BabyGPT Build_GPT_From_Scratch
1.0.0
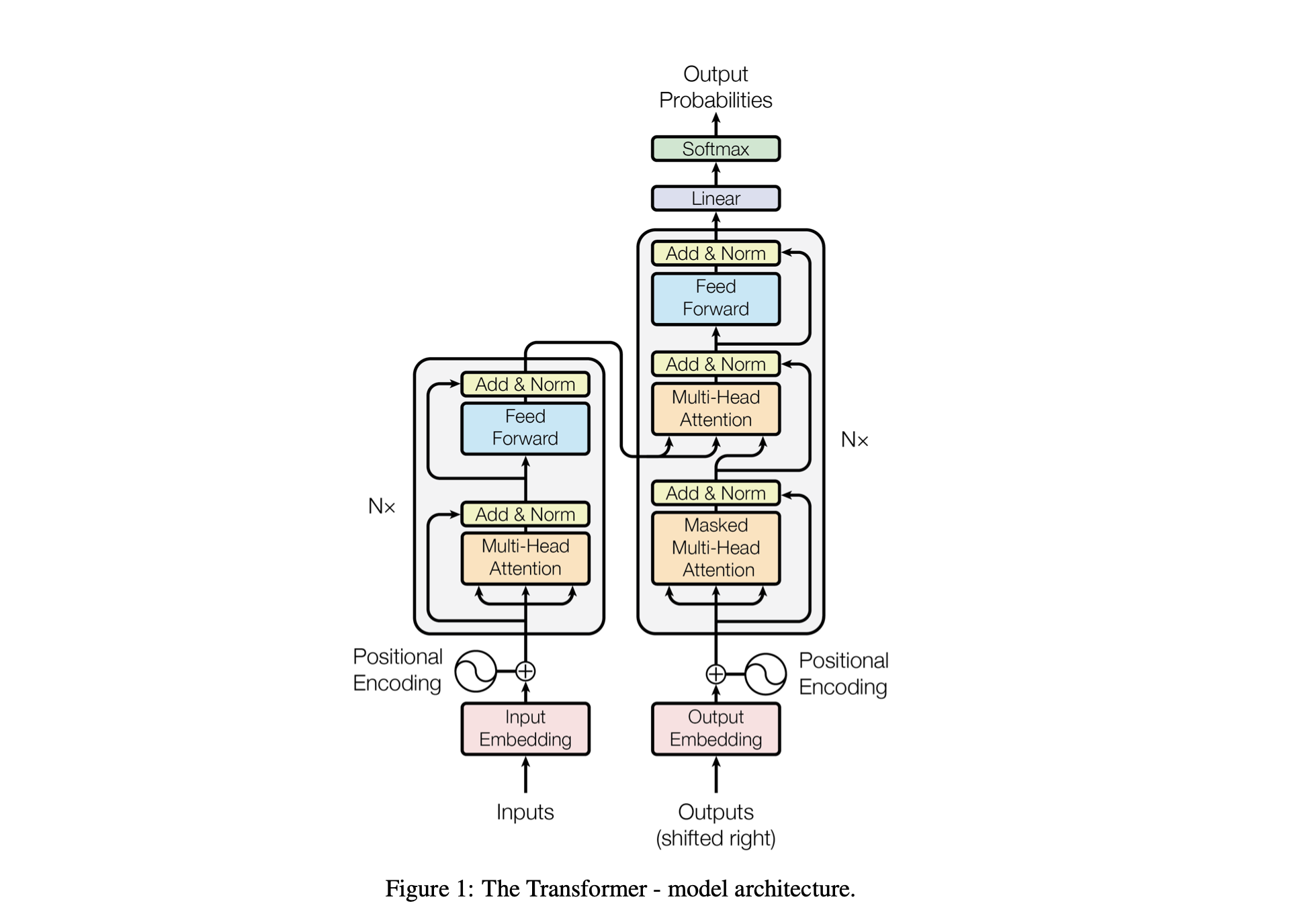
Baby GPT は、GPT のような言語モデルを段階的に構築するように設計された探索的なプロジェクトです。このプロジェクトは単純な Bigram モデルから始まり、Transformer モデル アーキテクチャの高度な概念を徐々に組み込んでいきます。
モデルのパフォーマンスは、次のハイパーパラメータを使用して調整されます。
batch_size : トレーニング中に並列処理されるシーケンスの数block_size : モデルによって処理されるシーケンスの長さd_model : モデル内の特徴の数 (埋め込みのサイズ)d_k : アテンション ヘッドごとの特徴の数。num_iter : モデルが実行するトレーニング反復の合計数Nx : モデル内のトランスフォーマー ブロックまたはレイヤーの数。eval_interval : モデルの損失が計算され評価される間隔lr_rate : Adam オプティマイザーの学習率device : 互換性のある GPU が利用可能な場合は自動的に'cuda'に設定され、それ以外の場合はデフォルトの'cpu'に設定されます。eval_iters : 評価損失を平均する反復回数h : マルチヘッド アテンション メカニズムにおけるアテンション ヘッドの数dropout_rate : 過学習を防ぐためにトレーニング中に使用されるドロップアウト率これらのハイパーパラメーターは、モデルが過学習せずにデータから学習し、計算リソースを効果的に管理する能力のバランスを取るために慎重に選択されました。
| ハイパーパラメータ | CPUモデル | GPUモデル |
|---|---|---|
device | 'CPU' | 利用可能な場合は「cuda」、利用できない場合は「cpu」 |
batch_size | 16 | 64 |
block_size | 8 | 256 |
num_iter | 10000 | 10000 |
eval_interval | 500 | 500 |
eval_iters | 100 | 200 |
d_model | 16 | 512 |
d_k | 4 | 16 |
Nx | 2 | 6 |
dropout_rate | 0.2 | 0.2 |
lr_rate | 0.005 (5e-3) | 0.001 (1e-3) |
h | 2 | 6 |
open('./GPT Series/input.txt', 'r', encoding = 'utf-8')chars_to_intおよびint_to_charsを使用して語彙辞書を作成します。encode関数を使用して文字列を整数に変換し、 decode関数を使用して整数に戻します。train_data ) セットと検証 ( valid_data ) セットに分割します。get_batch関数は、トレーニング用にデータをミニバッチで準備します。BigramLMクラスでモデル アーキテクチャを定義します。ミニバッチングは、トレーニング データを小さなバッチに分割する機械学習の手法です。各ミニバッチは、モデルのトレーニング中に個別に処理されます。このアプローチは次の点で役立ちます。
# Function to create mini-batches for training or validation.
def get_batch ( split ):
# Select data based on training or validation split.
data = train_data if split == "train" else valid_data
# Generate random start indices for data blocks, ensuring space for 'block_size' elements.
ix = torch . randint ( len ( data ) - block_size , ( batch_size ,))
# Create input (x) and target (y) sequences from data blocks.
x = torch . stack ([ data [ i : i + block_size ] for i in ix ])
y = torch . stack ([ data [ i + 1 : i + block_size + 1 ] for i in ix ])
