SwiftInfer
1.0.0
Streaming-LLM は、LLM 推論の無限の入力長をサポートする技術です。アテンション シンクを利用して、アテンション ウィンドウが移動したときのモデルの崩壊を防ぎます。オリジナルの作業は PyTorch で実装されていますが、StreamingLLM をより実稼働グレードにするための TensorRT 実装であるSwiftInferを提供しています。私たちの実装は、最近リリースされたTensorRT-LLMプロジェクトに基づいて構築されました。
TensorRT-LLMの API を使用してモデルを構築し、推論を実行します。 TensorRT-LLM の API は安定しておらず、急速に変化しているため、バージョンがv0.6.0の42af740db51d6f11442fd5509ef745a4c043ce51コミットに実装をバインドします。 TensorRT-LLM の API がより安定するにつれて、このリポジトリをアップグレードする可能性があります。
TensorRT-LLM V0.6.0をビルドしている場合は、次を実行するだけです。
git clone https://github.com/hpcaitech/SwiftInfer.git
cd SwiftInfer
pip install .それ以外の場合は、最初に TensorRT-LLM をインストールする必要があります。
Docker を使用している場合は、「TensorRT-LLM インストール」に従ってTensorRT-LLM V0.6.0をインストールできます。
docker を使用すると、以下を実行するだけで SwiftInfer をインストールできます。
git clone https://github.com/hpcaitech/SwiftInfer.git
cd SwiftInfer
pip install . docker を使用しない場合は、TensorRT-LLM を自動的にインストールするスクリプトが提供されます。
前提条件
次のパッケージがインストールされていることを確認してください。
TensorRT のバージョンが 9.1.0 以上、CUDA ツールキットが 12.2 以上であることを確認してください。
tensorrt をインストールするには:
ARCH= $( uname -m )
if [ " $ARCH " = " arm64 " ] ; then ARCH= " aarch64 " ; fi
if [ " $ARCH " = " amd64 " ] ; then ARCH= " x86_64 " ; fi
