GGS
1.0.0
Greedy Gaussian Segmentation (GGS) は、多変量時系列データを効率的にセグメント化するための Python ソルバーです。実装の詳細については、http://stanford.edu/~boyd/papers/ggs.html の論文を参照してください。
GGS ソルバーは、n 行 T 列のデータ行列を取得し、n 次元ベクトル上の T タイムスタンプをセグメントに分割します。これらのセグメントでは、データが多変量ガウス分布からの独立したサンプルとして適切に説明されます。これは、共分散正規化された最尤問題を定式化し、欲張りヒューリスティックを使用してそれを解くことによって実現されます。詳細については論文で説明されています。
git clone [email protected]:davidhallac/GGS.git
cd GGS
python helloworld.py
ggs.py新しいファイルと同じディレクトリにあることを確認し、スクリプトの先頭に次のコードを追加します。 from ggs import *
GGS パッケージには 3 つの主な機能があります。
bps, objectives = GGS(data, Kmax, lamb)
指定された正規化パラメータ lambda のデータ内で K 個のブレークポイントを検索します
入力
data - n 次元ベクトルの T 個のタイムスタンプを持つ n 行 T 列のデータ行列
Kmax - 検索するブレークポイントの数
lamb - 正則化された共分散の正則化パラメータ
返品
bps - リストのリスト。大きい方のリストの要素iは、GGS アルゴリズムのK = iで見つかったブレークポイントのセットです。
objectives - 各中間ステップでの目標値のリスト ( K = 0 ~ Kmax の場合)
meancovs = GGSMeanCov(data, breakpoints, lamb)
一連のブレークポイントを指定して、各セグメントの平均と正規化された共分散を求めます。
入力
data - n 次元ベクトルの T 個のタイムスタンプを持つ n 行 T 列のデータ行列
ブレークポイント - ブレークポイントの場所のリスト
lamb - 正則化された共分散の正則化パラメータ
返品
meanscovs - データ内の各セグメントの (平均、共分散) タプルのリスト
cvResults = GGSCrossVal(data, Kmax=25, lambList = [0.1, 1, 10])
10 分割相互検証を実行し、Kmax までのすべての (K, ラムダ) ペアのトレーニング セットとテスト セットの尤度を返します。
入力
data - n 次元ベクトルの T 個のタイムスタンプを持つ n 行 T 列のデータ行列
Kmax - GGS を実行するブレークポイントの最大数
lambList - テストする正規化パラメータのリスト
