paxml
paxml release 1.4.0
Pax は、Jax 上で機械学習実験を構成して実行するためのフレームワークです。
Cloud TPU プロジェクトの開始に関する詳細なドキュメントについては、このページを参照してください。企業マシンから 8 コアの Cloud TPU VM を作成するには、次のコマンドで十分です。
export ZONE=us-central2-b
export VERSION=tpu-vm-v4-base
export PROJECT= < your-project >
export ACCELERATOR=v4-8
export TPU_NAME=paxml
# create a TPU VM
gcloud compute tpus tpu-vm create $TPU_NAME
--zone= $ZONE --version= $VERSION
--project= $PROJECT
--accelerator-type= $ACCELERATOR TPU Pod スライスを使用している場合は、このガイドを参照してください。 --worker=allオプションを指定して gcloud を使用し、ローカル マシンからすべてのコマンドを実行します。
gcloud compute tpus tpu-vm ssh $TPU_NAME --zone= $ZONE
--worker=all --command= " <commmands> "次のクイックスタート セクションでは、単一ホスト TPU で実行していることを前提としているため、VM に SSH で接続し、そこでコマンドを実行できます。
gcloud compute tpus tpu-vm ssh $TPU_NAME --zone= $ZONEVM に SSH 接続した後、PyPI から paxml 安定版リリースをインストールするか、github から開発バージョンをインストールできます。
PyPI (https://pypi.org/project/paxml/) から安定版リリースをインストールするには:
python3 -m pip install -U pip
python3 -m pip install paxml jax[tpu]
-f https://storage.googleapis.com/jax-releases/libtpu_releases.html推移的な依存関係に関する問題が発生し、ネイティブ Cloud TPU VM 環境を使用している場合は、対応するリリース ブランチ rX.YZ に移動し、 paxml/pip_package/requirements.txtダウンロードしてください。このファイルには、対応するリリースをビルド/テストするネイティブ Cloud TPU VM 環境で必要なすべての推移的な依存関係の正確なバージョンが含まれています。
git clone -b rX.Y.Z https://github.com/google/paxml
pip install --no-deps -r paxml/paxml/pip_package/requirements.txtGithub から開発バージョンをインストールし、コードを編集しやすくするために:
# install the dev version of praxis first
git clone https://github.com/google/praxis
pip install -e praxis
git clone https://github.com/google/paxml
pip install -e paxml
pip install " jax[tpu] " -f https://storage.googleapis.com/jax-releases/libtpu_releases.html # example model using pjit (SPMD)
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.lm_cloud.LmCloudSpmd2BLimitSteps
--job_log_dir=gs:// < your-bucket >
# example model using pmap
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.lm_cloud.LmCloudTransformerAdamLimitSteps
--job_log_dir=gs:// < your-bucket >
--pmap_use_tensorstore=Trueドキュメントと Jupyter Notebook チュートリアルについては、docs フォルダーにアクセスしてください。 Cloud TPU VM で Jupyter Notebook を実行する手順については、次のセクションを参照してください。
paxml をインストールしたばかりの TPU VM でサンプル ノートブックを実行できます。 #### v4-8でノートブックを有効にする手順
ポート転送を使用した TPU VM の ssh gcloud compute tpus tpu-vm ssh $TPU_NAME --project=$PROJECT_NAME --zone=$ZONE --ssh-flag="-4 -L 8080:localhost:8080"
TPU VM に jupyter Notebook をインストールし、Markupsafe をダウングレードします
pip install notebook
pip install markupsafe==2.0.1
jupyterパスをエクスポートexport PATH=/home/$USER/.local/bin:$PATH
scp サンプル ノートブックを TPU VM にgcloud compute tpus tpu-vm scp $TPU_NAME:<path inside TPU> <local path of the notebooks> --zone=$ZONE --project=$PROJECT
TPU VM から jupyter Notebook を起動し、jupyter Notebook によって生成されたトークンをメモしますjupyter notebook --no-browser --port=8080
次に、ローカル ブラウザで http://localhost:8080/ に移動し、提供されたトークンを入力します。
注: 最初のノートブックがまだ TPU を占有している間に 2 番目のノートブックの使用を開始する必要がある場合は、 pkill -9 python3実行して TPU を解放できます。
注: NVIDIA は、H100 FP8 のサポートと広範な GPU パフォーマンスの向上を備えた Pax の更新バージョンをリリースしました。詳細と使用手順については、NVIDIA Rosetta リポジトリにアクセスしてください。
Profile Guided Latency Estimator (PGLE) ワークフローは、コンピューティングとコレクティブの実際の実行時間を測定します。プロファイル情報は、より適切なスケジューリング決定のために XLA コンパイラーにフィードバックされます。
Profile Guided Latency Estimator は手動または自動で使用できます。自動モードでは、JAX はプロファイル情報を収集し、1 回の実行でモジュールを再コンパイルします。手動モードでは、タスクを 2 回実行する必要があります。1 回目はプロファイルを収集して保存し、2 回目は提供されたデータを使用してコンパイルして実行します。
自動 PGLE は、次の環境変数を設定することでオンにできます。
XLA_FLAGS="--xla_gpu_enable_latency_hiding_scheduler=true"
JAX_ENABLE_PGLE=true
JAX_PGLE_PROFILING_RUNS=3
JAX_REMOVE_CUSTOM_PARTITIONING_PTR_FROM_CACHE_KEY=True
Optional JAX_PGLE_AGGREGATION_PERCENTILE=85
または、JAX では次のように設定できます。
import jax
from jax._src import config
with config.enable_pgle(True), config.pgle_profiling_runs(1):
# Run with the profiler collecting performance information.
train_step()
# Automatically re-compile with PGLE profile results
train_step()
...