# Move data to GPU if available for faster processing.
x , y = x . to ( device ), y . to ( device )
return x , y | 要素 | 小さなバッチサイズ | 大きなバッチサイズ |
|---|---|---|
| 勾配ノイズ | 高い(更新のばらつきが大きくなる) | 低い (より一貫性のある更新) |
| 収束 | より平坦な最小値を含む、より多くの解決策を模索する傾向がある | 多くの場合、より鮮明な最小値に収束します |
| 一般化 | より良い可能性があります (最小値がフラットになるため) | 悪化する可能性があります(最小値がより鋭いため) |
| バイアス | 低い (トレーニング データ パターンに過剰適合する可能性が低い) | 高い (トレーニング データ パターンに過剰適合する可能性がある) |
| 分散 | 高い (ソリューション空間での探索が増えるため) | 低い (ソリューション空間での探索が少ないため) |
| 計算コスト | エポックごとの増加 (より多くの更新) | エポックあたりの値が低い (更新が少ない) |
| メモリ使用量 | より低い | より高い |
estimate_loss関数は、指定された反復回数 (eval_iters) にわたるモデルの平均損失を計算します。これは、パラメーターに影響を与えることなくモデルのパフォーマンスを評価するために使用されます。一貫した損失計算を行うために、モデルは評価モードに設定され、ドロップアウトなどの特定のレイヤーが無効になります。トレーニング データと検証データの両方の平均損失を計算した後、モデルはトレーニング モードに戻ります。この機能は、トレーニングプロセスを監視し、必要に応じて調整を行うために不可欠です。
@ torch . no_grad () # Disables gradient calculation to save memory and computations
def estimate_loss ():
result = {} # Dictionary to store the results
model . eval () # Puts the model in evaluation mode
# Iterates over the data splits (training and validation)
for split in [ 'train' , 'valid_date' ]:
# Initializes a tensor to store the losses for each iteration
losses = torch . zeros ( eval_iters )
# Loops over the number of iterations to calculate the average loss
for e in range ( eval_iters ):
X , Y = get_batch ( split ) # Fetches a batch of data
logits , loss = model ( X , Y ) # Gets the model outputs and computes the loss
losses [ e ] = loss . item () # Records the loss for this iteration
# Stores the mean loss for the current split in the result dictionary
result [ split ] = losses . mean ()
model . train () # Sets the model back to training mode
return result # Returns the dictionary with the computed lossesPositional Encoding : BigramLMクラスのpositional_encodings_tableを使用してモデルに位置情報を追加します。トランスフォーマー アーキテクチャと同様に、文字の埋め込みに位置エンコーディングを追加します。
