ke dialogue
1.0.0


これは論文の実装です:
タスク指向対話システムのパラメータを使用したナレッジベースの学習。 Andrea Madotto 、Samuel Cahyawijaya、Genta Indra Winata、Yan Xu、Zihan Liu、Zhaojiang Lin、Pascale Fung EMNLP 2020 の調査結果[PDF]
このツールキットに含まれるソース コードまたはデータセットを仕事で使用する場合は、次の論文を引用してください。ビブテックスは以下のとおりです。
@article{まどっと2020学習,
title={タスク指向対話システムのパラメータを使用したナレッジベースの学習},
author={マドット、アンドレアとチャヤウィジャヤ、サミュエルとウィナータ、ゲンタ インドラとシュー、ヤンとリウ、ジハンとリン、チャオジャンとフォン、パスカル}、
ジャーナル={arXiv プレプリント arXiv:2009.13656},
年={2020}
}
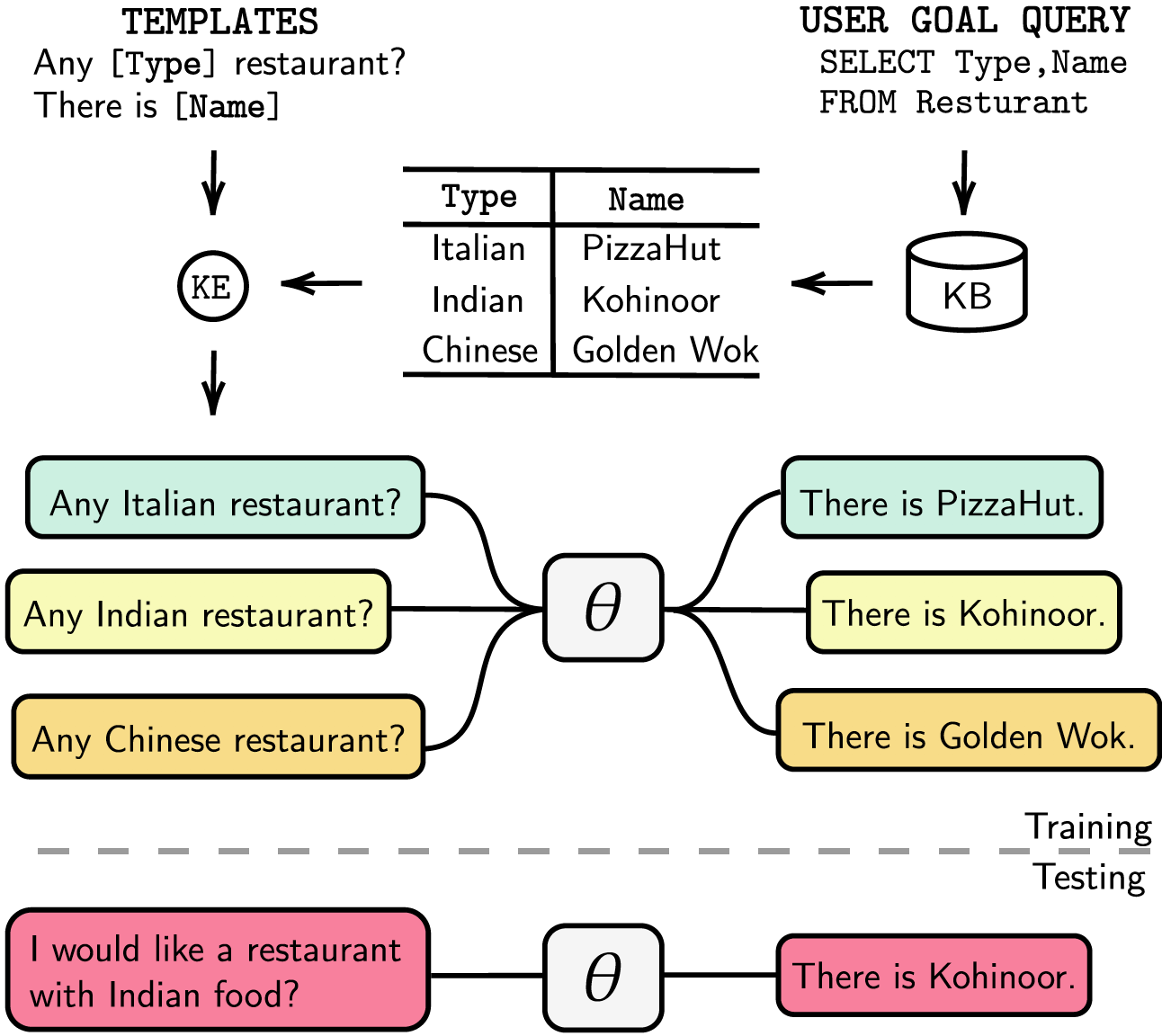
タスク指向の対話システムは、個別の対話状態追跡 (DST) および管理ステップを使用してモジュール化されているか、エンドツーエンドでトレーニング可能です。どちらの場合でも、ナレッジ ベース (KB) はユーザーの要求を満たす上で重要な役割を果たします。モジュール化されたシステムは、KB と対話するために DST に依存しますが、注釈と推論時間の点でコストがかかります。エンドツーエンド システムは KB を入力として直接使用しますが、KB が数百エントリを超えると拡張できません。この論文では、任意のサイズの KB をモデル パラメーターに直接埋め込む方法を提案します。結果として得られるモデルは、DST やテンプレートの応答、入力としての KB を必要とせず、微調整を通じて KB を動的に更新できます。私たちは、KB サイズが小、中、大の 5 つのタスク指向の対話データセットでソリューションを評価します。私たちの実験では、エンドツーエンドモデルがパラメータに知識ベースを効果的に埋め込み、評価されたすべてのデータセットで競争力のあるパフォーマンスを達成できることを示しています。
依存関係をrequirements.txtにリストしました。次を実行して依存関係をインストールできます。
❱❱❱ pip install -r requirements.txtさらに、コードにはapexによるfp16サポートも含まれています。パッケージは https://github.com/NVIDIA/apex から見つけることができます。
データセット前処理されたデータセットをダウンロードし、zip ファイルを./knowledge_embed/babi5フォルダー内に置きます。を実行してzipファイルを解凍します。
❱❱❱ cd ./knowledge_embed/babi5
❱❱❱ unzip dialog-bAbI-tasks.zipbAbI-5 データセットから非構造化されたダイアログを生成します。
❱❱❱ python3 generate_delexicalization_babi.pybAbI-5 データセットから語彙化されたデータを生成します。
❱❱❱ python generate_dialogues_babi5.py --dialogue_path ./dialog-bAbI-tasks/dialog-babi-task5trn_record-delex.txt --knowledge_path ./dialog-bAbI-tasks/dialog-babi-kb-all.txt --output_folder ./dialog-bAbI-tasks --num_augmented_knowledge <num_augmented_knowledge> --num_augmented_dialogue <num_augmented_dialogues> --random_seed 0ここで、最大<num_augmented_knowledge>は 558 (推奨)、 <num_augmented_dialogues>は 264 です。これは、bAbI-5 データセットの知識の数と対話の数に対応します。
GPT-2を微調整する
bAbIトレーニングセット上で微調整されたGPT-2モデルのチェックポイントを提供します。次のコマンドを使用して、モデルを自分でトレーニングすることも選択できます。
❱❱❱ cd ./modeling/babi5
❱❱❱ python main.py --model_checkpoint gpt2 --dataset BABI --dataset_path ../../knowledge_embed/babi5/dialog-bAbI-tasks --n_epochs <num_epoch> --kbpercentage <num_augmented_dialogues> --kbpercentageの値は、語彙化から得られる<num_augmented_dialogues>に等しいことに注意してください。このパラメーターは、トレイン データセットに埋め込む拡張ファイルを選択するために使用されます。
次のスクリプトを実行してモデルを評価できます。