JAX_PGLE_PROFILING_RUNSを変更することで、プロファイル データの収集に使用される再実行の量を制御できます。このパラメータを増やすと、より良いプロファイル情報が得られますが、最適化されていないトレーニング ステップの量も増加します。
JAX_REMOVE_CUSTOM_PARTITIONING_PTR_FROM_CACHE_KEYパラメーターを使用すると、自動 PGLE でホスト コールバックを使用できます。
JAX_PGLE_AGGREGATION_PERCENTILEパラメータを減らすと、ステップ間のパフォーマンスにノイズが多すぎて、関連しないメジャーを除外できない場合に役立つ場合があります。
注意:自動 PGLE は、プリコンパイルされたモジュールに対しては機能しません。 JAX は実行中にモジュールを再コンパイルする必要があるため、自動 PGLE は AoT に対しても次の場合にも機能しません。
import jax
from jax._src import config
train_step_compiled = train_step().lower().compile()
with config.enable_pgle(True), config.pgle_profiling_runs(1):
train_step_compiled()
# No effect since module was pre-compiled.
train_step_compiled()
それでも手動の Profile Guided Latency Estimator を使用したい場合、XLA/GPU のワークフローは次のとおりです。
次のように設定することでこれを行うことができます。
export XLA_FLAGS= " --xla_gpu_enable_latency_hiding_scheduler=true " import os
from etils import epath
import jax
from jax . experimental import profiler as exp_profiler
# Define your profile directory
profile_dir = 'gs://my_bucket/profile'
jax . profiler . start_trace ( profile_dir )
# run your workflow
# for i in range(10):
# train_step()
# Stop trace
jax . profiler . stop_trace ()
profile_dir = epath . Path ( profile_dir )
directories = profile_dir . glob ( 'plugins/profile/*/' )
directories = [ d for d in directories if d . is_dir ()]
rundir = directories [ - 1 ]
logging . info ( 'rundir: %s' , rundir )
# Post process the profile
fdo_profile = exp_profiler . get_profiled_instructions_proto ( os . fspath ( rundir ))
# Save the profile proto to a file.
dump_dir = rundir / 'profile.pb'
dump_dir . parent . mkdir ( parents = True , exist_ok = True )
dump_dir . write_bytes ( fdo_profile )この手順を完了すると、コードに出力されたrundirの下にprofile.pbファイルが作成されます。
profile.pbファイルを--xla_gpu_pgle_profile_file_or_directory_pathフラグに渡す必要があります。
export XLA_FLAGS= " --xla_gpu_enable_latency_hiding_scheduler=true --xla_gpu_pgle_profile_file_or_directory_path=/path/to/profile/profile.pb " XLA でのログ記録を有効にしてプロファイルが適切かどうかを確認するには、ログ レベルをINFOが含まれるように設定します。
export TF_CPP_MIN_LOG_LEVEL=0実際のワークフローを実行します。実行ログに次のログが見つかった場合は、プロファイラーが遅延隠蔽スケジューラーで使用されていることを意味します。