ここでは、PyTorch でニューラル ネットワーク モデルをトレーニングするために AdamW オプティマイザーをセットアップして使用します。 Adam オプティマイザーは、確率的勾配降下法の他の 2 つの拡張機能である AdaGrad と RMSProp の利点を組み合わせているため、多くの深層学習シナリオで好まれています。 Adam は各パラメータの適応学習率を計算します。 RMSProp のように過去の二乗勾配の指数関数的に減衰する平均を保存することに加えて、Adam は運動量と同様に、過去の勾配の指数関数的に減衰する平均も保持します。これにより、オプティマイザーはニューラル ネットワークの各重みの学習率を調整できるようになり、複雑なデータセットやアーキテクチャに対するより効果的なトレーニングにつながる可能性があります。
AdamW重みの減衰が最適化プロセスに組み込まれる方法を変更し、重みの減衰が勾配の更新から十分に分離されず、正則化の適用が最適にならないという元の Adam オプティマイザーの問題に対処します。 AdamW を使用すると、トレーニングのパフォーマンスが向上し、目に見えないデータが一般化される場合があります。私たちが AdamW を選択したのは、標準の Adam オプティマイザーよりも効果的に重み減衰を処理する能力があり、モデルのトレーニングと一般化の向上につながる可能性があるためです。
optimizer = torch . optim . AdamW ( model . parameters (), lr = lr_rate )
for iter in range ( num_iter ):
# estimating the loss for per X interval
if iter % eval_interval == 0 :
losses = estimate_loss ()
print ( f"step { iter } : train loss is { losses [ 'train' ]:.5f } and validation loss is { losses [ 'valid_date' ]:.5f } " )
# sampling a mini batch of data
xb , yb = get_batch ( "train" )
# Forward Pass
logits , loss = model ( xb , yb )
# Zeroing Gradients: Before computing the gradients, existing gradients are reset to zero. This is necessary because gradients accumulate by default in PyTorch.
optimizer . zero_grad ( set_to_none = True )
# Backward Pass or Backpropogation: Computing Gradients
loss . backward ()
# Updating the Model Parameters
optimizer . step ()セルフ アテンションは、モデルが入力データのさまざまな部分の重要性を異なる方法で重み付けできるようにするメカニズムです。これは Transformer アーキテクチャの重要なコンポーネントであり、モデルが入力シーケンスの関連部分に焦点を当てて予測できるようになります。
ドット積アテンション: クエリとキーの間のドット積に基づいて値の加重合計を計算する単純なアテンション メカニズム。
スケーリングされたドット積アテンション: キーの次元によってドット積をスケールダウンし、トレーニング中に勾配が小さくなりすぎるのを防ぐドット積アテンションの改良です。
OneHeadSelfAttendance : モデルが入力シーケンスのさまざまな位置に注意できるようにする単頭セルフ アテンション メカニズムの実装。 SelfAttentionクラスは、アテンション メカニズムの背後にある直感とそのスケーリング バージョンを示します。
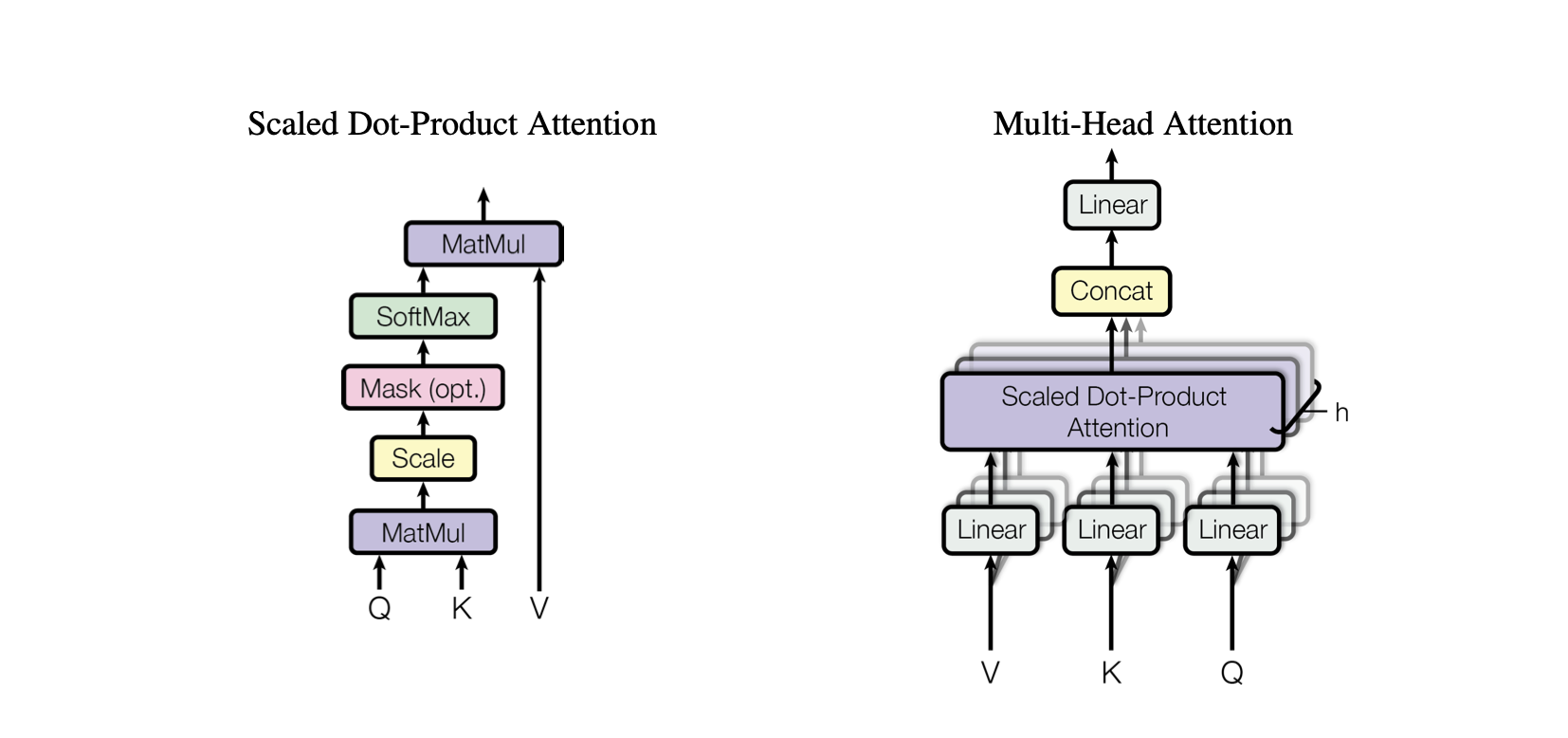
Baby GPT プロジェクトの対応する各モデルは、セルフ アテンション メカニズムの背後にある直観から始まり、ドット積およびスケーリングされたドット積アテンションの実践的な実装が続き、最終的に 1 つのアテンションの統合で頂点に達します。頭の自己注意モジュール。
class SelfAttention ( nn . Module ):