❱❱❱ python evaluate.py --model_checkpoint <model_checkpoint_folder> --dataset BABI --dataset_path ../../knowledge_embed/babi5/dialog-bAbI-tasks bAbI-5 のスコアリングbAbI-5 タスク モデルのスコアラーを実行するには、次のコマンドを実行します。スコアラーは、 evaluate.pyから生成されたrunsフォルダーの下にあるすべてのresult.jsonを読み取ります。
python scorer_BABI5.py --model_checkpoint <model_checkpoint> --dataset BABI --dataset_path ../../knowledge_embed/babi5/dialog-bAbI-tasks --kbpercentage 0データセット
前処理されたデータセットをダウンロードし、zip ファイルを./knowledge_embed/camrestフォルダーに置きます。を実行してzipファイルを解凍します。
❱❱❱ cd ./knowledge_embed/camrest
❱❱❱ unzip CamRest.zipCamRest データセットから非論理化されたダイアログを生成します。
❱❱❱ python3 generate_delexicalization_CAMREST.pyCamRest データセットから語彙化されたデータを生成します。
❱❱❱ python generate_dialogues_CAMREST.py --dialogue_path ./CamRest/train_record-delex.txt --knowledge_path ./CamRest/KB.json --output_folder ./CamRest --num_augmented_knowledge <num_augmented_knowledge> --num_augmented_dialogue <num_augmented_dialogues> --random_seed 0 <num_augmented_knowledge>の最大値は 201 (推奨)、 <num_augmented_dialogues>は 156 で、CamRest データセット内の知識の数とダイアログの数に対応するため、非常に膨大です。
GPT-2を微調整する
CamRestトレーニングセット上で微調整されたGPT-2モデルのチェックポイントを提供します。次のコマンドを使用して、モデルを自分でトレーニングすることも選択できます。
❱❱❱ cd ./modeling/camrest/
❱❱❱ python main.py --model_checkpoint gpt2 --dataset CAMREST --dataset_path ../../knowledge_embed/camrest/CamRest --n_epochs <num_epoch> --kbpercentage <num_augmented_dialogues> --kbpercentageの値は、語彙化から得られる<num_augmented_dialogues>に等しいことに注意してください。このパラメーターは、トレイン データセットに埋め込む拡張ファイルを選択するために使用されます。
次のスクリプトを実行してモデルを評価できます。
❱❱❱ python evaluate.py --model_checkpoint <model_checkpoint_folder> --dataset CAMREST --dataset_path ../../knowledge_embed/camrest/CamRest CamRest のスコアリングbAbI 5 タスク モデルのスコアラーを実行するには、次のコマンドを実行します。スコアラーは、 evaluate.pyから生成されたrunsフォルダーの下にあるすべてのresult.jsonを読み取ります。
python scorer_CAMREST.py --model_checkpoint <model_checkpoint> --dataset CAMREST --dataset_path ../../knowledge_embed/camrest/CamRest --kbpercentage 0データセット
前処理されたデータセットをダウンロードし、 ./knowledge_embed/smd knowledge_embed/smd フォルダーの下に置きます。
❱❱❱ cd ./knowledge_embed/smd
❱❱❱ unzip SMD.zipGPT-2を微調整する
SMDトレーニングセット上で微調整されたGPT-2モデルのチェックポイントを提供します。チェックポイントをダウンロードし、 ./modelingフォルダーの下に置きます。
❱❱❱ cd ./knowledge_embed/smd
❱❱❱ mkdir ./runs
❱❱❱ unzip ./knowledge_embed/smd/SMD_gpt2_graph_False_adj_False_edge_False_unilm_False_flattenKB_False_historyL_1000000000_lr_6.25e-05_epoch_10_weighttie_False_kbpercentage_0_layer_12.zip -d ./runs次のコマンドを使用して、モデルを自分でトレーニングすることも選択できます。