返品
cvResults - lambList の各正則化パラメータの (lamb, ([TrainLL],[TestLL])) タプルのリスト。ここで、TrainLL と TestLL は、0 から Kmax までのすべてのKに対する 10 分割の相互検証にわたるサンプルごとの平均対数尤度です。
追加のオプションパラメータ (上記の 3 つの関数すべて):
features = [] - 操作するデータ内の列の特定のサブセットを選択します
verbose = False - アルゴリズムの実行時に中間ステップを出力します。
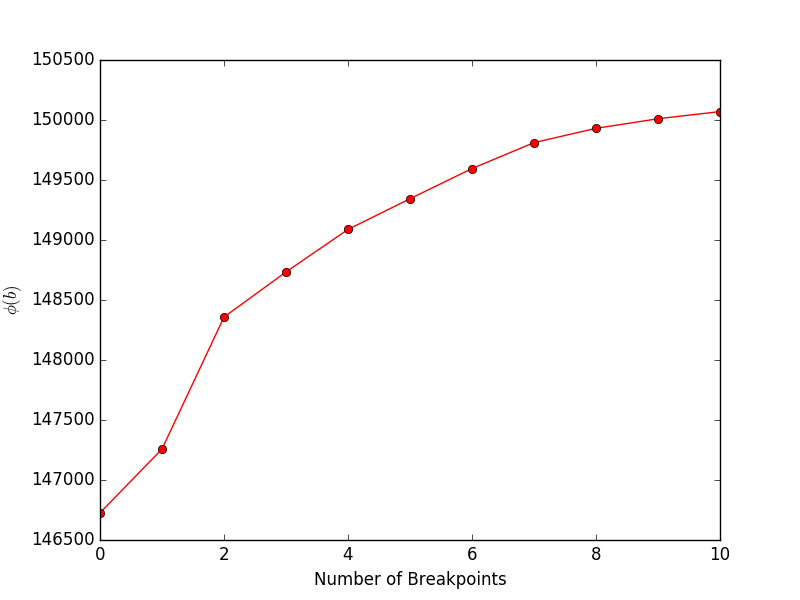
financeExample.pyを実行すると、目的 (論文の式 4) とブレークポイントの数を示す次のプロットが得られます。
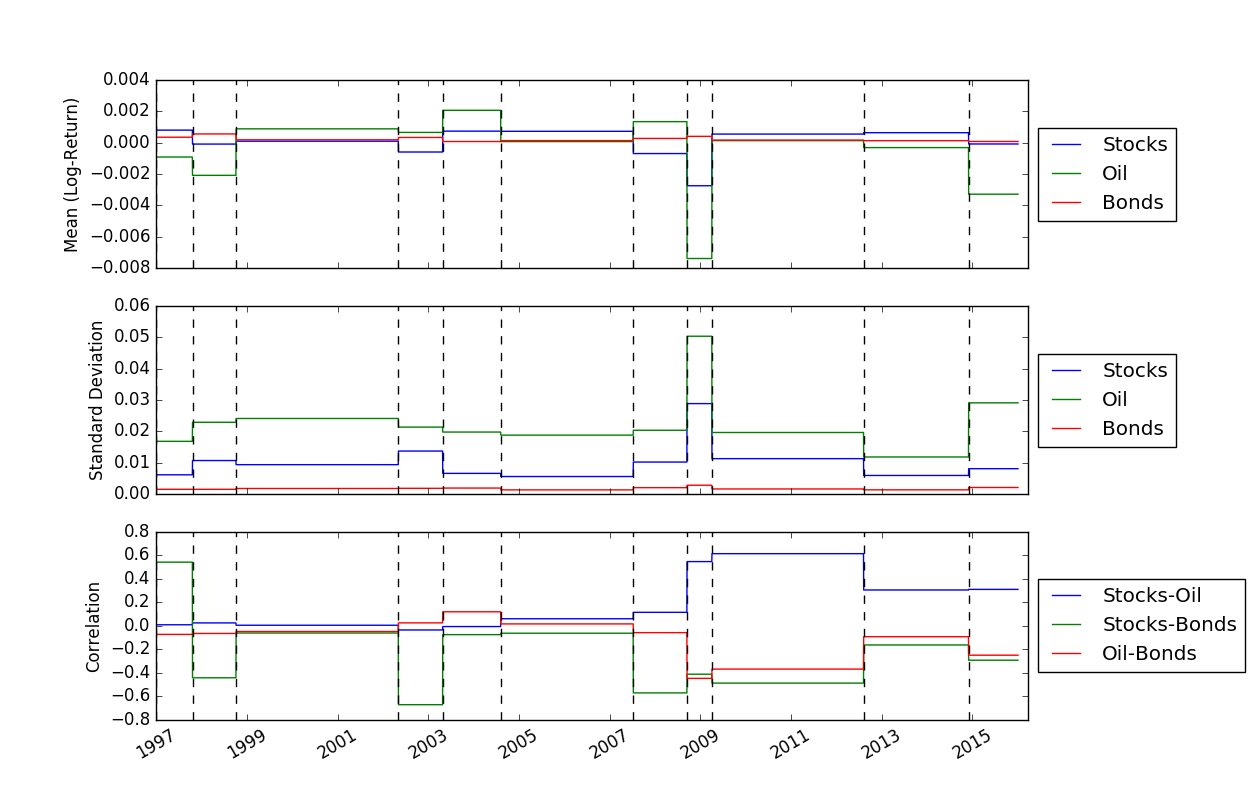
ブレークポイントの位置を解決したら、 FindMeanCovs()関数を使用して各セグメントの平均と共分散を見つけることができます。 helloworld.pyの例では、3 つの信号の平均、分散、共分散をプロットすると次のようになります。
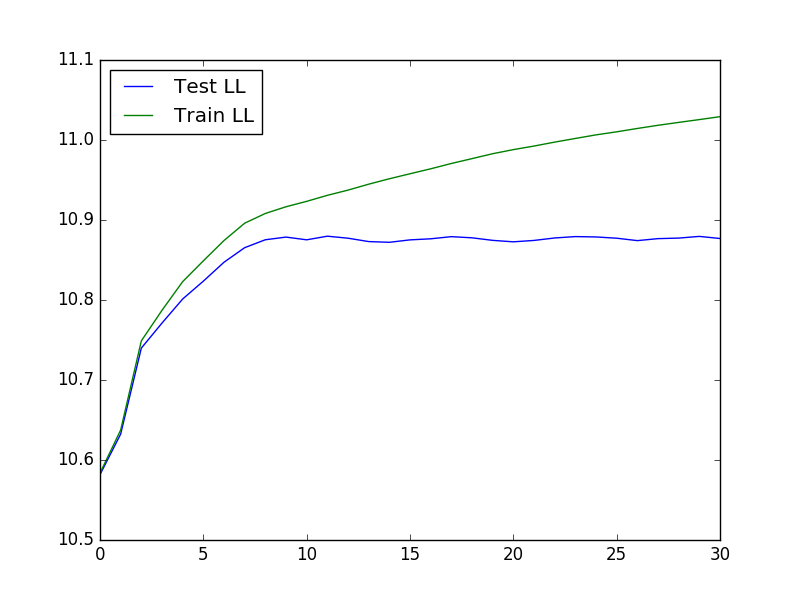
K とラムダの最適な値を決定する際に役立つ相互検証を実行するには、次のコードを使用してデータをロードし、相互検証を実行して、テストとトレーニングの尤度をプロットします。
from ggs import *
import numpy as np
import matplotlib.pyplot as plt
filename = "Returns.txt"
data = np.genfromtxt(filename,delimiter=' ')
feats = [0,3,7]
#Run cross-validaton up to Kmax = 30, at lambda = 1e-4
maxBreaks = 30
lls = GGSCrossVal(data, Kmax=maxBreaks, lambList = [1e-4], features = feats, verbose = False)
trainLikelihood = lls[0][1][0]
testLikelihood = lls[0][1][1]
plt.plot(range(maxBreaks+1), testLikelihood)
plt.plot(range(maxBreaks+1), trainLikelihood)
plt.legend(['Test LL','Train LL'], loc='best')
plt.show()
結果のプロットは次のようになります。
時系列データの貪欲なガウス セグメンテーション -- D. Hallac、P. Nystrup、S. Boyd
デビッド・ハラック、ピーター・ニストルプ、スティーブン・ボイド。