"""Self Attention (One Head)"""
""" d_k = C """
def __init__ ( self , d_k ):
super (). __init__ () #superclass initialization for proper torch functionality
# keys
self . keys = nn . Linear ( d_model , d_k , bias = False )
# queries
self . queries = nn . Linear ( d_model , d_k , bias = False )
# values
self . values = nn . Linear ( d_model , d_k , bias = False )
# buffer for the model
self . register_buffer ( 'tril' , torch . tril ( torch . ones ( block_size , block_size )))
def forward ( self , X ):
"""Computing Attention Matrix"""
B , T , C = X . shape
# Keys matrix K
K = self . keys ( X ) # (B, T, C)
# Query matrix Q
Q = self . queries ( X ) # (B, T, C)
# Scaled Dot Product
scaled_dot_product = Q @ K . transpose ( - 2 , - 1 ) * 1 / math . sqrt ( C ) # (B, T, T)
# Masking upper triangle
scaled_dot_product_masked = scaled_dot_product . masked_fill ( self . tril [: T , : T ] == 0 , float ( '-inf' ))
# SoftMax transformation
attention_matrix = F . softmax ( scaled_dot_product_masked , dim = - 1 ) # (B, T, T)
# Weighted Aggregation
V = self . values ( X ) # (B, T, C)
output = attention_matrix @ V # (B, T, C)
retur SelfAttentionクラスは、Transformer モデルの基本的な構成要素を表し、セルフ アテンション メカニズムを 1 つのヘッドでカプセル化します。そのコンポーネントとプロセスについての洞察は次のとおりです。
初期化: コンストラクター__init__(self, d_k)は、キー、クエリ、値の線形層をすべて次元d_kで初期化します。これらの線形変換は、後続のアテンション計算のために入力をさまざまな部分空間に投影します。
Buffers : self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size)))モデル パラメーターとはみなされない永続バッファーとして下三角行列を登録します。この行列は、各計算ステップで将来の位置が考慮されるのを防ぐためのアテンション メカニズムのマスキングに使用されます (デコーダのセルフ アテンションに役立ちます)。
Forward Pass : forward(self, X)メソッドは、セルフアテンション モジュールの呼び出しごとに実行される計算を定義します。
MultiHeadAttendant : MultiHeadAttentionクラスの複数のSelfAttentionヘッドからの出力を結合します。 MultiHeadAttendant クラスは、前のステップの 1 つのヘッドを備えたセルフ アテンション メカニズムの拡張実装ですが、現在は複数のアテンション ヘッドが並行して動作し、それぞれが入力の異なる部分に焦点を当てています。
class MultiHeadAttention ( nn . Module ):
"""Multi Head Self Attention"""
"""h: #heads"""
def __init__ ( self , h , d_k ):
super (). __init__ ()
