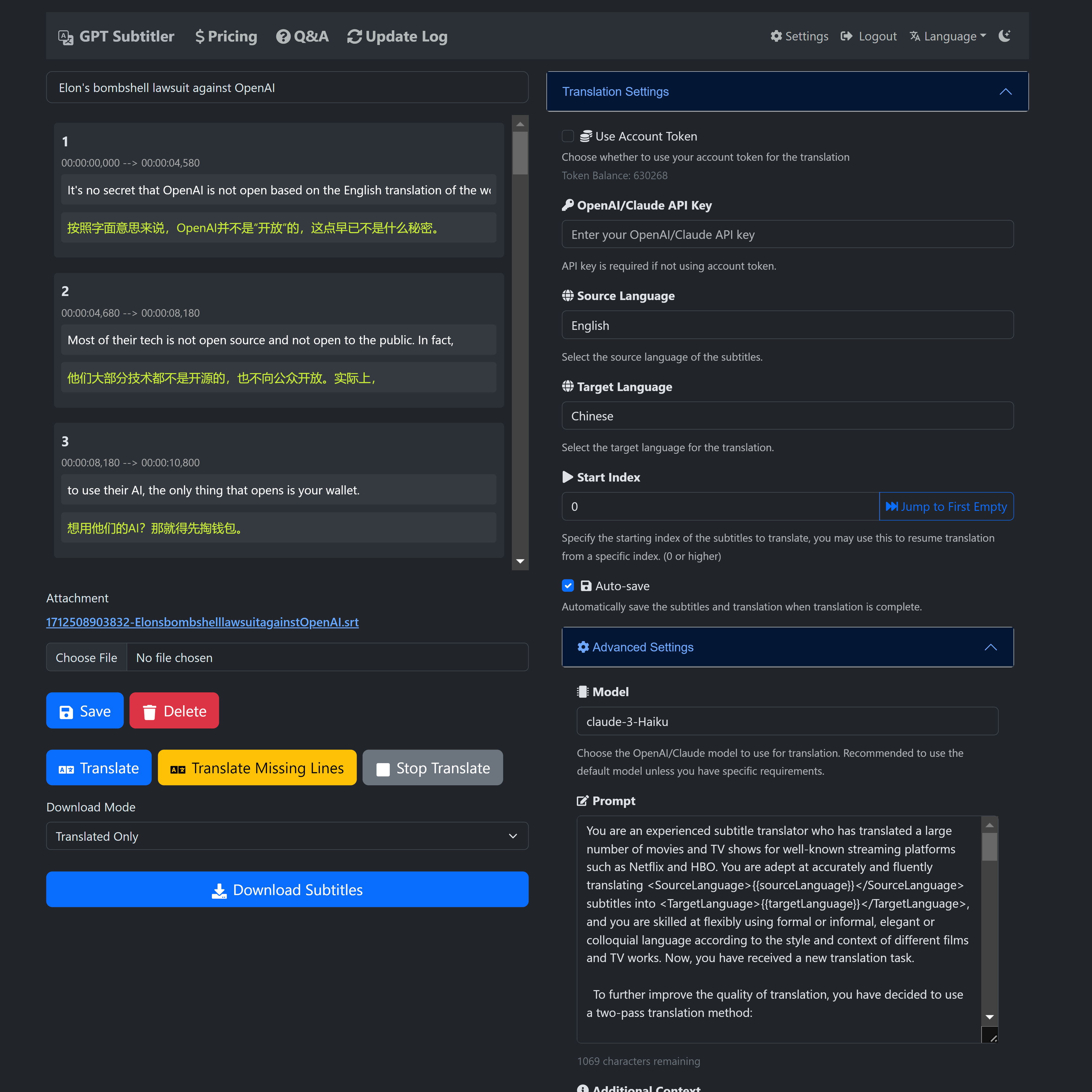
? GPT Subtitler は、このプロジェクトからインスピレーションを得た Web アプリケーションであり、多くの強力な機能を備えています。
Anthropic Claude、GPT-3.5、GPT-4などの多彩な機種を使用した高品質な字幕翻訳に対応。現時点では、 Claude-Haikuモデルが推奨されています。
さらに、Claude-Haiku モデルほど正確ではない可能性がありますが、 Gemini-1.5-flashおよびGemini-1.5-proモデルはユーザーが無料で試すことができます。
?新規ユーザーは登録時に 100,000 個の無料トークンを受け取ります。これは 20 分間のビデオ字幕を無料で翻訳するのに十分な量です。
?無料のトークンは毎日請求でき、トークンは低価格で購入することもできます。 AI 翻訳を使用するために API キーは必要ありません。
?翻訳結果のリアルタイム プレビュー、編集プロンプト、少数ショットの例のサポート、いつでも翻訳を停止して任意の位置から再開できる機能。翻訳後、複数の SRT 字幕ファイル形式をエクスポートできます (翻訳 + オリジナルまたはオリジナル + 翻訳の二か国語字幕)。
このウェブサイトは現在開発の初期段階にあり、皆様のサポートとフィードバックを必要としています。ぜひ試してみて、貴重な提案を提供してください。
使用中にバグが発生したり、提案がある場合は、お気軽に GitHub プロジェクトで問題を提起するか、電子メールでフィードバックを送信してください。
ウェブサイトリンク https://gptsubtitler.com/ja
ご支援、そしてここまで読んでいただきありがとうございます!