if [ " $ARCH " = " aarch64 " ] ; then OS= " ubuntu-22.04 " ; else OS= " linux " ; fi
wget https://developer.nvidia.com/downloads/compute/machine-learning/tensorrt/secure/9.1.0/tars/tensorrt-9.1.0.4. $OS . $ARCH -gnu.cuda-12.2.tar.gz
tar xzvf tensorrt-9.1.0.4.linux.x86_64-gnu.cuda-12.2.tar.gz
PY_VERSION= $( python -c ' import sys; print(".".join(map(str, sys.version_info[0:2]))) ' )
PARSED_PY_VERSION= $( echo " ${PY_VERSION // . / } " )
pip install TensorRT-9.1.0.4/python/tensorrt- * -cp ${PARSED_PY_VERSION} - * .whl
export TRT_ROOT= $( realpath TensorRT-9.1.0.4 )nccl をダウンロードするには、NCCL のダウンロード ページに従ってください。
cudnn をダウンロードするには、cuDNN ダウンロード ページに従ってください。
コマンド
次のコマンドを実行する前に、 nvcc正しく設定されていることを確認してください。それを確認するには、次を実行します。
nvcc --versionTensorRT-LLM と SwiftInfer をインストールするには、次を実行します。
git clone https://github.com/hpcaitech/SwiftInfer.git
cd SwiftInfer
TRT_ROOT=xxx NCCL_ROOT=xxx CUDNN_ROOT=xxx pip install .Llama サンプルを実行するには、まず metal-llama/Llama-2-7b-chat-hf モデルまたは他の Llama ベースのバリアント (lmsys/vicuna-7b-v1.3 など) の Hugging Face リポジトリのクローンを作成する必要があります。次に、次のコマンドを実行して TensorRT エンジンを構築できます。 <model-dir> Llama モデルへの実際のパスに置き換える必要があります。
cd examples/llama
python build.py