# initializing the heads, we want h times attention heads wit size d_k
self . heads = nn . ModuleList ([ SelfAttention ( d_k ) for _ in range ( h )])
# adding linear layer to project the concatenated heads to the original dimension
self . projections = nn . Linear ( h * d_k , d_model )
# adding dropout layer
self . droupout = nn . Dropout ( dropout_rate )
def forward ( self , X ):
# running multiple self attention heads in parallel and concatinate them at channel dimension
combined_attentions = torch . cat ([ h ( X ) for h in self . heads ], dim = - 1 )
# projecting the concatenated heads to the original dimension
combined_attentions = self . projections ( combined_attentions )
# applying dropout
combined_attentions = self . droupout ( combined_attentions )
return combined_attentions
FeedForward : FeedForwardクラス内で ReLU アクティベーションを備えたフィードフォワード ニューラル ネットワークを実装します。オリジナルのトランス モデルと同様に、この完全に接続されたフィードフォワードをモデルに追加します。
class FeedForward ( nn . Module ):
"""FeedForward Layer with ReLU activation function"""
def __init__ ( self , d_model ):
super (). __init__ ()
self . net = nn . Sequential (
# 2 linear layers with ReLU activation function
nn . Linear ( d_model , 4 * d_model ),
nn . ReLU (),
nn . Linear ( 4 * d_model , d_model ),
nn . Dropout ( dropout_rate )
)
def forward ( self , X ):
# applying the feedforward layer
return self . net ( X ) TransformerBlocks : Blockクラスを使用してトランスフォーマー ブロックを積み重ねて、より深いネットワーク アーキテクチャを作成します。深さと複雑さ: ニューラル ネットワークでは、深さとはデータが処理される層の数を指します。追加の各レイヤー (Transformers の場合はブロック) により、ネットワークは入力データのより複雑で抽象的な特徴をキャプチャできるようになります。
逐次処理: 各 Transformer ブロックは、その前のブロックの出力を処理し、入力に対するより高度な理解を徐々に構築します。この逐次処理により、ネットワークはデータを深く階層的に表現できるようになります。変圧器ブロックのコンポーネント
# ---------------------------------- Blocks ----------------------------------#
class Block ( nn . Module ):
"""Multiple Blocks of Transformer"""
def __init__ ( self , d_model , h ):
super (). __init__ ()
d_k = d_model // h