2023-07-21 16:09:43.551600: I external/xla/xla/service/gpu/gpu_hlo_schedule.cc:478] Using PGLE profile from /tmp/profile/plugins/profile/2023_07_20_18_29_30/profile.pb
2023-07-21 16:09:43.551741: I external/xla/xla/service/gpu/gpu_hlo_schedule.cc:573] Found profile, using profile guided latency estimator
Pax は Jax 上で実行されます。Cloud TPU での Jax ジョブの実行の詳細については、ここで確認できます。また、Cloud TPU ポッドでの Jax ジョブの実行の詳細については、こちらで確認できます。
依存関係エラーが発生した場合は、インストールしている安定リリースに対応するブランチにあるrequirements.txtファイルを参照してください。たとえば、安定版リリース 0.4.0 の場合は、ブランチr0.4.0使用し、安定版リリースに使用される依存関係の正確なバージョンについては、requirements.txt を参照してください。
以下に、c4 データセットでの収束実行のサンプルをいくつか示します。
次のように c4.py の構成C4Spmd1BAdam4Replicasを使用して、TPU v4-8上の c4 データセットで1B params モデルを実行できます。
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4.C4Spmd1BAdam4Replicas
--job_log_dir=gs:// < your-bucket >次のように、損失曲線とlog perplexityグラフを観察できます。
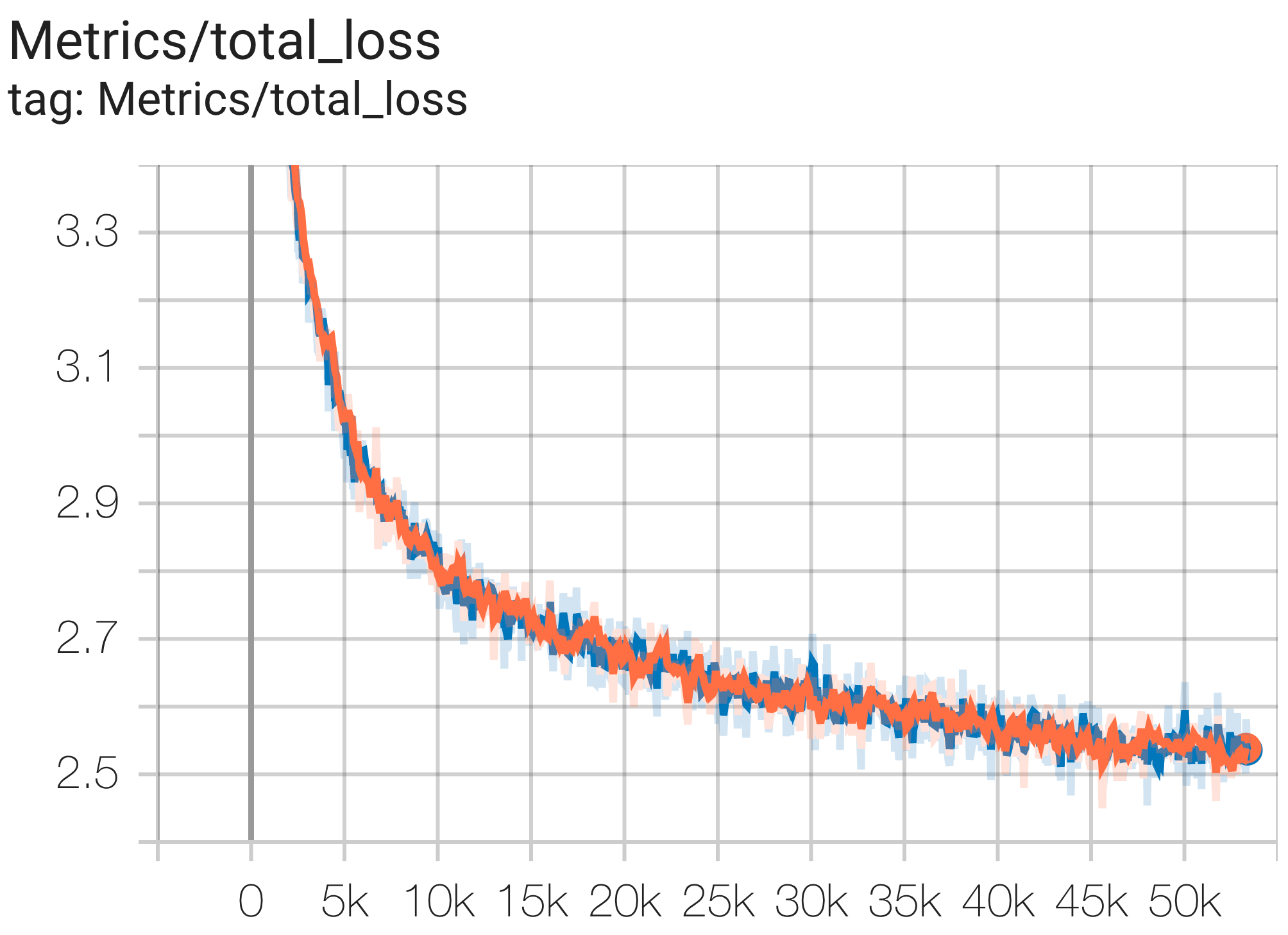
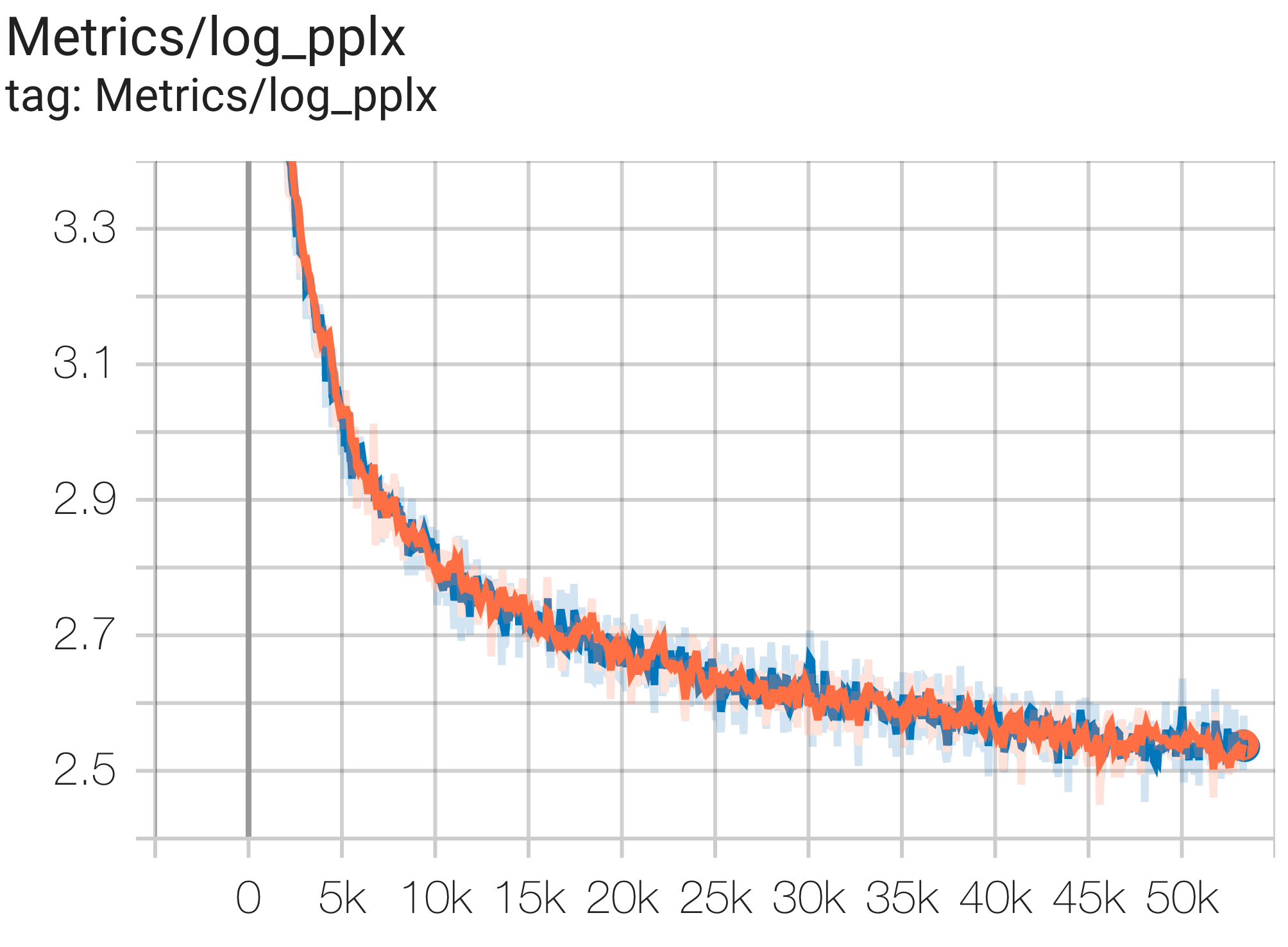
次のように c4.py の構成C4Spmd16BAdam32Replicasを使用して、TPU v4-64の c4 データセットで16Bパラメータ モデルを実行できます。
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4.C4Spmd16BAdam32Replicas
--job_log_dir=gs:// < your-bucket >次のように、損失曲線とlog perplexityグラフを観察できます。
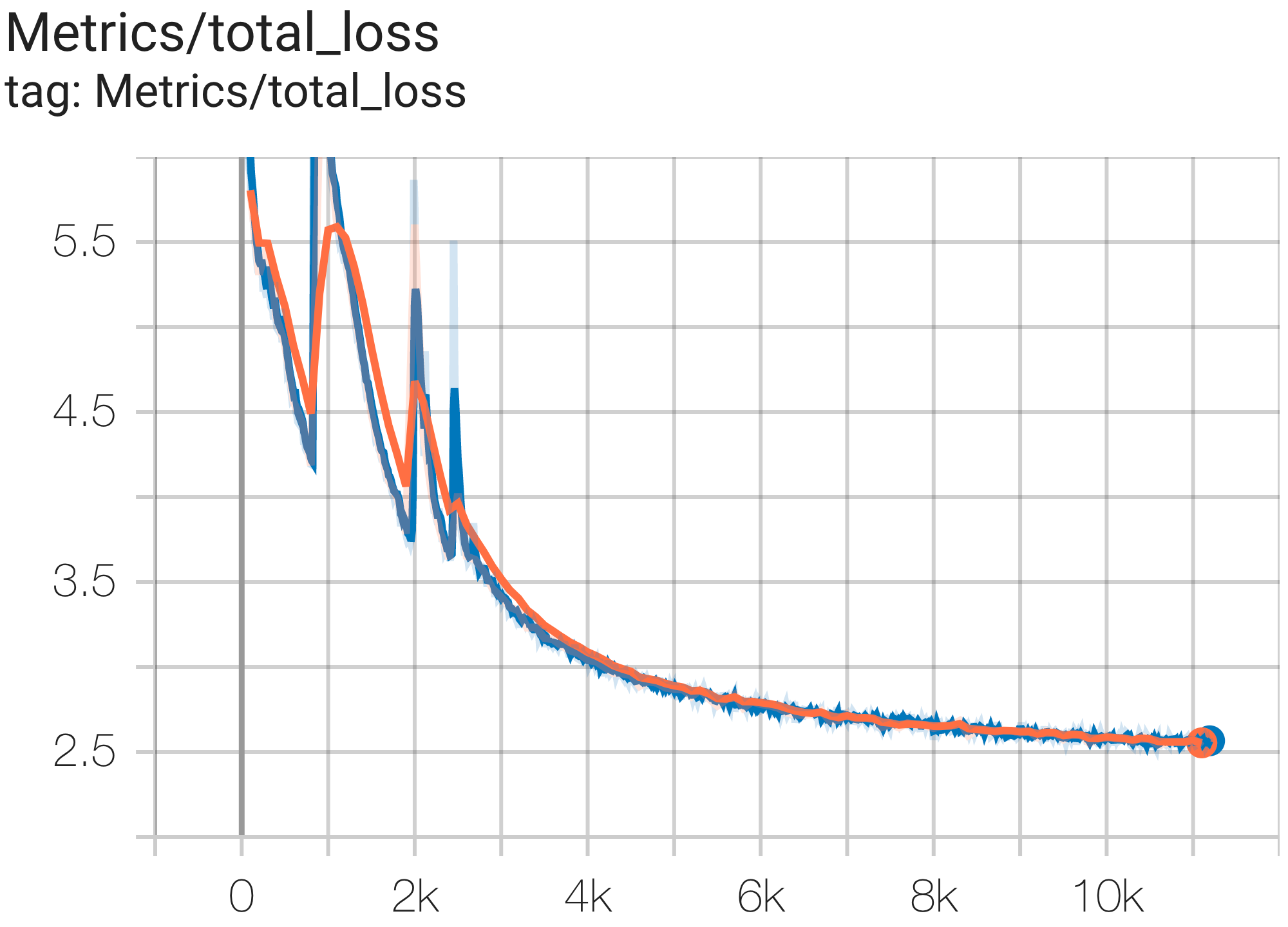
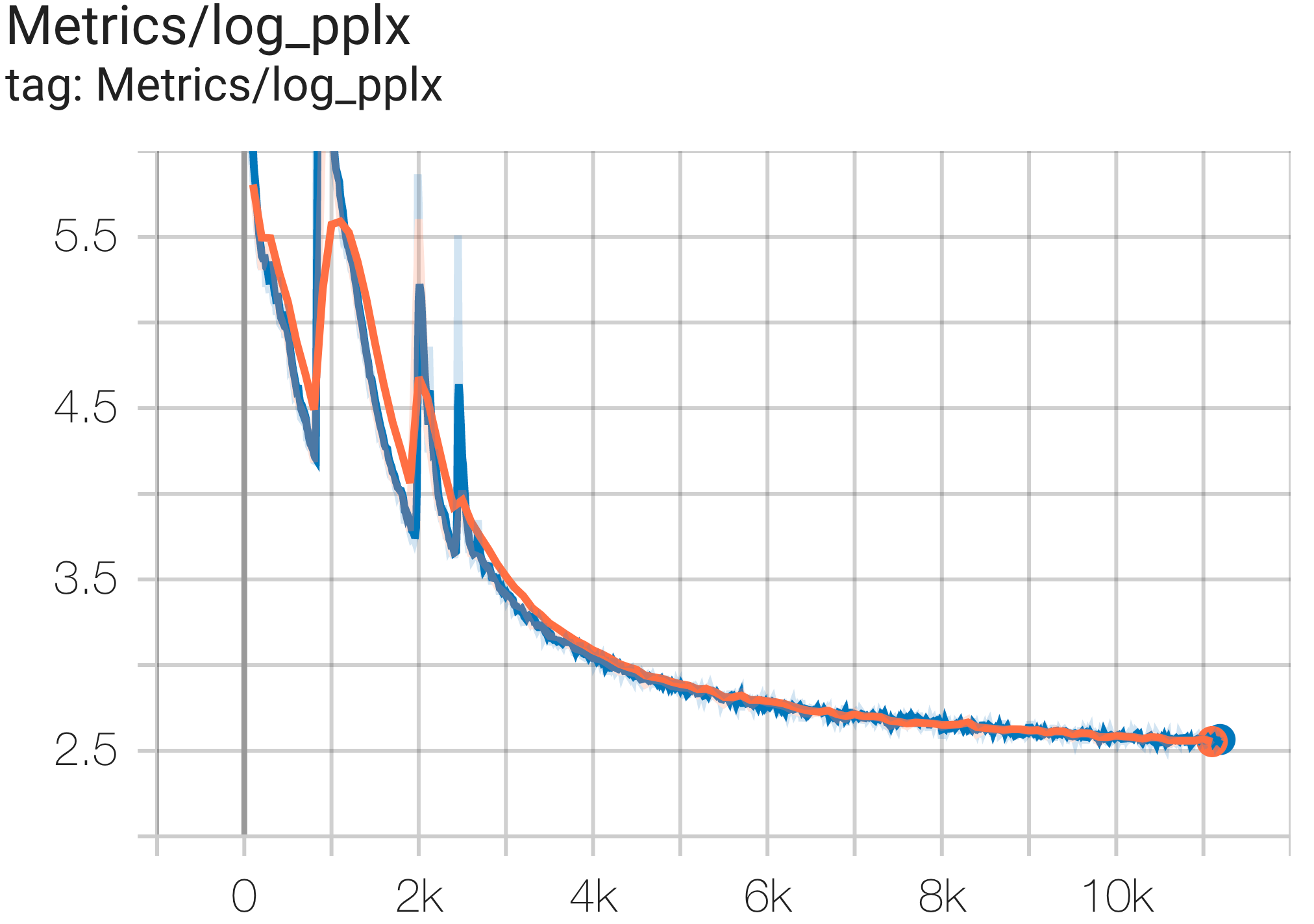
次のように c4.py の構成C4SpmdPipelineGpt3SmallAdam64Replicasを使用して、TPU v4-128上の c4 データセットで GPT3-XL モデルを実行できます。
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4.C4SpmdPipelineGpt3SmallAdam64Replicas
--job_log_dir=gs:// < your-bucket >次のように、損失曲線とlog perplexityグラフを観察できます。
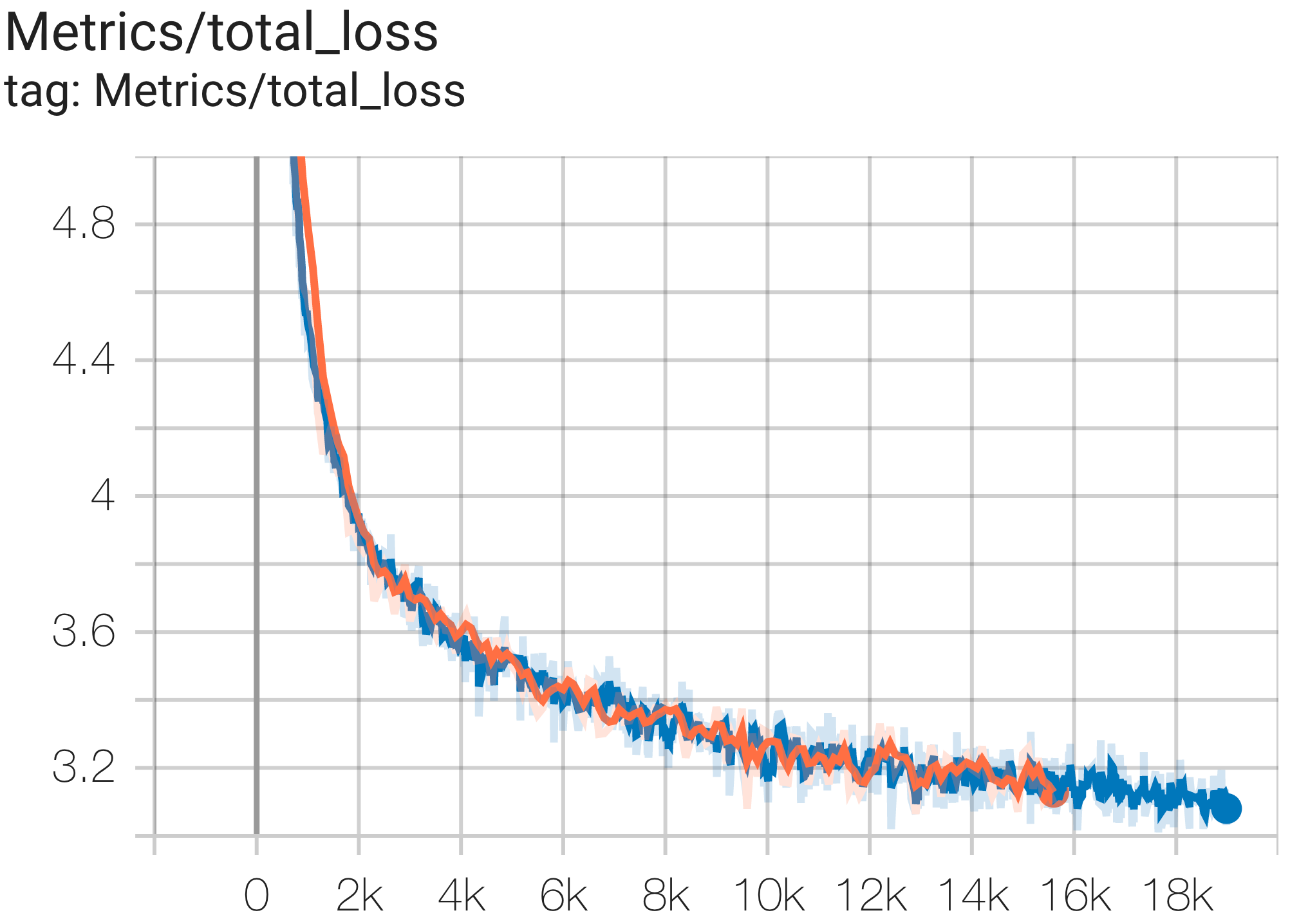
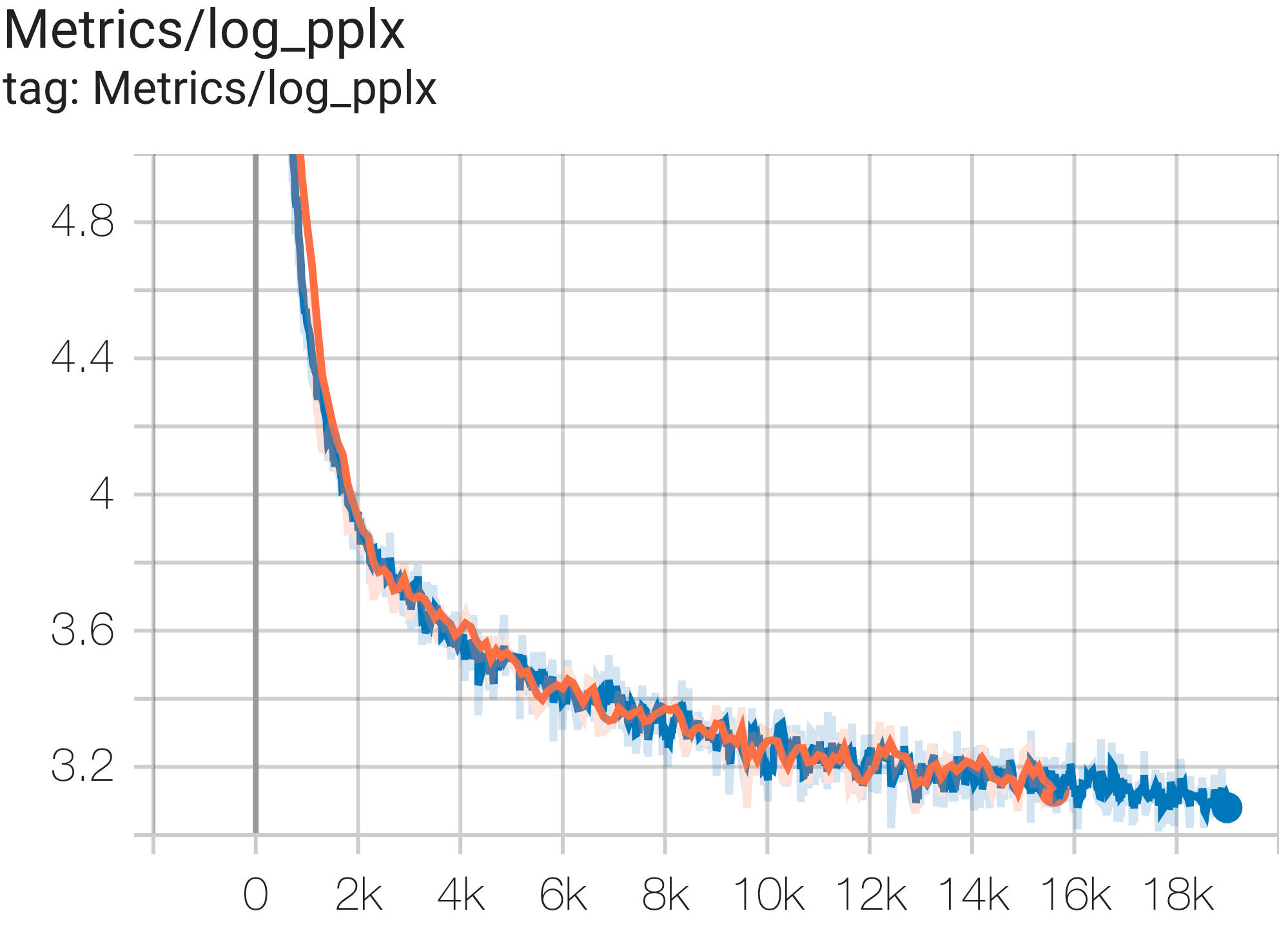
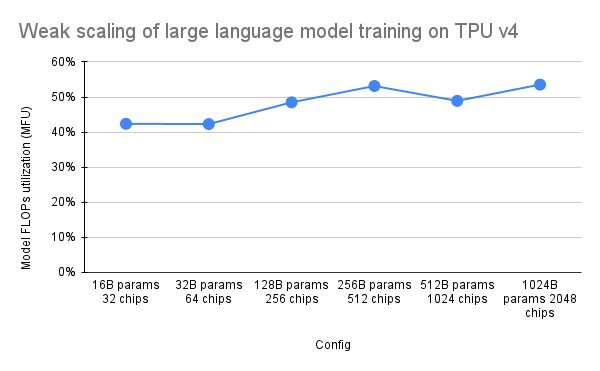
PaLM の論文では、Model FLOPs Utilization (MFU) と呼ばれる効率指標が導入されました。これは、ピーク FLOP を 100% 活用するシステムの理論上の最大スループットに対する、観測されたスループット (たとえば、言語モデルの 1 秒あたりのトークン数) の比率として測定されます。これは、バックワード パス中のアクティベーションの再具体化に費やされる FLOP が含まれないため、コンピューティング使用率を測定する他の方法とは異なります。つまり、MFU によって測定された効率がエンドツーエンドのトレーニング速度に直接変換されます。
Pax を使用した TPU v4 Pod 上の主要なクラスのワークロードの MFU を評価するために、数十億から数兆のパラメーターにわたる一連のデコーダー専用の Transformer 言語モデル (GPT) 構成に対して詳細なベンチマーク キャンペーンを実行しました。 c4 データセット上。次のグラフは、使用するチップの数に比例してモデル サイズを拡大する「弱いスケーリング」パターンを使用したトレーニング効率を示しています。