❱❱❱ cd ./modeling/smd
❱❱❱ python main.py --dataset SMD --lr 6.25e-05 --n_epochs 10 --kbpercentage 0 --layers 12知識が組み込まれた対話を準備する
まず、SQL クエリ用のデータベースを構築する必要があります。
❱❱❱ cd ./knowledge_embed/smd
❱❱❱ python generate_dialogues_SMD.py --build_db --split test次に、ドメインごとに事前に設計されたテンプレートに基づいてダイアログを生成します。次のコマンドを使用すると、 weatherドメインでダイアログを生成できます。他の 2 つのドメインでダイアログを生成する場合は、 dialogue_pathおよびdomain引数のweather navigateまたはscheduleに置き換えてください。引数num_augmented_dialogueを変更することで、再解釈プロセスで使用されるテンプレートの数を変更することもできます。
❱❱❱ python generate_dialogues_SMD.py --split test --dialogue_path ./templates/weather_template.txt --domain weather --num_augmented_dialogue 100 --output_folder ./SMD/test微調整された GPT-2 モデルをテスト セットに適応させる
❱❱❱ python evaluate_finetune.py --dataset SMD --model_checkpoint runs/SMD_gpt2_graph_False_adj_False_edge_False_unilm_False_flattenKB_False_historyL_1000000000_lr_6.25e-05_epoch_10_weighttie_False_kbpercentage_0_layer_12 --top_k 1 --eval_indices 0,303 --filter_domain ""実験を並行して実行することで、微調整プロセスを高速化することもできます。コードの #L14 で GPU 設定を変更してください。
❱❱❱ python runner_expe_SMD.py データセット
前処理されたデータセットをダウンロードし、 ./knowledge_embed/mwoz knowledge_embed/mwoz フォルダーの下に置きます。
❱❱❱ cd ./knowledge_embed/mwoz
❱❱❱ unzip mwoz.zip知識が埋め込まれたダイアログを準備します (上記の zip ファイルをダウンロードした場合は、この手順をスキップできます)
次を実行してデータセットを準備できます。
❱❱❱ bash generate_MWOZ_all_data.shシェル スクリプトは、次の呼び出しによって MWOZ データセットから非論理化されたダイアログを生成します。
❱❱❱ python generate_delex_MWOZ_ATTRACTION.py
❱❱❱ python generate_delex_MWOZ_HOTEL.py
❱❱❱ python generate_delex_MWOZ_RESTAURANT.py
❱❱❱ python generate_delex_MWOZ_TRAIN.py
❱❱❱ python generate_redelex_augmented_MWOZ.py
❱❱❱ python generate_MWOZ_dataset.pyGPT-2を微調整する
MWOZトレーニングセット上で微調整されたGPT-2モデルのチェックポイントを提供します。チェックポイントをダウンロードし、 ./modelingフォルダーの下に置きます。
❱❱❱ cd ./knowledge_embed/mwoz
❱❱❱ mkdir ./runs
❱❱❱ unzip ./mwoz.zip -d ./runs次のコマンドを使用して、モデルを自分でトレーニングすることも選択できます。
❱❱❱ cd ./modeling/mwoz
❱❱❱ python main.py --model_checkpoint gpt2 --dataset MWOZ_SINGLE --max_history 50 --train_batch_size 6 --kbpercentage 100 --fp16 O2 --gradient_accumulation_steps 3 --balance_sampler --n_epochs 10はじめにグラフデータの処理にはneo4jコミュニティサーバーエディションとapocライブラリを使用します。 apocはneo4jでクエリを並列化するために使用され、大規模なグラフをより速く処理できるようになります。