100,000 トークンの引き換えコードは次のとおりです: GPTSubtitler_github_repo
設定から使用できます
YouTube ビデオをダウンロード(または自己提供のビデオ)し、Whisper と翻訳 API を使用して双语字幕、中文档请见を生成します
このプロジェクトは、YouTube ビデオをダウンロードし (またはローカル ビデオ ファイルを使用し)、それを文字起こしし、そのトランスクリプトをターゲット言語に翻訳して、二重字幕 (オリジナルと翻訳) 付きのビデオを生成する Python スクリプトです。転写と翻訳は、それぞれ Whisper モデルと翻訳 API (M2M100、google、GPT3.5) を利用しています。
GPT-3.5 翻訳と Google 翻訳の比較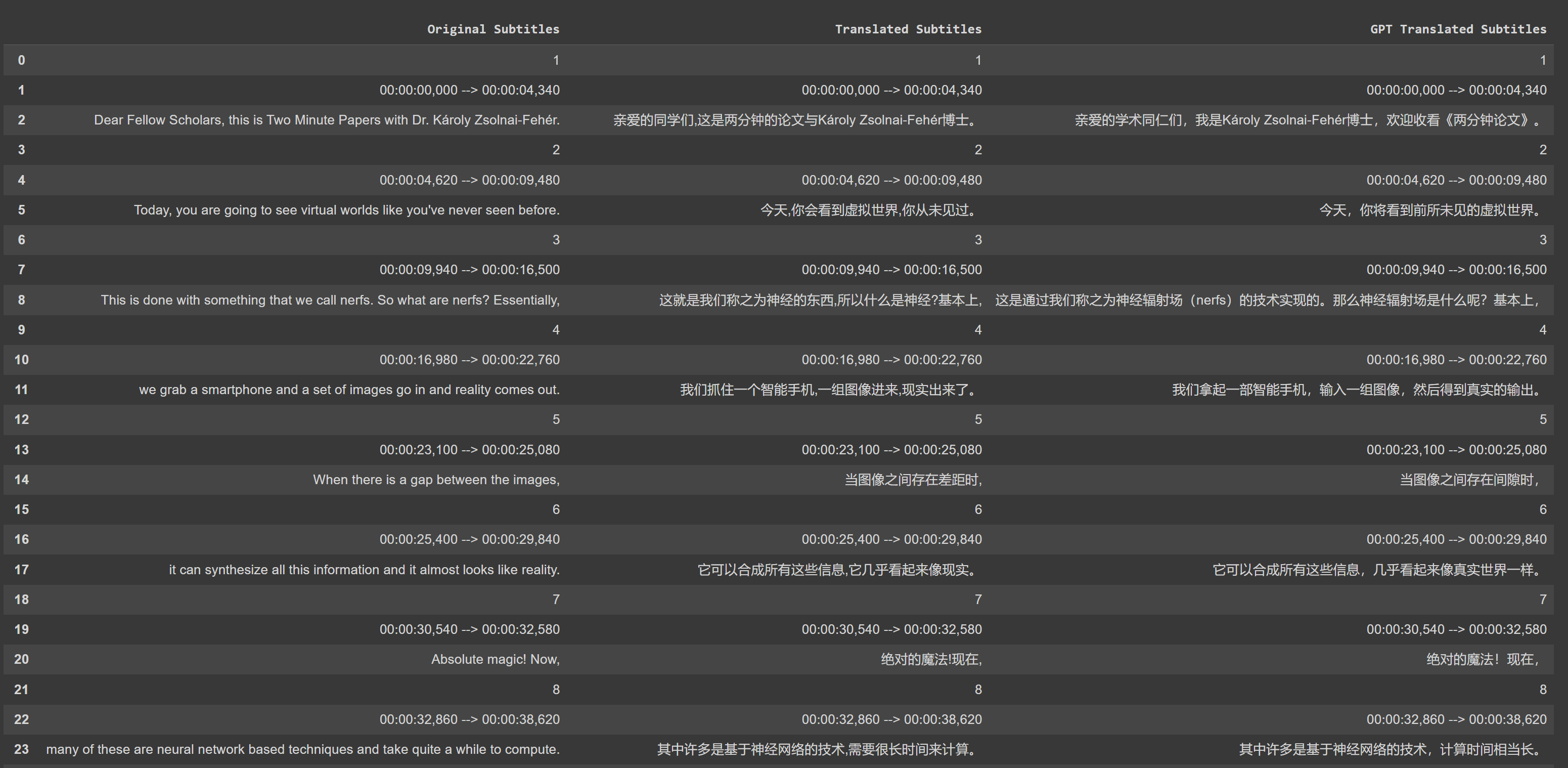
引数: 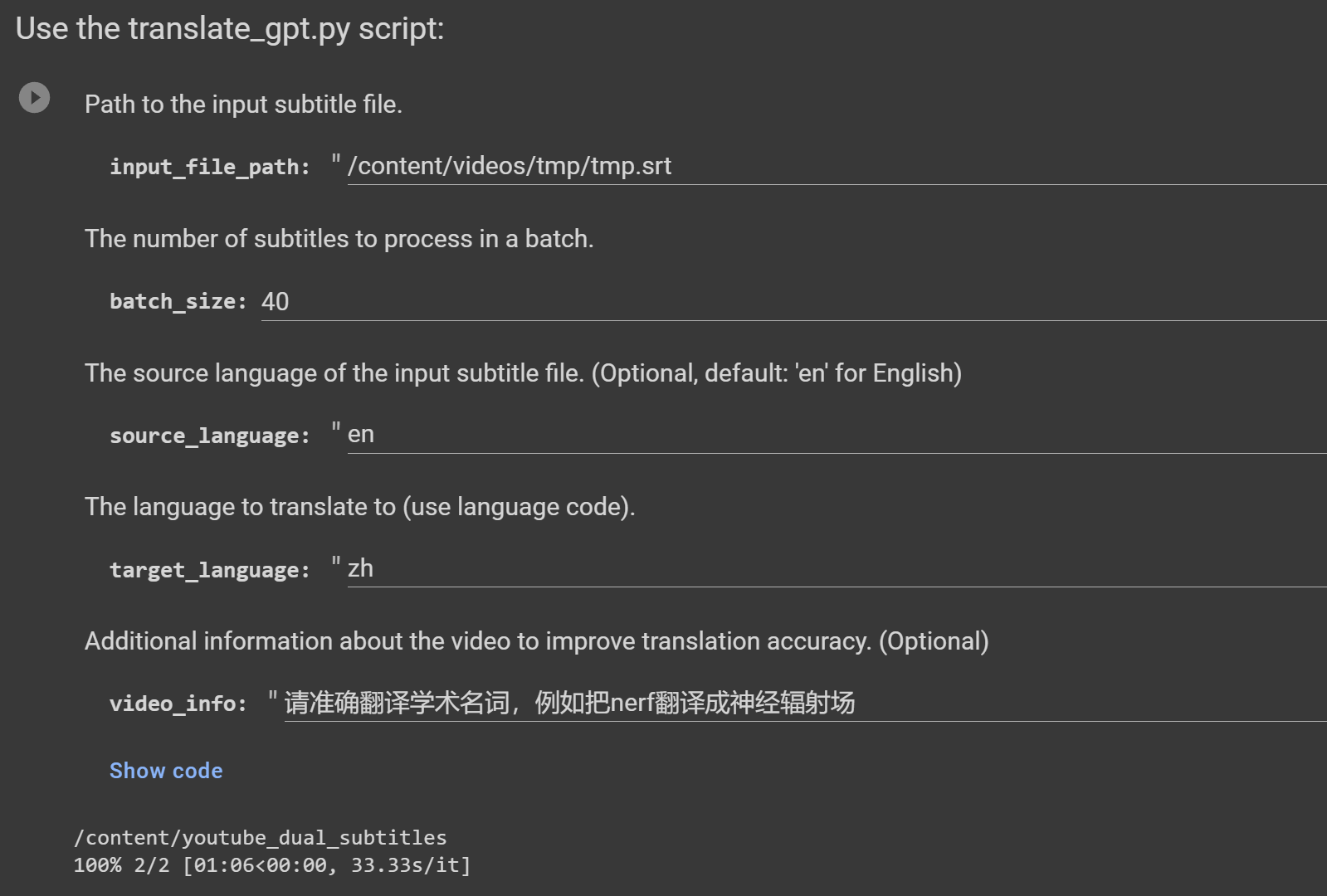
さらに、スクリプトを初めて実行すると、次の事前トレーニングされたモデルがダウンロードされます。
pip install -r requirements.txtを使用して必要な依存関係をインストールします。処理には YouTube URL またはローカル ビデオ ファイルを指定できます。スクリプトはビデオを文字に起こし、トランスクリプトを翻訳し、SRT ファイルの形式で二重字幕を生成します。
python main.py --youtube_url [YOUTUBE_URL] --target_language [TARGET_LANGUAGE] --model [WHISPER_MODEL] --translation_method [TRANSLATION_METHOD]
--youtube_url: YouTube ビデオの URL。
--local_video: ローカル ビデオ ファイルへのパス。
--target_ language: 翻訳のターゲット言語 (デフォルト: 'zh')。
--model: Whisper モデルのいずれかを選択します (デフォルト: 'small'、選択肢: ['tiny'、'base'、'small'、'medium'、'large'])。