このリポジトリのマルチスライス構成は、1. 構文/モデル アーキテクチャについては単一スライス構成、および 2. 構成値については MaxText リポジトリを参照します。
マルチスライスでの Pax の開始点として、c4_multislice.py` の下で実行される例を提供します。
マルチスライス Cloud TPU プロジェクトでのキュー リソースの使用に関する詳細なドキュメントについては、このページを参照してください。以下は、このリポジトリでサンプル構成を実行するために TPU をセットアップするために必要な手順を示しています。
export ZONE=us-central2-b
export VERSION=tpu-vm-v4-base
export PROJECT= < your-project >
export ACCELERATOR=v4-128 # or v4-384 depending on which config you runたとえば、v4-128 の 2 つのスライスでC4Spmd22BAdam2xv4_128を実行するには、次の方法で TPU を設定する必要があります。
export TPU_PREFIX= < your-prefix > # New TPUs will be created based off this prefix
export QR_ID= $TPU_PREFIX
export NODE_COUNT= < number-of-slices > # 1, 2, or 4 depending on which config you run
# create a TPU VM
gcloud alpha compute tpus queued-resources create $QR_ID --accelerator-type= $ACCELERATOR --runtime-version=tpu-vm-v4-base --node-count= $NODE_COUNT --node-prefix= $TPU_PREFIX前に説明したセットアップ コマンドは、すべてのスライスのすべてのワーカーで実行する必要があります。 1) 各ワーカーと各スライスに個別に SSH 接続できます。または 2) 次のコマンドのように--worker=allフラグを指定した for ループを使用します。
for (( i = 0 ; i < $NODE_COUNT ; i ++ ))
do
gcloud compute tpus tpu-vm ssh $TPU_PREFIX - $i --zone=us-central2-b --worker=all --command= " pip install paxml && pip install orbax==0.1.1 && pip install " jax[tpu] " -f https://storage.googleapis.com/jax-releases/libtpu_releases.html "
doneマルチスライス構成を実行するには、$NODE_COUNT と同じ数のターミナルを開きます。 2 つのスライス ( C4Spmd22BAdam2xv4_128 ) での実験では、2 つの端末を開きます。次に、これらの各コマンドを各端末から個別に実行します。
ターミナル 0 から、次のようにスライス 0 のトレーニング コマンドを実行します。
export TPU_PREFIX= < your-prefix >
export EXP_NAME=C4Spmd22BAdam2xv4_128
export LIBTPU_INIT_ARGS= " --xla_jf_spmd_threshold_for_windowed_einsum_mib=0 --xla_tpu_spmd_threshold_for_allgather_cse=10000 --xla_enable_async_all_gather=true --xla_tpu_enable_latency_hiding_scheduler=true TPU_MEGACORE=MEGACORE_DENSE "
gcloud compute tpus tpu-vm ssh $TPU_PREFIX -0 --zone=us-central2-b --worker=all
--command= " LIBTPU_INIT_ARGS= $LIBTPU_INIT_ARGS
python3 /home/yooh/.local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4_multislice. ${EXP_NAME} --job_log_dir=gs://<your-bucket> "ターミナル 1 から、次のようにスライス 1 のトレーニング コマンドを同時に実行します。
export TPU_PREFIX= < your-prefix >