--model_dir < model-dir >
--dtype float16
--enable_context_fmha
--use_gemm_plugin float16
--max_input_len 2048
--max_output_len 1024
--output_dir ./output/7B-streaming-8k-1k-4-2000/trt_engines/fp16/1-gpu/
--max_batch_size 1次に、LMSYS-FastChat が提供する MT-Bench データをダウンロードする必要があります。
mkdir mt_bench_data
wget -P ./mt_bench_data https://raw.githubusercontent.com/lm-sys/FastChat/main/fastchat/llm_judge/data/mt_bench/question.jsonl最後に、次のコマンドを使用して Llama サンプルを実行する準備が整いました。
❗️❗️❗️その前に、次の点にご注意ください。
only_n_first引数は、評価されるサンプルの数を制御するために使用されます。すべてのサンプルを評価したい場合は、この引数を削除してください。 python ../run_conversation.py
--max_input_length 2048
--max_output_len 1024
--tokenizer_dir < model-dir >
--engine_dir ./output/7B-streaming-8k-1k-4-2000/trt_engines/fp16/1-gpu/
--input_file ./mt_bench_data/question.jsonl
--streaming_llm_start_size 4
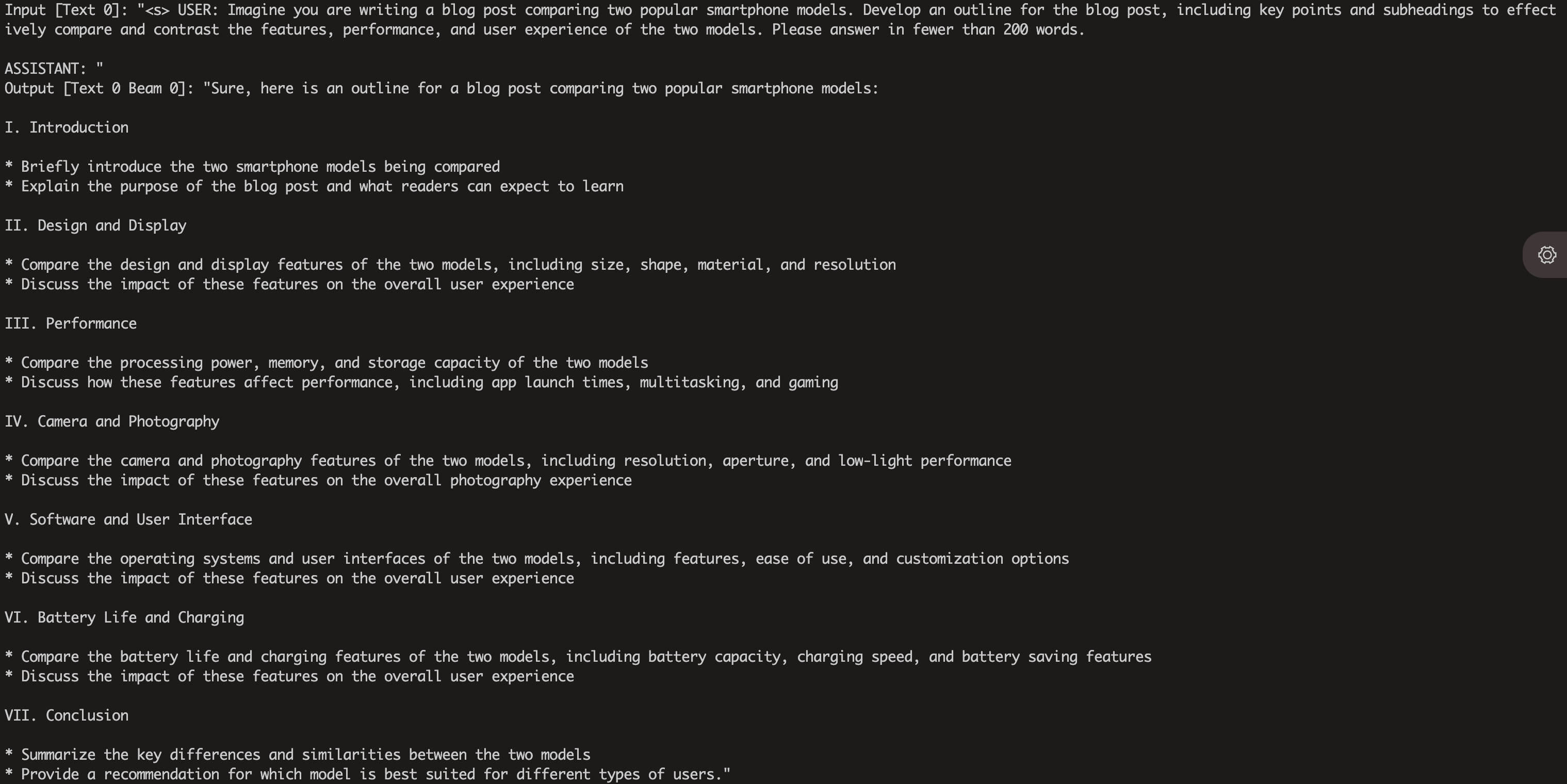
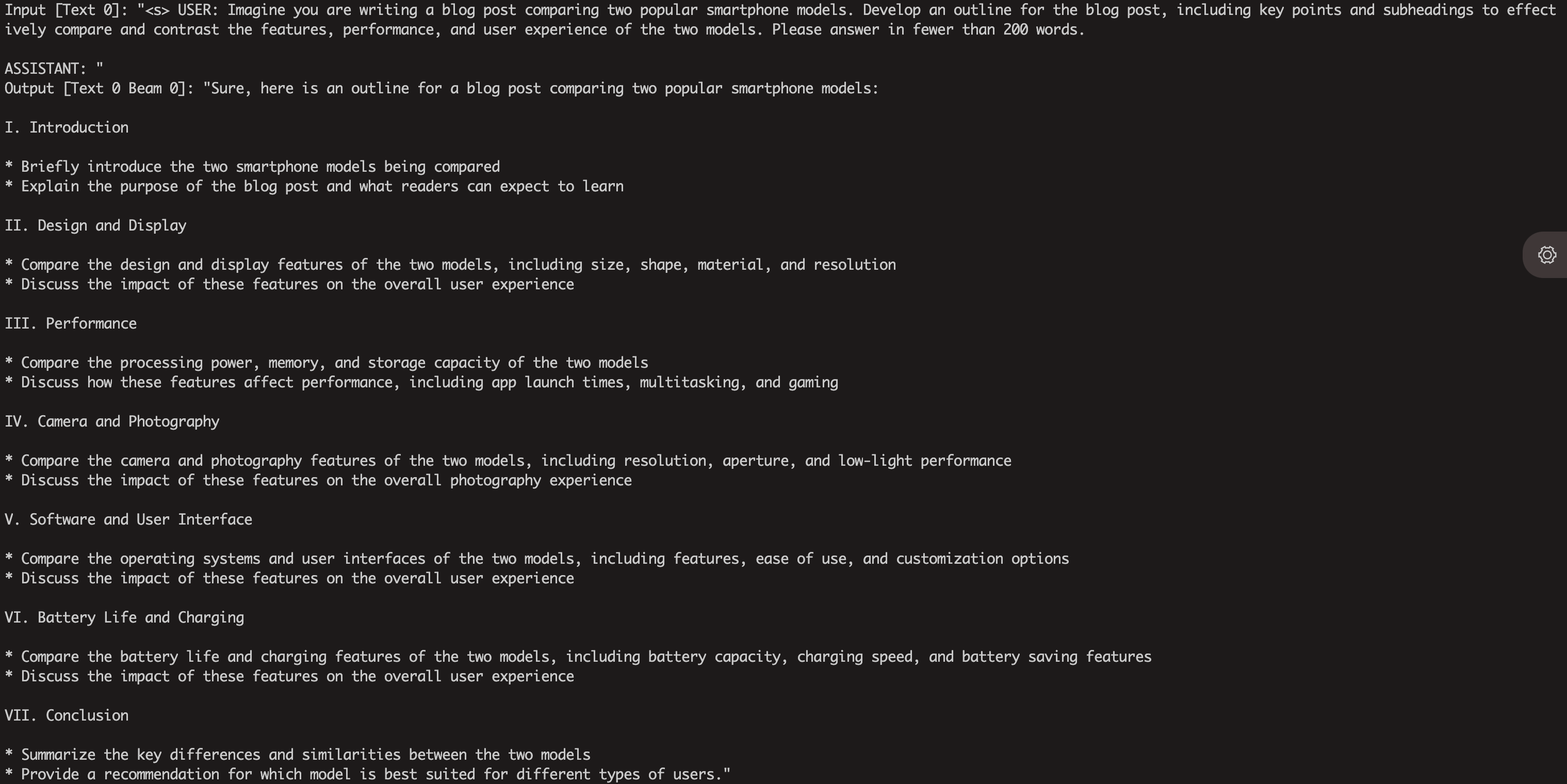
--only_n_first 5次のように生成されることが予想されます。
オリジナルの PyTorch バージョンを使用して、Streaming-LLM の実装をベンチマークしました。私たちの実装のベンチマーク コマンドは「Llama の実行例」セクションに示されていますが、元の PyTorch 実装のベンチマーク コマンドは torch_streamingllm フォルダーに示されています。使用したハードウェアは以下のとおりです。
結果 (20 ラウンドの会話) は次のとおりです。