--translation_method: 翻訳に使用するメソッド。 (デフォルト: 'google'、選択肢: ['m2m100', 'google', 'whisper', 'gpt', 'no_translate'])。
--no_transcribe: 転写ステップをスキップします。ビデオ ファイルと同じ名前の SRT ファイルがあると仮定します。
注: --youtube_url または --local_video のいずれかを指定する必要がありますが、両方を指定することはできません。
YouTube ビデオをダウンロードし、文字起こしし、Google API を使用してターゲット言語で字幕を生成して翻訳するには、次の手順を実行します。
python main.py --youtube_url [YOUTUBE_URL] --target_language 'zh' --model 'small' --translation_method 'google'
ローカルビデオファイルを処理し、文字起こしし、gpt3.5-16k を使用してターゲット言語で字幕を生成するには (OpenAI API キーを提供する必要があります):
python main.py --local_video [VIDEO_FILE_PATH] --target_language 'zh' --model 'medium' --translation_method 'gpt'
スクリプトは、入力ビデオと同じディレクトリに次の出力ファイルを生成します。
このスクリプトは、OpenAI の GPT-3.5 言語モデルを使用して字幕を翻訳します。機能するにはOpenAI API キーが必要です。ほとんどの場合、特に文脈固有の翻訳や慣用表現を扱う場合、GPT ベースの翻訳は Google 翻訳よりも優れた結果をもたらします。このスクリプトは、Google 翻訳などの従来の翻訳サービスでは満足のいく結果が得られない場合に、字幕を翻訳するための代替方法を提供することを目的としています。
OPENAI_API_KEY=your_api_key_here
your_api_key_here を OpenAI から取得した API キーに置き換えます。