export EXP_NAME=C4Spmd22BAdam2xv4_128
export LIBTPU_INIT_ARGS= " --xla_jf_spmd_threshold_for_windowed_einsum_mib=0 --xla_tpu_spmd_threshold_for_allgather_cse=10000 --xla_enable_async_all_gather=true --xla_tpu_enable_latency_hiding_scheduler=true TPU_MEGACORE=MEGACORE_DENSE "
gcloud compute tpus tpu-vm ssh $TPU_PREFIX -1 --zone=us-central2-b --worker=all
--command= " LIBTPU_INIT_ARGS= $LIBTPU_INIT_ARGS
python3 /home/yooh/.local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4_multislice. ${EXP_NAME} --job_log_dir=gs://<your-bucket> "この表では、MaxText 変数名がどのように Pax に変換されるかについて詳しく説明します。
MaxText には、最終値としていくつかのパラメータ (base_num_decoder_layers、base_emb_dim、base_mlp_dim、base_num_heads) を乗算する「スケール」があることに注意してください。
もう 1 つ言及すべきことは、Pax は DCN と ICN MESH_SHAPE を配列としてカバーしますが、MaxText では DCN と ICI に対して data_Parallelism、fsdp_Parallelism、tensor_Parallelism の個別の変数があることです。これらの値はデフォルトで 1 に設定されているため、1 より大きい値を持つ変数のみがこの変換テーブルに記録されます。
つまり、 ICI_MESH_SHAPE = [ici_data_parallelism, ici_fsdp_parallelism, ici_tensor_parallelism]およびDCN_MESH_SHAPE = [dcn_data_parallelism, dcn_fsdp_parallelism, dcn_tensor_parallelism]
| パックス C4Spmd22BAdam2xv4_128 | MaxText 2xv4-128.sh | (スケール適用後) | ||
|---|---|---|---|---|
| スケール (次の 4 つの変数に適用) | 3 | |||
| NUM_LAYERS | 48 | Base_num_decoder_layers | 16 | 48 |
| MODEL_DIMS | 6144 | Base_emb_dim | 2048年 | 6144 |
| HIDDEN_DIMS | 24576 | MODEL_DIMS * 4 (=base_mlp_dim) | 8192 | 24576 |
| NUM_HEADS | 24 | Base_num_heads | 8 | 24 |
| DIMS_PER_HEAD | 256 | 頭暗 | 256 | |
| PERCORE_BATCH_SIZE | 16 | per_device_batch_size | 16 | |
| MAX_SEQ_LEN | 1024 | max_target_length | 1024 | |
| VOCAB_SIZE | 32768 | 語彙サイズ | 32768 | |
| FPROP_DTYPE | jnp.bfloat16 | dtype | bfloat16 | |
| USE_REPEATED_LAYER | 真実 | |||
| SUMMARY_INTERVAL_STEPS | 10 | |||
| ICI_MESH_SHAPE | [1、64、1] | ici_fsdp_Parallelism | 64 | |
| DCN_MESH_SHAPE | [2、1、1] | dcn_data_Parallelism | 2 |
Input は、トレーニング/評価/デコードのためにモデルにデータを取得するためのBaseInputクラスのインスタンスです。
class BaseInput :
def get_next ( self ):
pass
def reset ( self ):
passこれは反復子のように動作します。 get_next() NestedMap返します。ここで、各フィールドは先頭の次元がバッチ サイズである数値配列です。