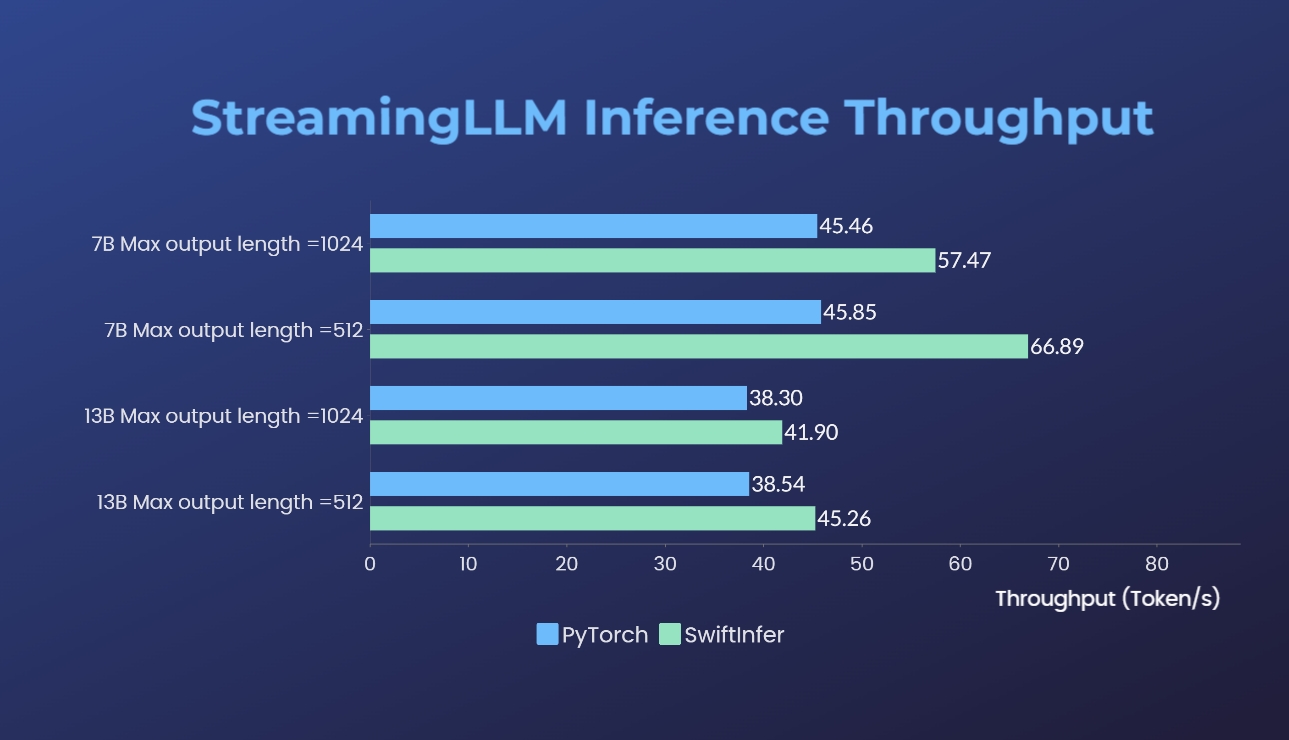
私たちはさらなるパフォーマンスの向上と TensorRT V0.7.1 API への適応に引き続き取り組んでいます。また、サンプルでは TensorRT-LLM に StreamingLLM が統合されていますが、これは複数ラウンドの会話ではなく単一のテキスト生成に適しているようです。
この作品は、Streaming-LLM からインスピレーションを得て、本番環境で使用できるようにしています。開発全体を通じて、私たちは次の資料を参照しました。これらの資料の努力と、オープンソース コミュニティと学術界への貢献に感謝したいと思います。
StreamingLLM と TensorRT 実装が役立つと思われる場合は、私たちのリポジトリと Xiao らによって提案されたオリジナルの研究を引用してください。 MITハン研究所出身。
# our repository
# NOTE: the listed authors have equal contribution
@misc { streamingllmtrt2023 ,
title = { SwiftInfer } ,
year = { 2023 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/hpcaitech/SwiftInfer} } ,
}
# Xiao's original paper
@article { xiao2023streamingllm ,
title = { Efficient Streaming Language Models with Attention Sinks } ,
author = { Xiao, Guangxuan and Tian, Yuandong and Chen, Beidi and Han, Song and Lewis, Mike } ,
journal = { arXiv } ,
year = { 2023 }
}
# TensorRT-LLM repo
# as TensorRT-LLM team does not provide a bibtex
# please let us know if there is any change needed
@misc { trtllm2023 ,
title = { TensorRT-LLM } ,
year = { 2023 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/NVIDIA/TensorRT-LLM} } ,
}