python translate_gpt.py --input_file INPUT_FILE_PATH [--batch_size BATCH_SIZE] [--target_language TARGET_LANGUAGE] [--source_language SOURCE_LANGUAGE] [--video_info VIDEO_INFO] [--model MODEL_NAME] [--no_mapping] [--load_tmp_file]
ChatGPT の場合と同様に、ライブ アップデートの入力ビデオ ファイルが含まれるフォルダー内のresponse.logファイルを確認できます。
注記:
ビデオ情報: --video_info引数は、任意の言語の詳細を受け入れます。これを使用して、ビデオのコンテンツについて GPT モデルに通知し、ゲーム内の固有名詞などのコンテキスト固有の用語の翻訳を改善できます。たとえば、ゲームに関連するビデオを翻訳する場合、ゲーム内の用語に正確な翻訳を使用するように GPT に指示できます。
翻訳マッピング:この機能は、ソースとターゲットの翻訳ペアを保存することで、頻繁に使用される用語の一貫性を維持します。有効にすると、ビデオ全体で固有名詞や専門用語などの翻訳用語が変動するのを防ぎます。必要に応じて--no_mappingフラグを使用してこれを無効にします。
翻訳の再開: --load_tmp_fileフラグを使用して、以前に中断されたところから翻訳タスクを続行します。スクリプトは進行状況をtmp_subtitles.jsonに保存するため、以前の作業をやり直すことなくシームレスに再開できます。
言語サポート:このスクリプトは英語から簡体字中国語への翻訳に優れていますが、他の言語ペアにも対応できます。カスタマイズされた少数のショットの例をfew_shot_examples.jsonに追加することで、追加言語の精度が向上します。 GPT モデルのパフォーマンスは多言語入力によって異なる可能性があり、 translate_gpt.pyでの迅速な調整が必要になる場合があることに注意してください。
貢献は大歓迎です!
Google Colab ノートブックを使用してこのスクリプトを試すこともできます。例にアクセスするには、以下のリンクをクリックしてください。
ノートブックの指示に従って、必要なパッケージとモデルをダウンロードし、目的の YouTube ビデオまたはローカル ビデオ ファイルでスクリプトを実行します。