データセットのセクションに進む前に、 neo4j (https://neo4j.com/download-center/#community) とapoc (https://neo4j.com/developer/neo4j-apoc/) がインストールされていることを確認する必要があります。あなたのシステム上で。
CYPHERおよびapoc構文に慣れていない場合は、 https://neo4j.com/developer/cypher/およびhttps://neo4j.com/blog/intro-user-defined-procedures-apoc/のチュートリアルに従ってください。
データセット元のデータセットをダウンロードし、zip ファイルを./knowledge_embed/opendialkgフォルダー内に置きます。を実行してzipファイルを解凍します。
❱❱❱ cd ./knowledge_embed/opendialkg
❱❱❱ unzip https://drive.google.com/file/d/1llH4-4-h39sALnkXmGR8R6090xotE0PE/view?usp=sharing.zipopendialkg データセットから非論理化されたダイアログを生成します (警告: この実行には約 12 時間かかります)
❱❱❱ python3 generate_delexicalization_DIALKG.pyこのスクリプトは、語彙化されたダイアログを生成するために使用される./opendialkg/dialogkg_train_meta.ptを生成します。その後、opendialkg データセットから語彙化されたダイアログを生成できます。
❱❱❱ python generate_dialogues_DIALKG.py --random_seed <random_seed> --batch_size 100 --max_iteration <max_iter> --stop_count <stop_count> --connection_string bolt://localhost:7687このスクリプトは、最大batch_size * max_iterサンプルのダイアログのサンプルを生成しますが、すべてのバッチで有効な候補が存在せず、サンプルが少なくなる可能性があります。生成数はstop_countと呼ばれる別の要因によって制限され、生成されたサンプルの数が指定されたstop_count超える場合に生成が停止されます。このファイルは、 ./opendialkg/db_count_records_{random_seed}.csv 、 ./opendialkg/used_count_records_{random_seed}.csv 、および./opendialkg/generation_iteration_{random_seed}.csvの 4 つのファイルを生成します。これらは、 DB内のカウント。生成されたサンプルを含む./opendialkg/generated_dialogue_bs100_rs{random_seed}.jsonです。
注:
generate_delexicalization_DIALKG.pyおよびgenerate_dialogues_DIALKG.py内のneo4jパスワードを手動で変更する必要があります。GPT-2を微調整する
opendialkgトレーニングセット上で微調整されたGPT-2モデルのチェックポイントを提供します。次のコマンドを使用して、モデルを自分でトレーニングすることも選択できます。
❱❱❱ cd ./modeling/opendialkg
❱❱❱ python main.py --dataset_path ../../knowledge_embed/opendialkg/opendialkg --model_checkpoint gpt2 --dataset DIALKG --n_epochs 50 --kbpercentage <random_seed> --train_batch_size 8 --valid_batch_size 8 --kbpercentageの値は、語彙化から得られる<random_seed>と等しいことに注意してください。このパラメーターは、トレイン データセットに埋め込む拡張ファイルを選択するために使用されます。
次のスクリプトを実行してモデルを評価できます。
❱❱❱ python evaluate.py --model_checkpoint <model_checkpoint_folder> --dataset DIALKG --dataset_path ../../knowledge_embed/opendialkg/opendialkg OpenDialKG のスコアリングbAbI-5 タスク モデルのスコアラーを実行するには、次のコマンドを実行します。スコアラーは、 evaluate.pyから生成されたrunsフォルダーの下にあるすべてのresult.jsonを読み取ります。
python scorer_DIALKG5.py --model_checkpoint <model_checkpoint> --dataset DIALKG ../../knowledge_embed/opendialkg/opendialkg --kbpercentage 0 実験、ハイパーパラメータ、および評価結果に関する詳細については、本論文および補足資料に記載されています。


