multimedia gpt
1.0.0
マルチメディア GPT は、OpenAI GPT をビジョンとオーディオに接続します。 OpenAI API キーを使用して画像、音声録音、PDF ドキュメントを送信し、テキストと画像の両方の形式で応答を取得できるようになりました。現在、ビデオのサポートを追加中です。すべては、Microsoft Visual ChatGPT に基づいて構築されたプロンプト マネージャーによって可能になります。
Microsoft Visual ChatGPT で説明されているすべてのビジョン基盤モデルに加えて、Multimedia GPT は OpenAI Whisper と OpenAI DALLE をサポートしています。これは、音声認識と画像生成に独自の GPU が不要になったことを意味します (ただし、それでも可能です)。
基本チャット モデルは、ChatGPT や GPT-4 を含む任意の OpenAI LLMとして構成できます。デフォルトはtext-davinci-003です。
このプロジェクトをフォークして、独自のユースケースに適したモデルを追加することを歓迎します。これを行う簡単な方法は、llama_index を使用することです。 model.pyでモデルの新しいクラスを作成し、 multimedia_gpt.pyにランナー メソッドrun_<model_name>を追加する必要があります。例については、 run_pdf参照してください。
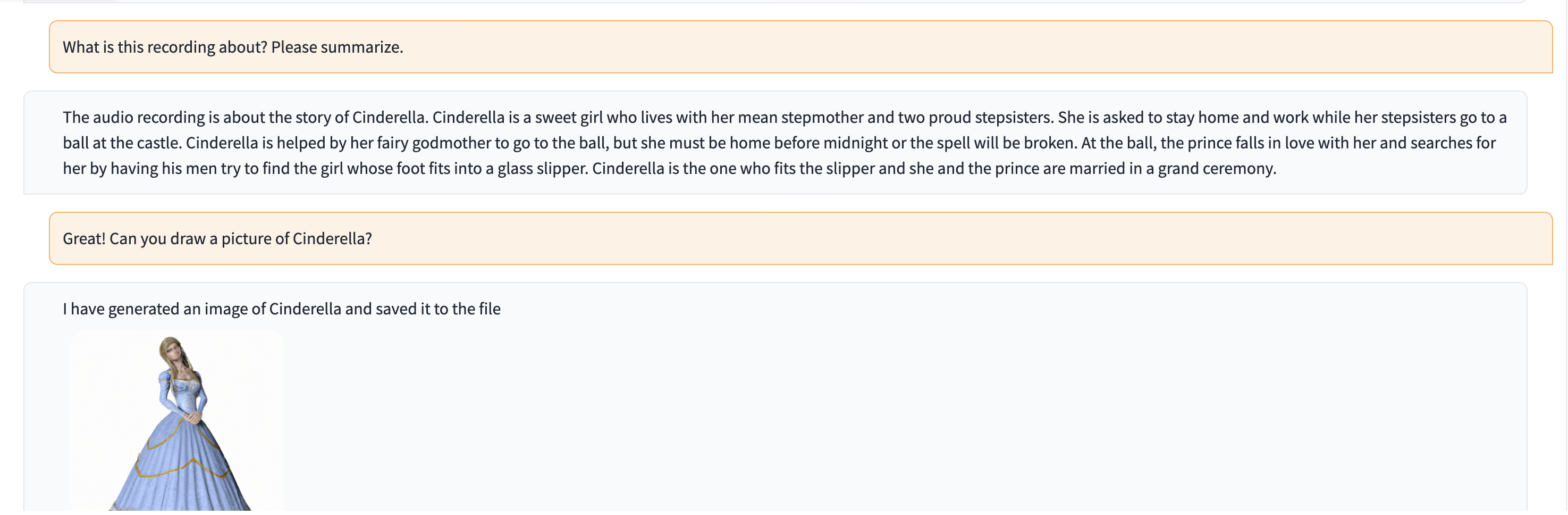
このデモでは、ChatGPT にシンデレラの物語を語る人の録音が供給されます。
# Clone this repository
git clone https://github.com/fengyuli2002/multimedia-gpt
cd multimedia-gpt
# Prepare a conda environment
conda create -n multimedia-gpt python=3.8
conda activate multimedia-gptt
pip install -r requirements.txt
# prepare your private OpenAI key (for Linux / MacOS)
echo " export OPENAI_API_KEY='yourkey' " >> ~ /.zshrc
# prepare your private OpenAI key (for Windows)
setx OPENAI_API_KEY “ < yourkey > ”
# Start Multimedia GPT!
# You can specify the GPU/CPU assignment by "--load", the parameter indicates which foundation models to use and
# where it will be loaded to. The model and device are separated by '_', different models are separated by ','.
# The available Visual Foundation Models can be found in models.py
# For example, if you want to load ImageCaptioning to cuda:0 and whisper to cpu
# (whisper runs remotely, so it doesn't matter where it is loaded to)
# You can use: "ImageCaptioning_cuda:0,Whisper_cpu"
# Don't have GPUs? No worry, you can run DALLE and Whisper on cloud using your API key!
python multimedia_gpt.py --load ImageCaptioning_cpu,DALLE_cpu,Whisper_cpu
# Additionally, you can configure the which OpenAI LLM to use by the "--llm" tag, such as
python multimedia_gpt.py --llm text-davinci-003
# The default is gpt-3.5-turbo (ChatGPT). このプロジェクトは実験的な作業であり、運用環境にはデプロイされません。私たちの目標は、促す力を探求することです。