各入力はBaseInput.HParamsのサブクラスによって構成されます。このページでは、 p使用してBaseInput.Paramsのインスタンスを示し、それがinputにインスタンス化されます。
Pax では、データは常にマルチホストです。各 Jax プロセスには、個別の独立したinputがインスタンス化されます。それらのパラメータには、Pax によって自動的に設定される異なるp.infeed_host_indexが含まれます。
したがって、各ホストで見られるローカル バッチ サイズはp.batch_size 、グローバル バッチ サイズは(p.batch_size * p.num_infeed_hosts)です。 p.batch_size jax.local_device_count() * PERCORE_BATCH_SIZEに設定されていることがよくあります。
このマルチホストの性質により、 input適切にシャーディングされる必要があります。
トレーニングの場合、各input同一のバッチを出力してはなりません。また、有限データセットの評価の場合、各input同じ数のバッチの後に終了する必要があります。最善の解決策は、異なるホスト上の各input重複しないように、入力実装でデータを適切にシャード化することです。それができない場合は、別のランダム シードを使用して、トレーニング中のバッチの重複を避けることもできます。
input.reset()はトレーニング データに対して呼び出されることはありませんが、データの評価 (またはデコード) に対しては呼び出されます。
各評価 (またはデコード) の実行ごとに、Pax はinput.get_next()をN回呼び出して、 inputからNのバッチをフェッチします。使用されるバッチの数Nは、 p.eval_loop_num_batches介してユーザーが指定した固定数にすることができます。またはN動的にすることができます ( p.eval_loop_num_batches=None )。つまり、( StopIterationまたはtf.errors.OutOfRangeを呼び出すことによって) すべてのデータを使い果たすまでinput.get_next()を呼び出します。
p.reset_for_eval=Trueの場合、 p.eval_loop_num_batchesは無視され、データを使い果たすバッチの数としてNが動的に決定されます。この場合、 p.repeat False に設定する必要があります。そうしないと、デコード/評価が無限に行われることになります。
p.reset_for_eval=Falseの場合、Pax はp.eval_loop_num_batchesバッチをフェッチします。データが早期に枯渇しないように、これはp.repeat=Trueで設定する必要があります。
LingvoEvalAdaptor 入力にはp.reset_for_eval=Trueが必要であることに注意してください。
N : 静的 | N : 動的 | |
|---|---|---|
p.reset_for_eval=True | 各評価実行では、 | 評価実行ごとに 1 エポック。 |
: : 最初のNバッチ。そうでない: eval_loop_num_batches : | ||
| : : まだサポートされています。 : は無視されます。必ず入力してください: | ||
| : : : 有限であること : | ||
: : : ( p.repeat=False ) : | ||
p.reset_for_eval=False | 各評価実行では次を使用します。 | サポートされていません。 |
: : 重複しないN : : | ||
| : : ローリング上のバッチ : : | ||
| : : に基づいて、: : | ||
: : eval_loop_num_batches : : | ||
| : : 。入力は繰り返す必要があります: : | ||
| : : 無期限 : : | ||
: : ( p.repeat=True ) または : : | ||
| : : それ以外の場合は : : が発生する可能性があります | ||
| : : 例外 : : |
正確に 1 つのエポックで decode/eval を実行する場合 (つまり、 p.reset_for_eval=Trueの場合)、入力は、まったく同じ数のバッチが生成された後、各シャードが同じステップで発生するようにシャーディングを正しく処理する必要があります。これは通常、入力で eval データをパディングする必要があることを意味します。これはSeqIOInputおよびLingvoEvalAdaptorによって自動的に行われます (詳細は以下を参照)。
大部分の入力では、データのバッチを取得するためにget_next()を呼び出すだけです。あるタイプの eval データはこれの例外であり、「メトリクスの計算方法」も入力オブジェクトでも定義されます。