# Layer 4: Adding Attention layer
self . attention_head = MultiHeadAttention ( h , d_k ) # h heads of d_k dimensional self-attention
# Layer 5: Feed Forward layer
self . feedforward = FeedForward ( d_model )
# Layer Normalization 1
self . ln1 = nn . LayerNorm ( d_model )
# Layer Normalization 2
self . ln2 = nn . LayerNorm ( d_model )
# Adding additional X for Residual Connections
def forward ( self , X ):
X = X + self . attention_head ( self . ln1 ( X ))
X = X + self . feedforward ( self . ln2 ( X ))
return XResidualConnections : Blockクラスを拡張して残留接続を含め、学習効率を向上させます。スキップ接続としても知られる残留接続は、ディープ ニューラル ネットワーク、特に Transformer モデルの設計における重要な革新です。これらは、ディープ ネットワークのトレーニングにおける主要な課題の 1 つである勾配消失問題に対処します。
# Adding additional X for Residual Connections
def forward ( self , X ):
X = X + self . attention_head ( self . ln1 ( X ))
X = X + self . feedforward ( self . ln2 ( X ))
return XLayerNorm : Blockクラスのnn.LayerNorm(d_model)を使用して、Transformer.Normalizing レイヤー出力にレイヤー正規化を追加します。
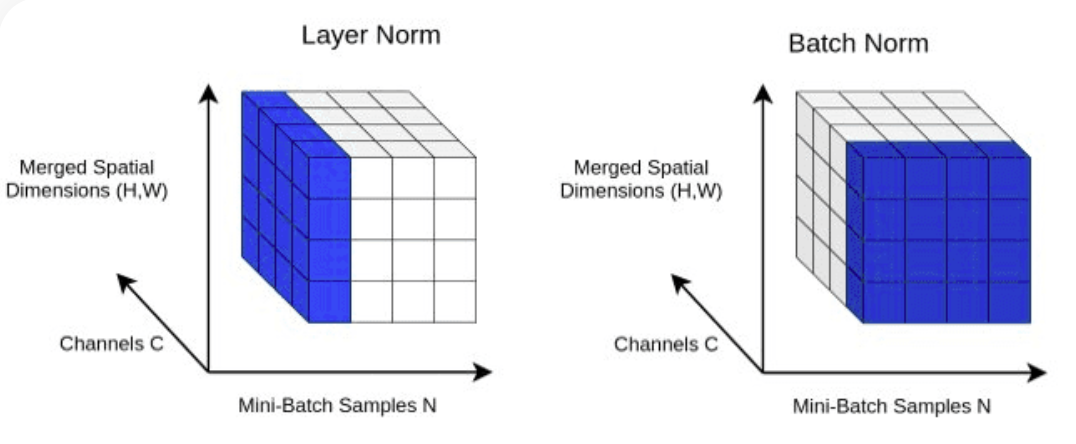
class LayerNorm :
def __init__ ( self , dim , eps = 1e-5 ):
self . eps = eps
self . gamma = torch . ones ( dim )
self . beta = torch . zeros ( dim )
def __call__ ( self , x ):
# orward pass calculaton
xmean = x . mean ( 1 , keepdim = True ) # layer mean
xvar = x . var ( 1 , keepdim = True ) # layer variance
xhat = ( x - xmean ) / torch . sqrt ( xvar + self . eps ) # normalize to unit variance
self . out = self . gamma * xhat + self . beta
return self . out
def parameters ( self ):
return [ self . gamma , self . beta ]Dropout : 過学習を防ぐための正則化方法としてSelfAttention層とFeedForward層に追加されます。ドロップアウトを以下に追加します。
ScaleUp : batch_size 、 block_size 、 d_model 、 d_k 、およびNxを拡張することにより、モデルの複雑さが増加します。この大きなモデルをトレーニングしてテストするには、NVIDIA GPU を搭載したマシンだけでなく CUDA ツールキットも必要です。
GPU アクセラレーションのために CUDA を試したい場合は、CUDA をサポートする適切なバージョンの PyTorch がインストールされていることを確認してください。
import torch
torch . cuda . is_available ()これを行うには、コマンド ラインのように、PyTorch インストール コマンドで CUDA バージョンを指定します。
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113