これは、正規の eval ベンチマークを定義するSeqIOInputでのみサポートされます。具体的には、Pax は、SeqIO タスクで定義されているpredict_metric_fnsおよびscore_metric_fns()を使用して評価メトリクスを計算します (ただし、Pax は SeqIO エバリュエーターに直接依存しません)。
モデルがトレーニング/評価間で複数の入力を使用する場合、または事前トレーニング/微調整間で異なるトレーニング データを使用する場合、特に他のユーザーによって実装された異なる入力をインポートする場合、ユーザーは入力で使用されるトークナイザーが同一であることを確認する必要があります。
ユーザーは、 input.ids_to_strings()でいくつかの ID をデコードすることで、トークナイザーの健全性をチェックできます。
いくつかのバッチを調べてデータの健全性をチェックすることを常にお勧めします。ユーザーは colab でパラメータを簡単に再現し、データを検査できます。
p = ... # specify the intended input param
inp = p . Instantiate ()
b = inp . get_next ()
print ( b )通常、トレーニング データは固定ランダム シードを使用すべきではありません。これは、トレーニング ジョブがプリエンプトされると、トレーニング データの繰り返しが開始されるためです。特に、Lingvo 入力の場合、トレーニング データにp.input.file_random_seed = 0を設定することをお勧めします。
シャーディングが正しく処理されるかどうかをテストするには、ユーザーはp.num_infeed_hosts, p.infeed_host_indexに異なる値を手動で設定し、インスタンス化された入力が異なるバッチを出力するかどうかを確認できます。
Pax は、SeqIO、Lingvo、カスタムの 3 種類の入力をサポートします。
SeqIOInput使用してデータセットをインポートできます。
SeqIO 入力は、eval データの正しいシャーディングとパディングを自動的に処理します。
LingvoInputAdaptor使用してデータセットをインポートできます。
入力は Lingvo 実装に完全に委任され、シャーディングが自動的に処理される場合と処理されない場合があります。
固定のpacking_factorを使用する GenericInput ベースの Lingvo 入力実装の場合、 LingvoInputAdaptorNewBatchSize使用して内部 Lingvo 入力により大きなバッチ サイズを指定し、希望する (通常ははるかに小さい) バッチ サイズをp.batch_sizeに設定することをお勧めします。
eval データの場合は、 LingvoEvalAdaptor使用して、1 エポックにわたって eval を実行するためのシャーディングとパディングを処理することをお勧めします。
BaseInputのカスタム サブクラス。ユーザーは、通常はtf.dataまたは SeqIO を使用して独自のサブクラスを実装します。
ユーザーは既存の入力クラスを継承して、バッチの後処理のみをカスタマイズすることもできます。例えば:
class MyInput ( base_input . LingvoInputAdaptor ):
def get_next ( self ):
batch = super (). get_next ()
# modify batch: batch.new_field = ...
return batchハイパーパラメータは、モデルの定義と実験の構成の重要な部分です。
Python ツールとより適切に統合するために、Pax/Praxis はハイパーパラメーターに Python データクラス ベースの構成スタイルを使用します。
class Linear ( base_layer . BaseLayer ):
"""Linear layer without bias."""
class HParams ( BaseHParams ):
"""Associated hyperparams for this layer class.
Attributes:
input_dims: Depth of the input.
output_dims: Depth of the output.
"""
input_dims : int = 0
output_dims : int = 0HParams データクラスをネストすることもできます。以下の例では、linear_tpl 属性はネストされた Linear.HParams です。
class FeedForward ( base_layer . BaseLayer ):
"""Feedforward layer with activation."""
class HParams ( BaseHParams ):
"""Associated hyperparams for this layer class.
Attributes:
input_dims: Depth of the input.
output_dims: Depth of the output.
has_bias: Adds bias weights or not.
linear_tpl: Linear layer params.
activation_tpl: Activation layer params.
"""
input_dims : int = 0
output_dims : int = 0
has_bias : bool = True
linear_tpl : BaseHParams = sub_config_field ( Linear . HParams )
activation_tpl : activations . BaseActivation . HParams = sub_config_field (
ReLU . HParams )レイヤーは、トレーニング可能なパラメーターを含む任意の関数を表します。レイヤーには、他のレイヤーを子として含めることができます。レイヤーはモデルの重要な構成要素です。レイヤーは Flax nn.Module から継承します。
通常、レイヤーでは次の 2 つのメソッドが定義されます。
このメソッドは、トレーニング可能な重みと子レイヤーを作成します。
このメソッドは順伝播関数を定義し、入力に基づいて出力を計算します。さらに、fprop は概要を追加したり、補助損失を追跡したりする場合があります。
Fiddle は、ML アプリケーション用に設計されたオープンソースの Python ファースト構成ライブラリです。 Pax/Praxis は、Fiddle Config/Partial との相互運用性、および積極的なエラー チェックや共有パラメータなどの高度な機能をサポートしています。
fdl_config = Linear . HParams . config ( input_dims = 1 , output_dims = 1 )
# A typo.
fdl_config . input_dimz = 31337 # Raises an exception immediately to catch typos fast!
fdl_partial = Linear . HParams . partial ( input_dims = 1 )Fiddle を使用すると、レイヤーを共有するように設定できます (例: トレーニング可能な重みを共有して 1 回だけインスタンス化)。
モデルはネットワーク (通常はレイヤーのコレクション) のみを定義し、デコードなどのモデルと対話するためのインターフェイスを定義します。
基本モデルの例には次のものがあります。
タスクには、もう 1 つのモデルと学習者/オプティマイザーが含まれています。最も単純な Task サブクラスは、次の Hparams を必要とするSingleTaskです。
class HParams ( base_task . BaseTask . HParams ):
""" Task parameters .
Attributes :
name : Name of this task object , must be a valid identifier .
model : The underlying JAX model encapsulating all the layers .
train : HParams to control how this task should be trained .
metrics : A BaseMetrics aggregator class to determine how metrics are
computed .
loss_aggregator : A LossAggregator aggregator class to derermine how the
losses are aggregated ( e . g single or MultiLoss )
vn : HParams to control variational noise .| PyPIのバージョン | 専念 |
|---|---|
| 0.1.0 | 546370f5323ef8b27d38ddc32445d7d3d1e4da9a |
Copyright 2022 Google LLC
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
https://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.


